c(mean(data), median(data), sd(data), var(data))[1] 1412.9167 1272.5000 636.4592 405080.2536STAT 205: Introduction to Mathematical Statistics
Exercise 1.1 Which of the following best describes the purpose of a confidence interval?
Exercise 2.1 When conducting a hypothesis test, what does a small p-value indicate?
Exercise 2.2 As part of an investigation from Union Carbide Corporation, the following data represent naturally occurring amounts of sulfate S04 (in parts per million) in well water. The data is from a random sample of 24 water wells in Northwest Texas.
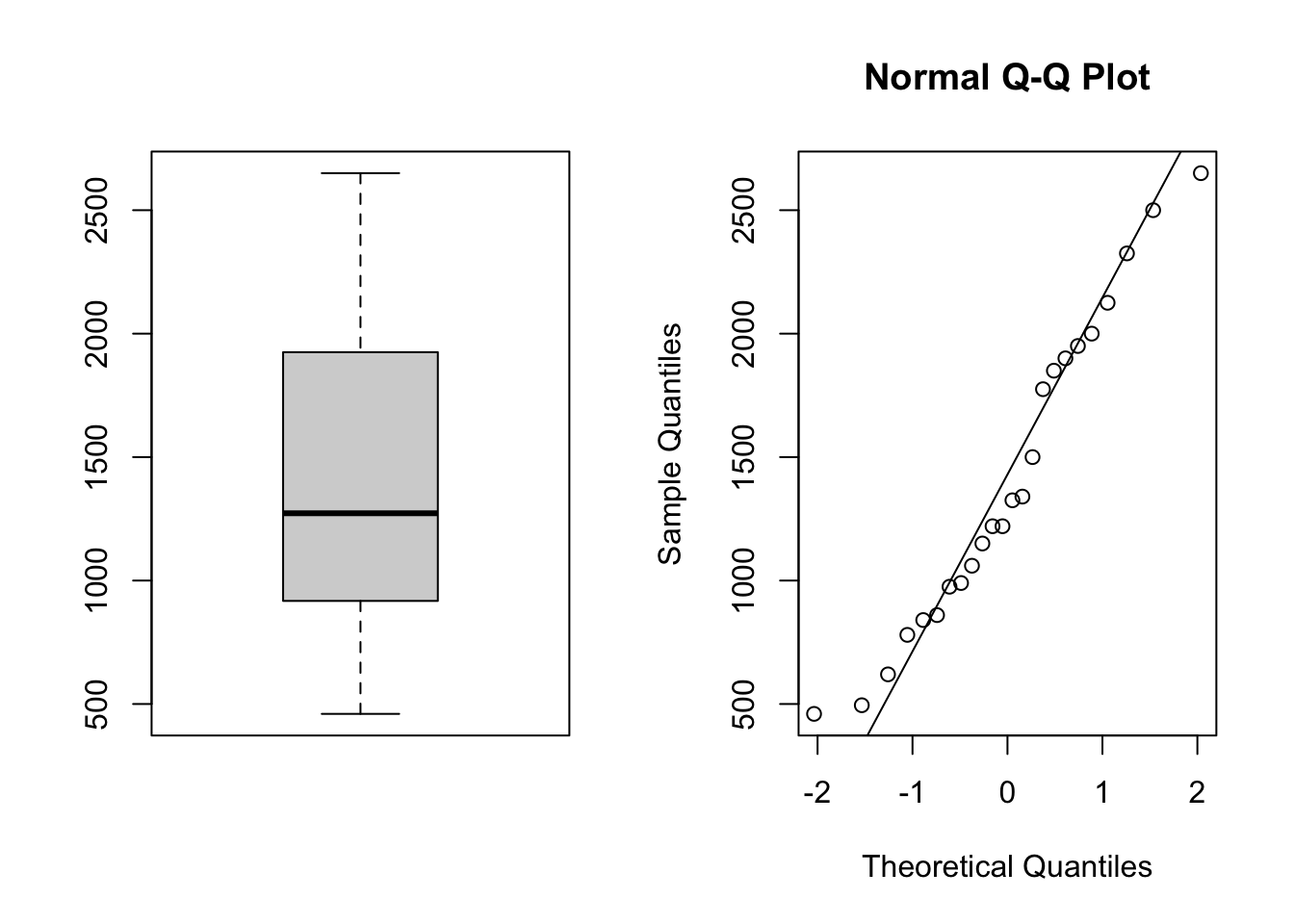
Based on the following summary statistics, estimate the standard error for \(\bar{X}\) (assume that the 24 observations are stored in a vector called data)
c(mean(data), median(data), sd(data), var(data))[1] 1412.9167 1272.5000 636.4592 405080.2536Exercise 2.3 In New York City on October 23rd, 2014, a doctor who had recently been treating Ebola patients in Guinea went to the hospital with a slight fever and was subsequently diagnosed with Ebola. Soon thereafter, an NBC 4 New York/The Wall Street Journal/Marist Poll found that 82% of New Yorkers favored a “mandatory 21-day quarantine for anyone who has come into contact with an Ebola patient.” This poll included responses from 1042 New York adults between October 26th and 28th, 2014.
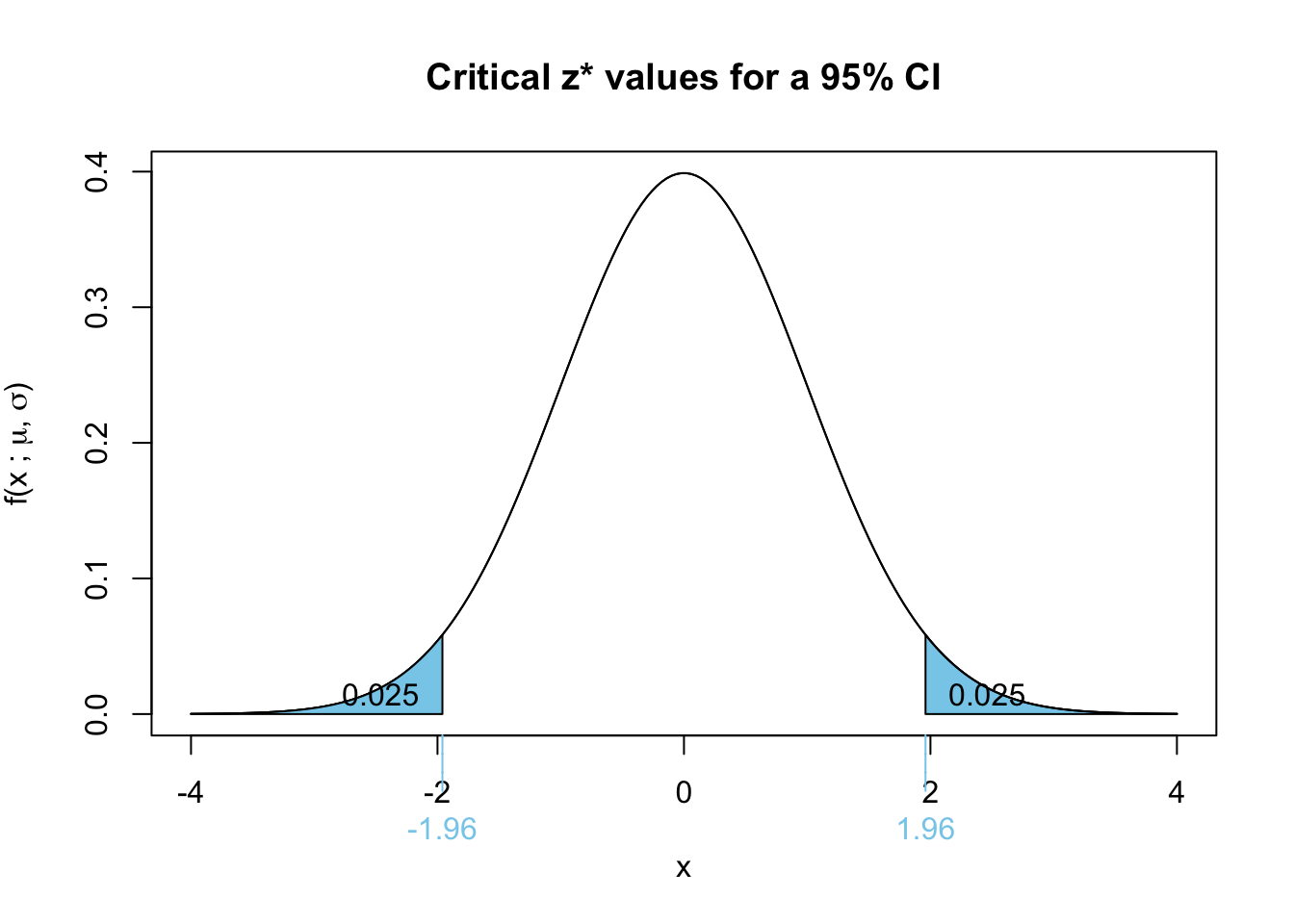
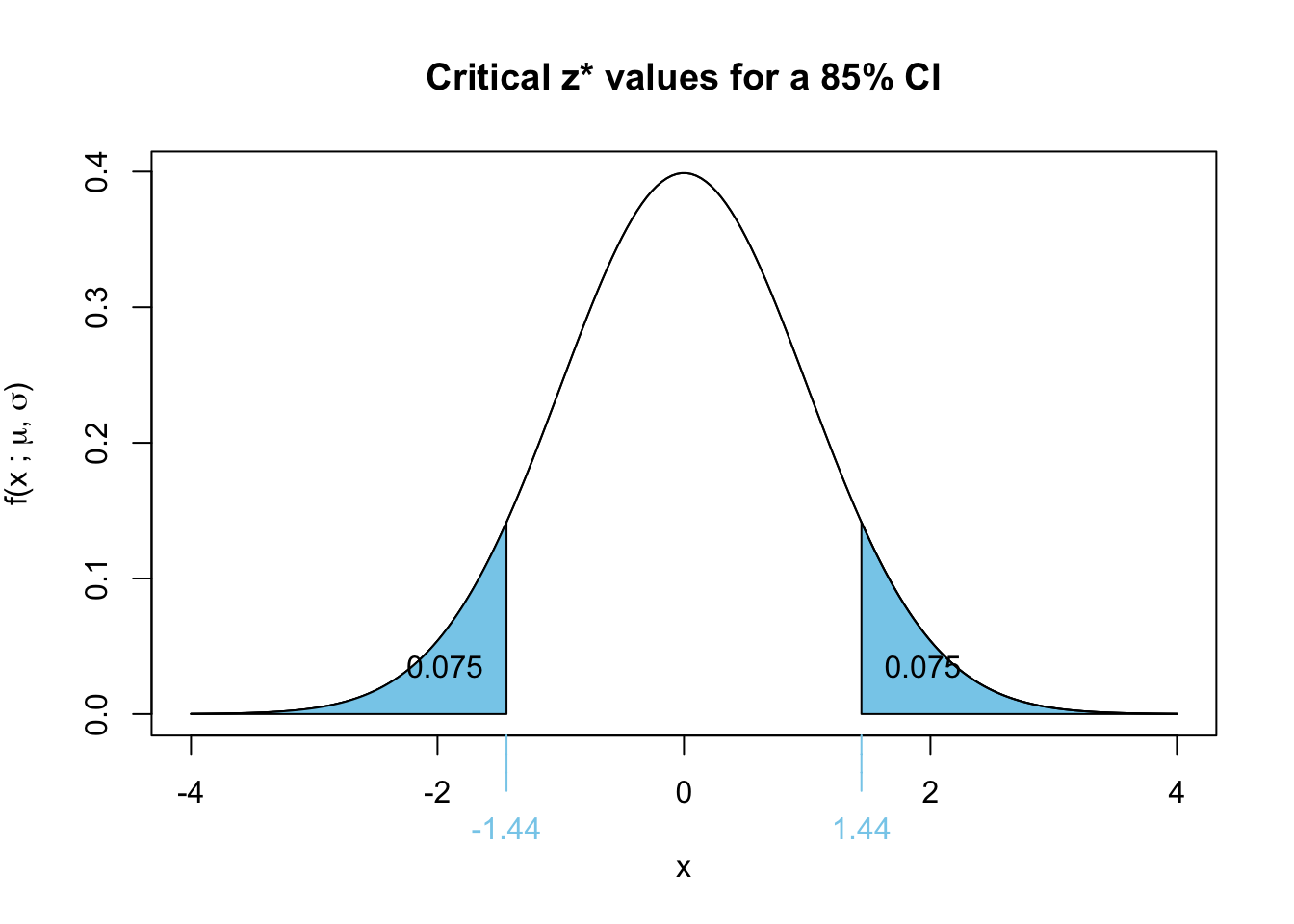
narrower
A lower confidence level corresponds to a smaller \(z^*\) value, which results in a narrower confidence interval.
Exercise 2.4 A basketball analyst claims that professional players hit free throws at an average rate of 75%. However, some argue that elite players perform better. To investigate, a random sample of 20 elite players was selected. Their individual free throw percentages are given below:
free_throw_perc <- c(84.9, 75.2, 79.8, 81.2, 80, 77.5, 85.6,
77.5, 88.1, 77.7, 84.5, 89.4, 71.1, 76.6,
77.3, 81.2, 76.6, 64.7, 65.8, 84.6)Rounding to 1 decmical place to simplify hand calculations, their mean free throw percentage was 79%, with a standard deviation of 6.6%.
Test whether the mean free throw percentage exceeds the league average of 75 percent.
Since there are less than 30 observations, the appropriate test is the one-sample t-test. Recall our flowchart for making this decision:

Since one-sample t-test relies on the following assumptions:
Histogram (Look for a roughly symmetric, bell-shaped distribution)
hist(free_throw_perc, breaks = 20)
⚠️ non-Symmetry: The distribution appears somewhat right-skewed, particularly in the second histogram. We should be weary of this assumption.
Q-Q Plot (Quantile-Quantile Plot): Compare sample quantiles to a theoretical normal distribution.
I like to use the qqPlot() function from the cars package since it provides some guiding confidence bands which makes it easy to detect deviations.
# Load necessary library
library(car)
# Generate Q-Q plot with confidence bands
qqPlot(free_throw_perc, main = "Q-Q Plot with Confidence Bands")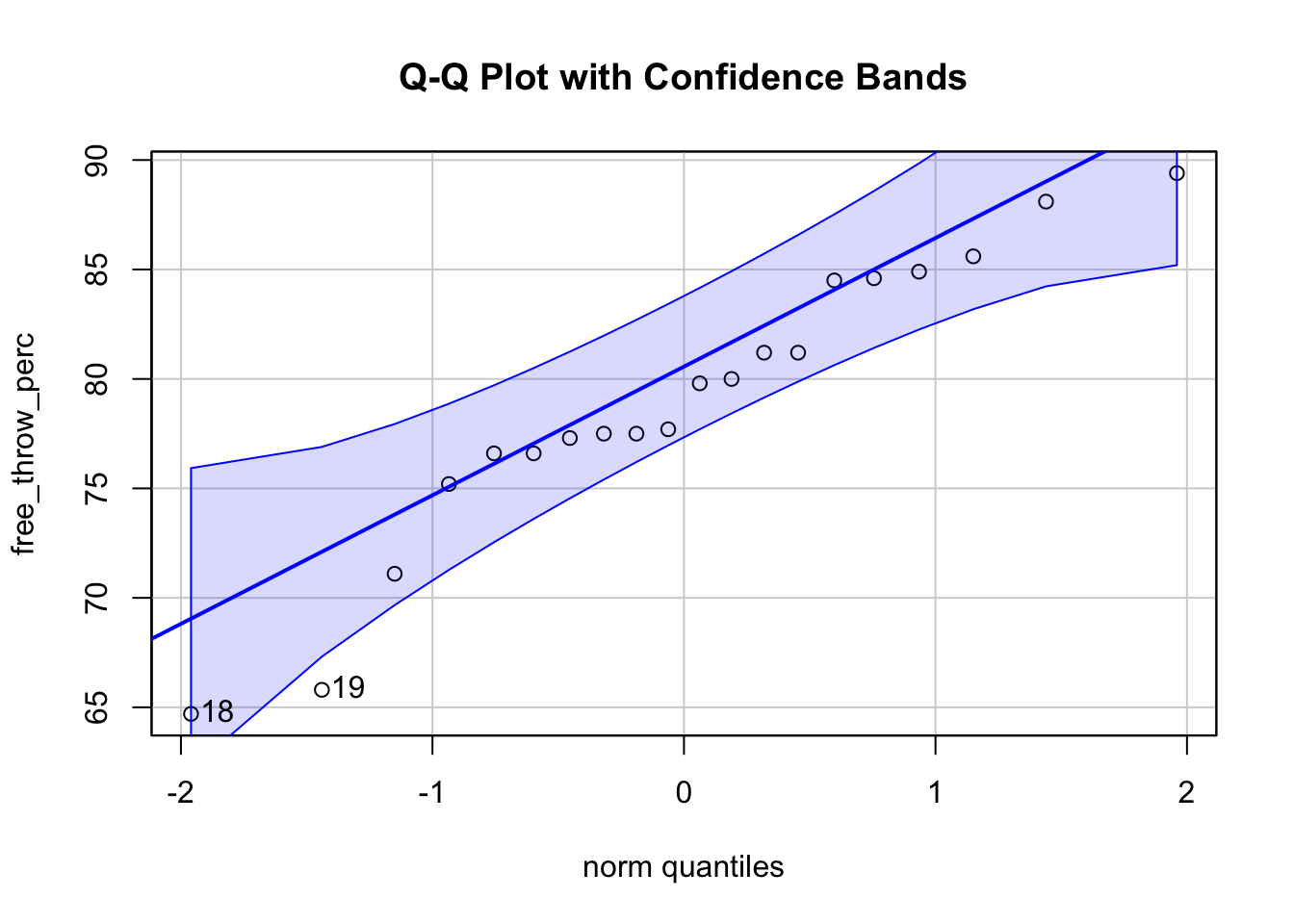
[1] 18 19The Q-Q plot with confidence bands shows that most points fall within the bands, indicating approximate normality. There is some deviation in the lower tail (left side) suggests a slight departure from normality, but it isn’t extreme. These correspond to observations (indices) outputted by qqPlot (i.e. observation 18 and 19) are considered potential outliers. That is to say, these are the two most extreme points that deviate from the normality assumption.
Summary:
✅ The Q-Q plot suggests that the data is roughly normal, though there are slight deviations at the lower end.
⚠️ Observations 18 and 19 are flagged as potential outliers, but they are not extreme enough to invalidate the normality assumption.
Shapiro-Wilk Test: A statistical test that checks for normality. If the p-value is greater than 0.05, we do not reject normality.
shapiro.test(free_throw_perc)
Shapiro-Wilk normality test
data: free_throw_perc
W = 0.94389, p-value = 0.2837\(H_0\) : The data follows a normal distribution.
\(H_A\) : The data does not follow a normal distribution.
p-value: 0.2837 \(> \alpha = 0.05\) \(\implies\) fail to reject
Conclusion: There is insufficient evidence against normality, and we can reasonably assume that the data is approximately normally distributed.
Hence we carry on with the one-sample \(t\)-test…
Decision:
Decide whether or not the reject \(H_0\) using the critical value method.
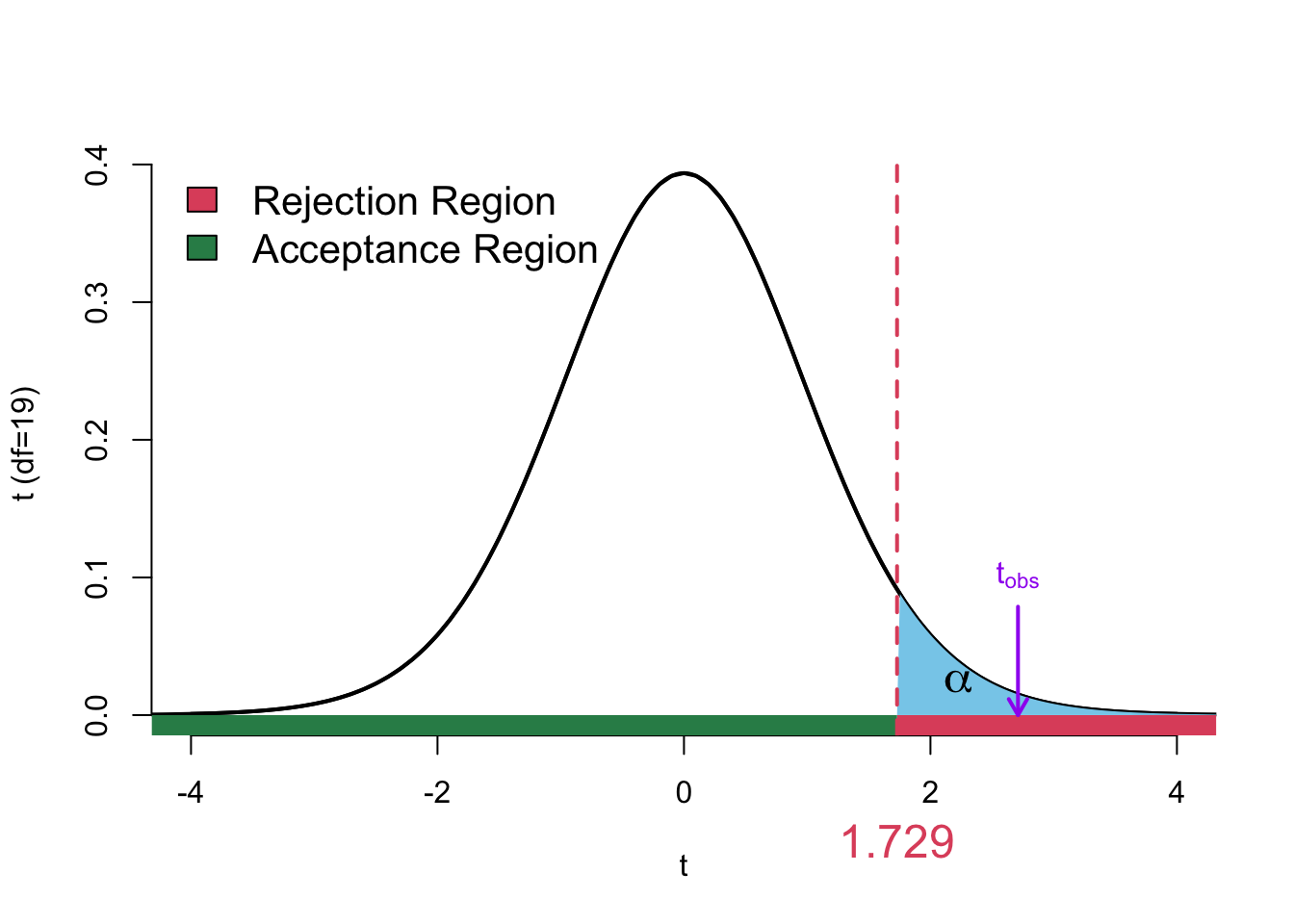
Critical Value Approach: to use the critical value approach we first need to find the critical values on the null distribution. Hence we need to find \(t^*\) such that
\[ \Pr(t_{\nu = 19} > t_\alpha^*) = \alpha \] Note that we don’t need to divide \(\alpha\) by two since we are doing the upper-tailed test. The critical value is visualized in Figure 2.3
Decide whether or not the reject \(H_0\) using the \(p\)-value approach (this should always agree with the critical value method).
p-value approach
We need to find
\[ \Pr(t_{\nu = 19} > 2.71) \]
Using the \(t\)-tables:
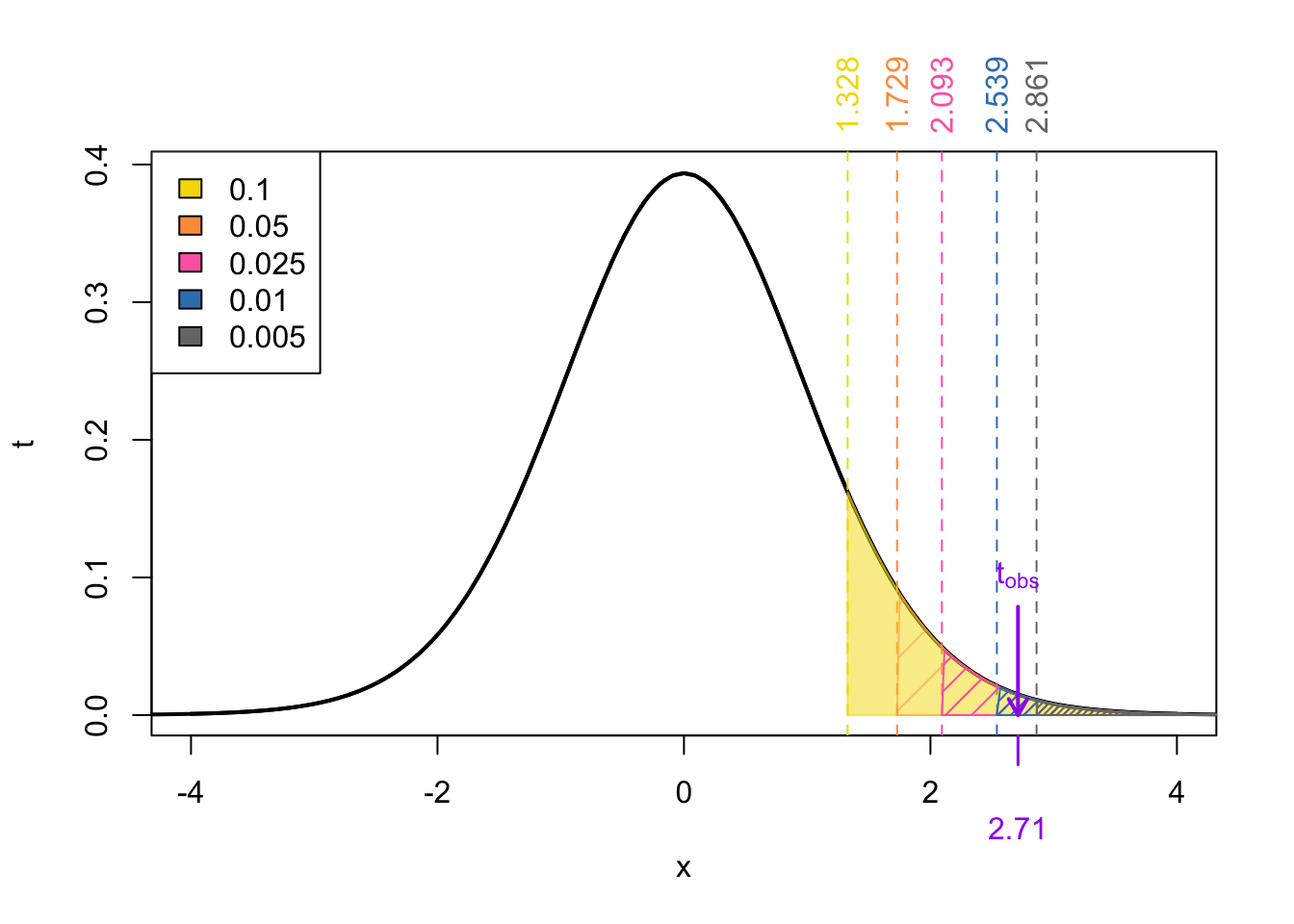
From the t-tables we can deduce that the \(p\)-value is
\[ \begin{align} \Pr(t_{\nu = 19} > 2.539) < &\Pr(t_{\nu = 19} > 2.7103854) < \Pr(t_{\nu = 19} > 2.861)\\ \text{area in RoyalBlue }< & p\text{-value} < \text{area in gray}\\ 0.01< & p\text{-value} < 0.005\\ \end{align} \]
Using R:
pt(2.7103854, df = 19, lower.tail = FALSE)[1] 0.006937378Since the \(p\)-value is less than the significance level of \(\alpha\) = 0.05 we reject the null hypothesis.
State the appropriate conclusion. Is there evidence that elite players perform better than the league average?
Exercise 3.1 Suppose we are about to sample 625 observations from a normally distributed population where it is known that \(\sigma = 100\), but \(\mu\) is unknown. We intend to test:
\[ \begin{align} H_0: \mu &= 500 & H_A: \mu &< 500 \end{align} \] at the \(\alpha = 0.05\) significance level.
(a) What values of the sample mean \(\bar{x}\) would lead to a rejection of the null hypothesis?
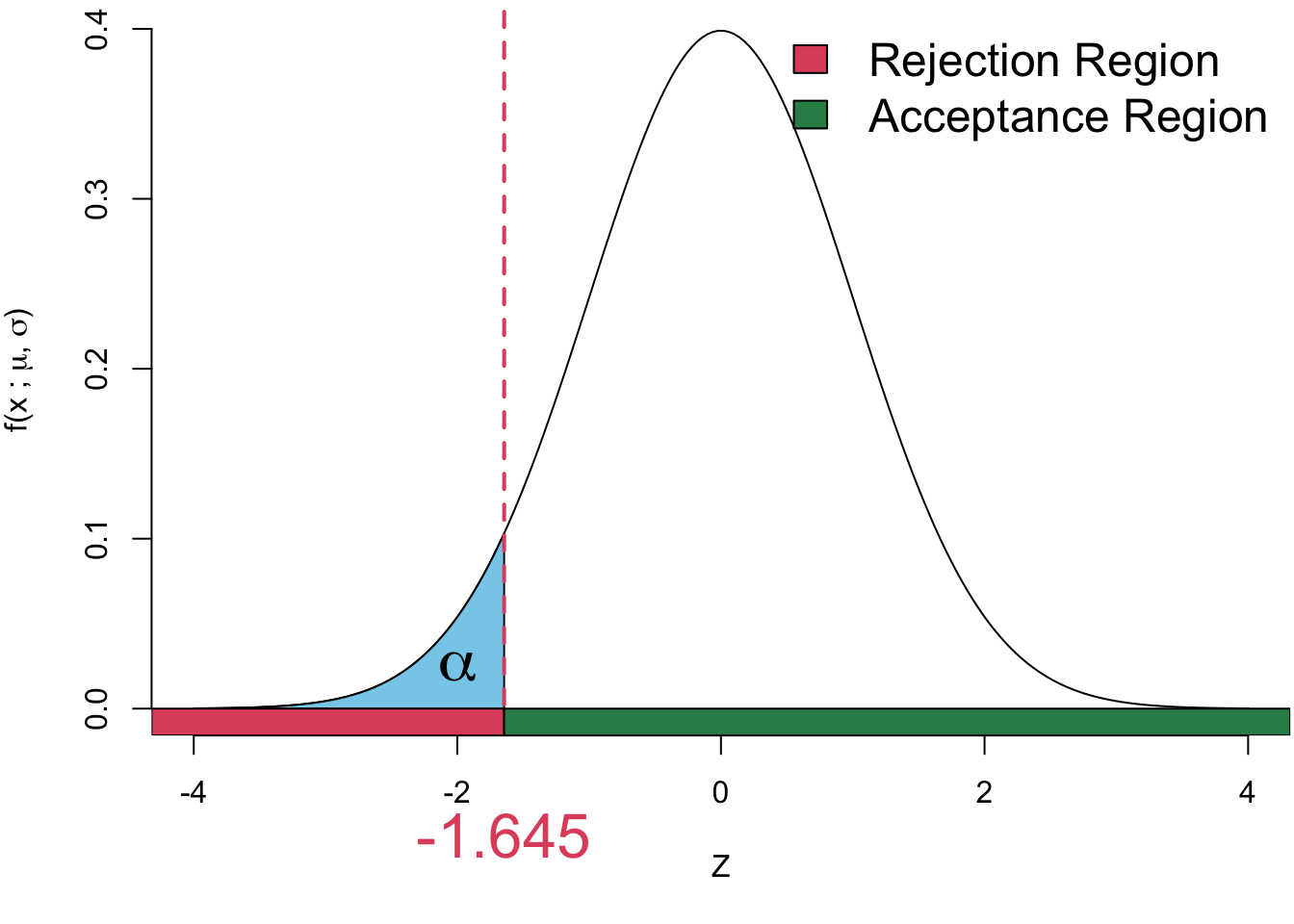
Since this is a left-tailed test, we reject \(H_0\) when the observed test statistic \(\frac{\bar x- \mu_0}{\sigma/\sqrt{n}}\) falls in the rejection region.
Equivalently, we reject the null when \(_\text{obs}\) < the critical value \(z^*\): value:
\[ \begin{align} \Pr(Z < z^*) = 0.05\\ \implies z^* = -1.645 \end{align} \]
Convert this to a cutoff for \(\bar{x}\) (which I will denote \(\bar{x}_{crit}\)), we solve:
\[ \begin{align} \text{reject when } z_\text{obs} &< z^*\\ \implies \frac{\bar{x}_{crit} - \mu_0}{\sigma/\sqrt{n}} &= z^*\\ \implies \bar{x}_{crit} &= \mu_0 + z^* \cdot \frac{\sigma}{\sqrt{n}} \\ &= 500 + (-1.645) \cdot \frac{5}{\sqrt{625}}\\ &= 493.42 \end{align} \]
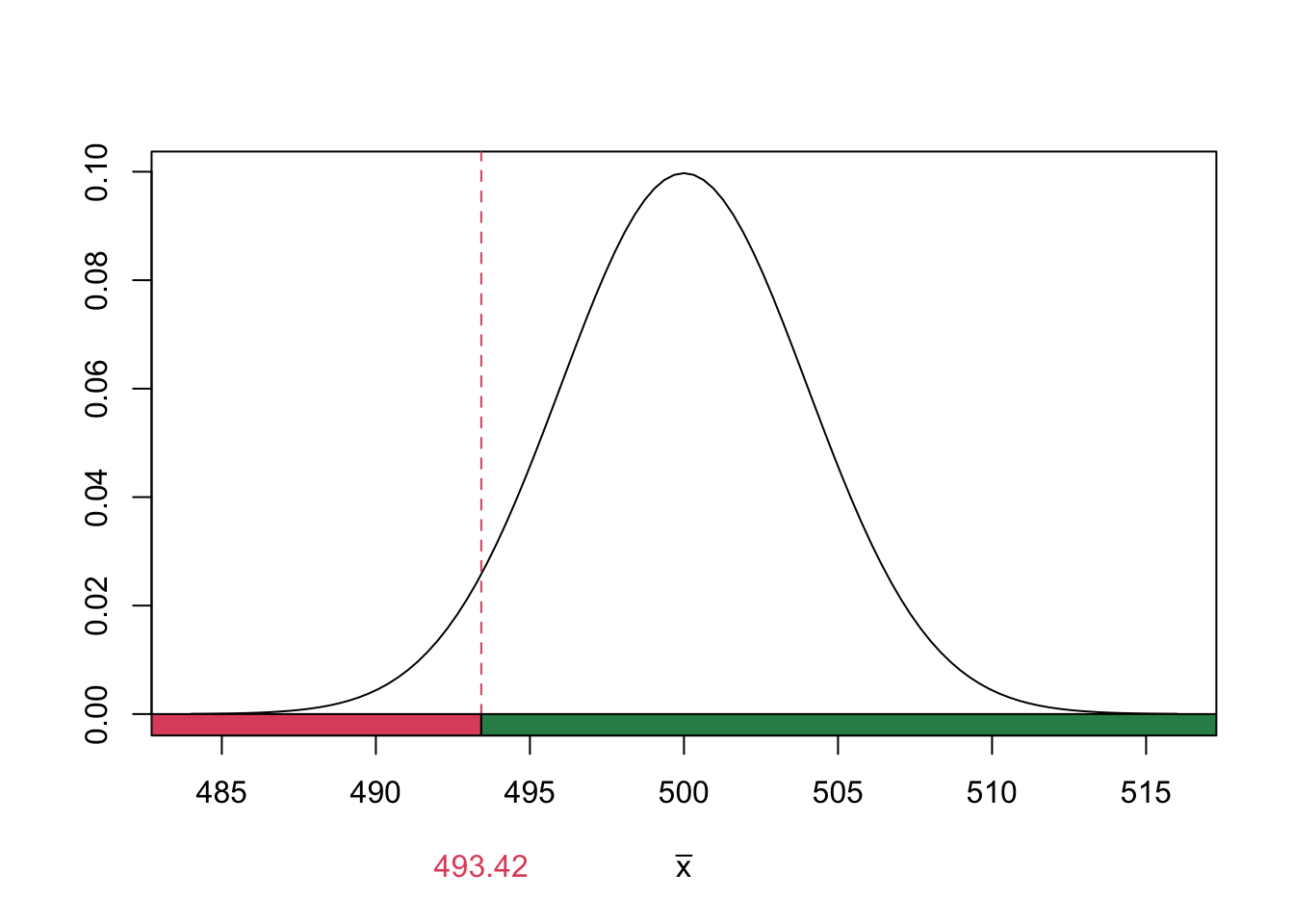
We reject the null hypothesis when \(\bar{x} < 493.42\).
(b) What is the power of the test if the true mean is \(\mu = 490\)?
We calculate the probability of rejecting \(H_0\) under the alternative \(\mu = 490\). Using the results from (a) and the alternative curve (plotted in orange); I will denot the rv associated with this sampling distribution \(\bar X_A\)
\[ \begin{align} \text{Power} &= \Pr(\text{reject }H_0 \mid H_A \text{ is true})\\ &= \Pr(\bar X_A < \bar x_{\text{crit}}) & \text{where }\textcolor{orange}{\bar X_A \sim N(\mu = 490, \sigma = 4)}\\ &= \Pr\left( \frac{\bar X_A - 490}{\sigma/\sqrt{n}} < \frac{493.42 - 490}{\sigma/\sqrt{n}} \right)\\ &= \Pr(Z < 0.8551464)\\ &= 0.8051 & \text{approximated from the Z-table} \end{align} \]
Finding the power exactly in R we could use:
pnorm(0.8551464)[1] 0.8037649Alternative, we could have found the probability without converting to the standard normal by using:
pnorm(493.4205855, mean = 490, sd = 4)[1] 0.8037649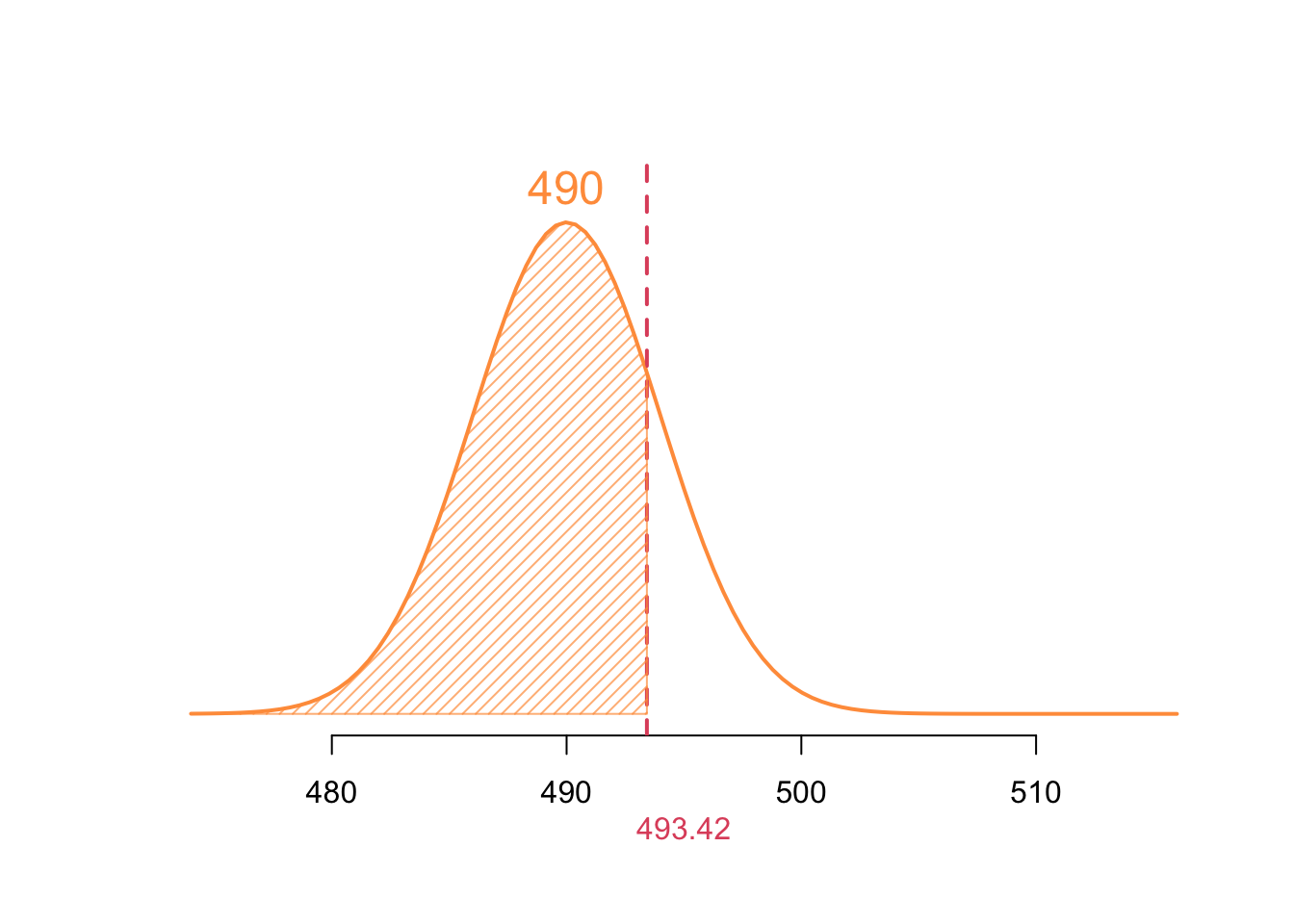
(c) What is the Type II error if the true mean is \(\mu = 490\)?
Exercise 4.1 Offerman et al. (2009) conducted an experiment on pigs to investigate the effect of an antivenom after an injection of rattlesnake venom. In one aspect of the study, the researchers investigated the change in volume of the right hind leg before and after being subjected to a dose of venom and treatment with an antivenom. The volume of the right hind leg was measured in 9 pigs before being injected with the venom, then the pigs were injected with a dose of venom and treated intravenously with an antivenom, and after 8 hours the volume of the leg was measured again. The results are illustrated in Table 10.5. (The volume was measured using a water displacement method; the units are mL.)
alpha <- 0.05
diffs <- before - after
n <- length(before)Exercise 4.2 A fitness coach wants to evaluate the effectiveness of a new treadmill training program on reducing runners’ 5K race times. A sample of r n athletes is timed before and after completing the program:
Times (in seconds) before: 212, 198, 225, 210, 202, 230, 220, 205, 215, 208
Times (in seconds) after: 202, 190, 219, 200, 195, 222, 210, 200, 207, 202
At the 5% significance level, is there evidence that the program reduces 5K run times on average?
(a) What type of test is appropriate for this situation?
(b) State the hypotheses.
(c) Compute the test statistic by hand.
(d) Calculate the p-value i) approximate using the \(t\)-tables ii) exactly using R.
We need to refer to the \(t\)-table with \(\nu = n-1 = 10 -1 = 9\). There reference row is depicted below:
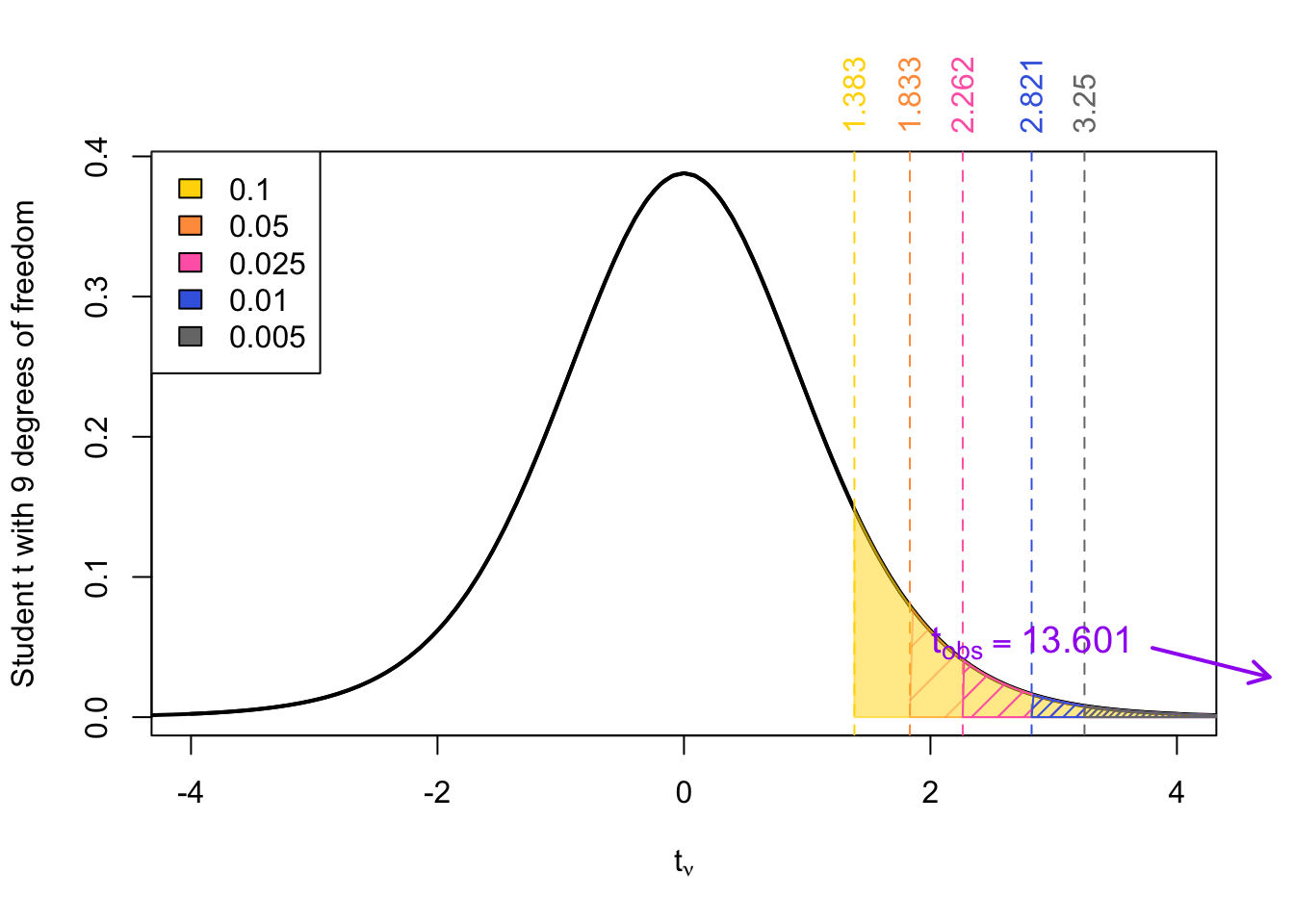
With an observed test statistic of 13.601, the \(p\)-value is approximated as:
\[ \begin{align} p\text{-value} &= \Pr(t_{9} > t_\text{obs} ) \\ &= \Pr(t_{9} > 13.6) \\ & < \Pr(t_{9} > \textcolor{gray}{3.25}) = \textcolor{gray}{0.005} \\ \implies p\text{-value} &< \textcolor{gray}{0.005} \end{align} \]
The null distribution is a Student \(t\) with degrees of freedom: \(df = n - 1 = 9\). The exact \(p\)-value is calculated using:
pt(13.601, df = 9, lower.tail = FALSE)[1] 1.316055e-07The relationship between the exact \(p\)-value and the relant reference \(t\)-values is shown below. As we can see,
\[ p\text{-value} = 0.0000001316055 < \textcolor{gray}{0.005} \]
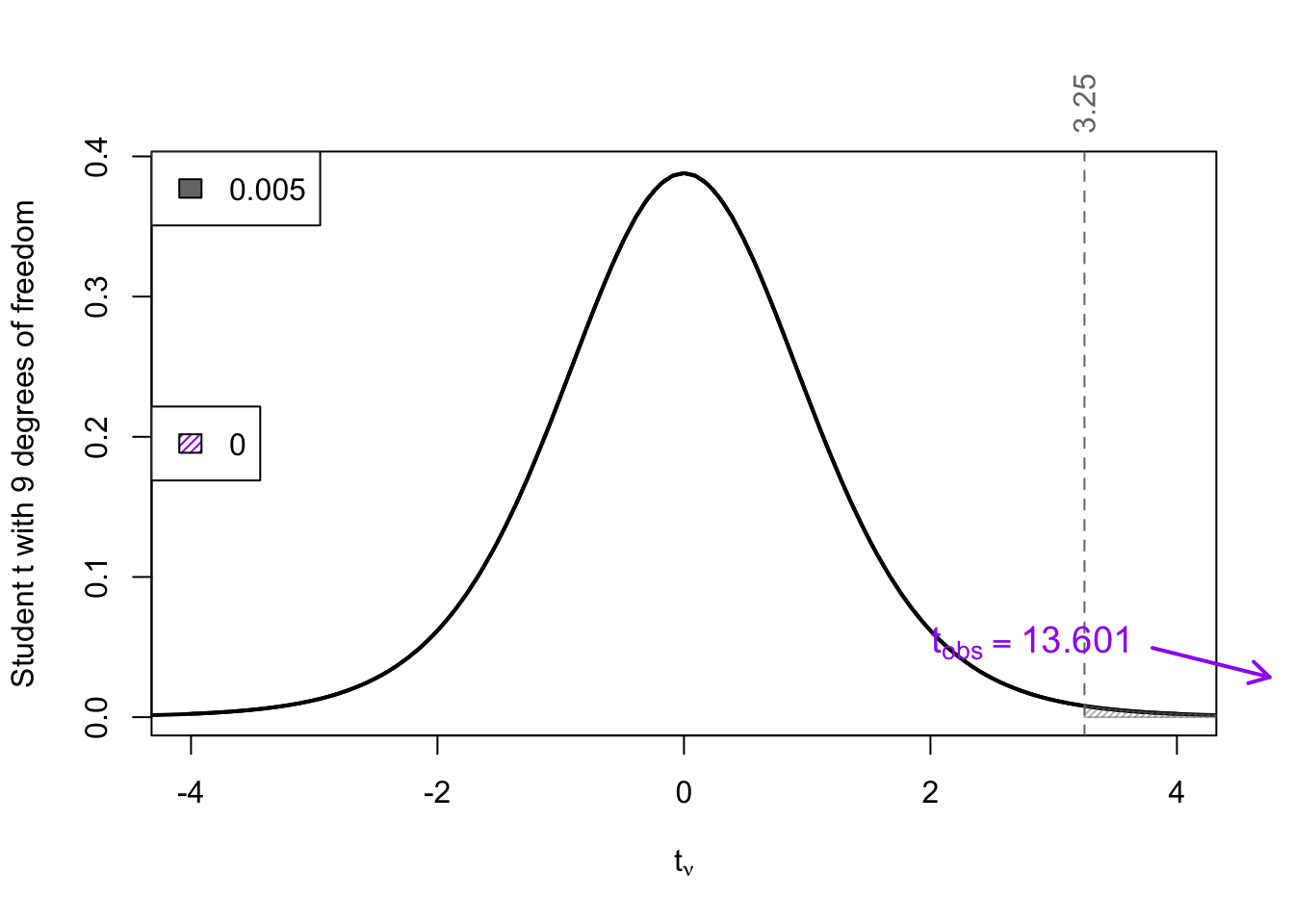
(e) State your decision.
Exercise 4.3 A researcher wants to compare the average weight (in pounds) of two breeds of small dogs. A random sample of dogs from each breed is selected:
Breed A: 160, 165, 158, 170, 162, 164, 159
Breed B: 155, 150, 158, 152, 149, 153, 151
Assume the population variances for the two breeds are equal. At the 5% significance level, is there evidence that the mean weights of the two breeds differ?
(a) What kind of test is appropriate?
(b) State the hypotheses.
(c) Compute the test statistic by hand.
(d) State the null distribution.
(e) Use the critical value approach to make a decision.
For a two-sided test at \(\alpha = 0.05\), the critical value is:
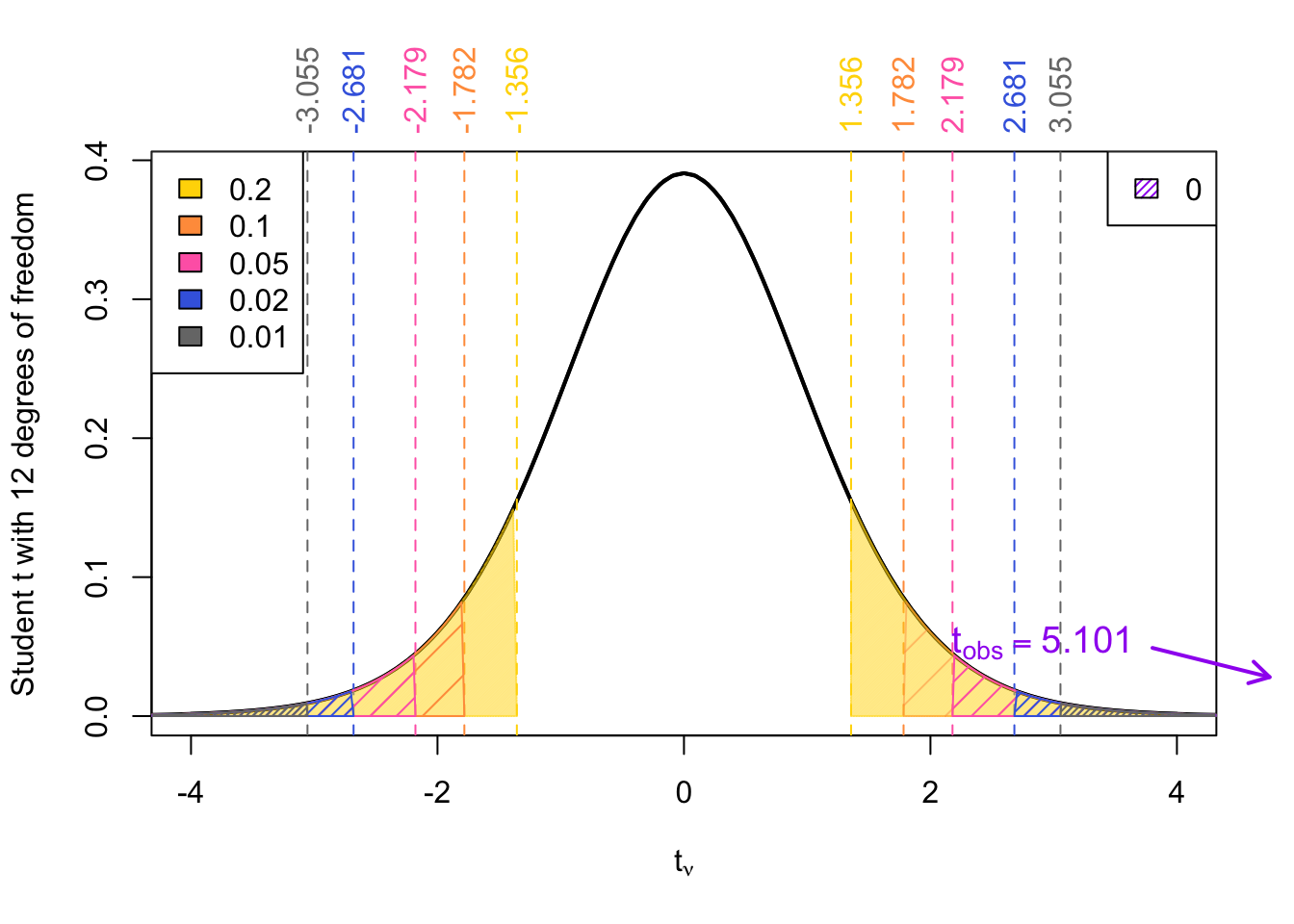
\[ t^* = t_{\alpha/2, \nu} = t_{0.025, 12} = 2.179 \]
We reject the null hypothesis if \(|t_{obs}| > t^*\):
\[ |5.101| > 2.179 \]
So we reject the null hypothesis.
Visually we can see that our observed test statistic falls in the rejection region. Hence we reject the null in favour of the alternative.
rr_t(df = nu, symbols = FALSE)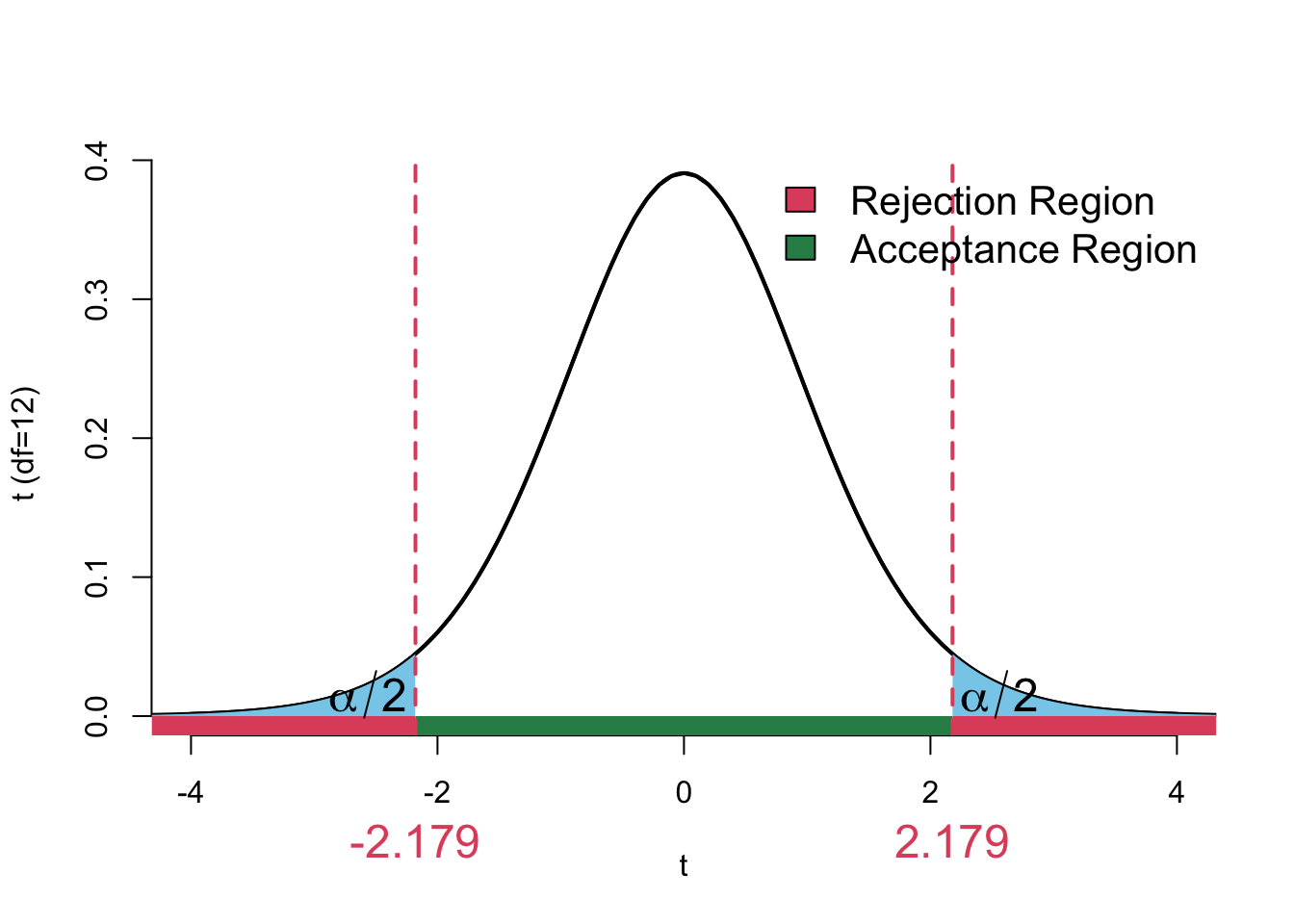
(f) Compute the p-value i) approximate using the t-tables ii) exactly using R.
The reference row from the \(t\)-table is:

Given a \(t_{obs}\) = 5.1007548 degrees of freedom \(\nu\) = 12 the \(p\)-value can be approximated as:
\[ \begin{align} p\text{-value} &= 2 \times \Pr(t_{12} > t_\text{obs} ) \\ &= 2 \times \Pr(t_{9} > 5.1) \\ & < 2 \times \Pr(t_{9} > \textcolor{gray}{3.25}) = 2 \times \textcolor{gray}{0.005} \\ \implies p\text{-value} &< \textcolor{gray}{0.01} \end{align} \]
The exact \(p\)-value is found using:
2*pt(abs(5.1007548), df = 12, lower.tail = FALSE)[1] 0.0002614753Hence: \[ p = 2 \cdot \Pr(t_{\nu = 12} > |t_{obs}|) = 2 \cdot \Pr(t_{12} > 5.101) = 2.61e-04 \]
Visually:
Exercise 5.1 Researchers are investigating the effect of different treatments on plant growth. The dataset PlantGrowth contains the weights of plants subjected to three different groups: a control group (ctrl), and two treatment groups (trt1 and trt2). Each group contains 10 observations (30 total). A box plot of the data is provided in Figure 5.1.
PlantGrowth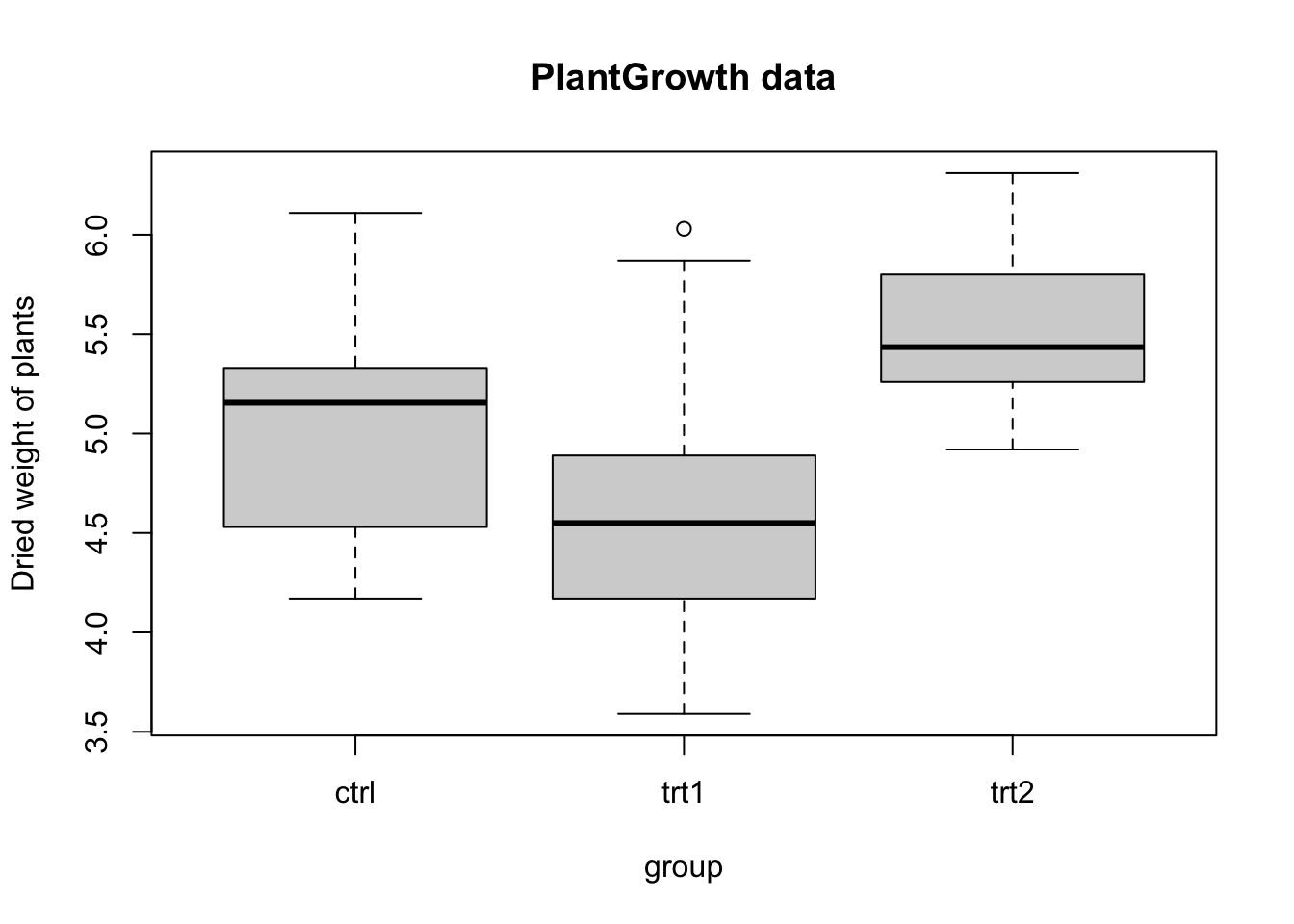
A one-way ANOVA was performed in R using the code below:
anova_result <- aov(weight ~ group, data = PlantGrowth)
summary(anova_result)| Source | Df | Sum Sq | Mean Sq | F value | Pr(>F) |
|---|---|---|---|---|---|
| group | 3.7663 | 0.0159 | |||
| Residuals | 0.3886 |
(a) Complete the ANOVA table (you have enough information to complete the table without having to refer to the dataset help file or R for examining the output).
(b) What is the null and alternative hypothesis being tested by this ANOVA?
(c) At the \(\alpha = 0.05\) significance level, what conclusion should be drawn based on the ANOVA result? Interpret it in context.
(d) What follow-up analysis should the instructor conduct to determine which specific groups differ in exam performance? Explain its purpose.
(e) ANOVA relies on several assumptions. Name one assumption and describe how it could be verified.
Exercise 6.1 Suppose we want to test the effectiveness of a drug for a certain medical condition. We have 105 patients under study and 50 of them were treated with the drug, and the remaining 55 patients were kept under control samples. The health condition of all patients was checked after a week.
data_frame = read.csv("https://goo.gl/j6lRXD")
table(data_frame$treatment, data_frame$improvement)
improved not-improved
not-treated 26 29
treated 35 15In the contingency table we see that 35 out of the 50 patients in the treatment group showed improvement, compared to 26 out of the 55 in the control group. Perform the appropriate chi-squared test for independence
by hand
using R’s chi.test() function
If the drug had no effect, we would expect the same proportion of the patients who improved to be the same between the treatment and control group.
Here, the improvement in the treatment case is 70% , as compared to 47.27 % in the control group.
Do these data ssuggest that the drug treatment and health condition are dependent?
A chi-squared test for independence will examine the relationship between two categorical variables: treatment condition (drug vs. control) and health outcome (improvement vs. no improvement).
Hypotheses
Other ways you might say this:
The null implies that the drug does not affect the health outcome of the patients compared to the control group.
The alternative implies that the drug has an effect on the health outcome, making an improvement more likely (or less likely) compared to the control group.
To answer this question we need to compute the expected table. Under the null, the expected counts would be:
\[ \dfrac{\text{row total} \times \text{col total}}{\text{total}} \]Below I have computed the corresponding sums and added them to the margins:
response
treatment improved not-improved Sum
not-treated 26 29 55
treated 35 15 50
Sum 61 44 105The calculations performed cell by cell are as follows:
\[ \begin{align} \text{Expected no. of not-treated that improved } &= \dfrac{55 \times 61}{105} = 31.952381\\ \text{Expected no. of not-treated that not-improved } &= \dfrac{55 \times 44}{105} = 23.047619\\ \text{Expected no. of treated that improved } &= \dfrac{50 \times 61}{105} = 29.047619\\ \text{Expected no. of treated that not-improved } &= \dfrac{50 \times 44}{105} = 20.952381 \end{align} \]
response
treatment improved not-improved
not-treated 31.95238 23.04762
treated 29.04762 20.95238To calculate the test statistic we compute our test statistic
\[ \sum \dfrac{(\text{Observed} - \text{Expected})^2}{\text{Expected}} \sim \chi^2_{df = 2 \times \nu_2 = 1 = 1} \]
\[ \begin{align} \\ &= \frac{(26 - 31.952381)^2}{31.952381} + \frac{(29 - 23.047619)^2}{23.047619} + \dots\\ &\quad \dots \frac{(35 - 31.952381)^2}{29.047619} + \frac{(15 - 31.952381)^2}{20.952381}\\ &= 5.5569198 \end{align} \]
Comparing this to a \(\chi^2\) random variable with \(df = (r - 1) \times (c -1)\) \((2 - 1) \times (2 - 1) = 1\)
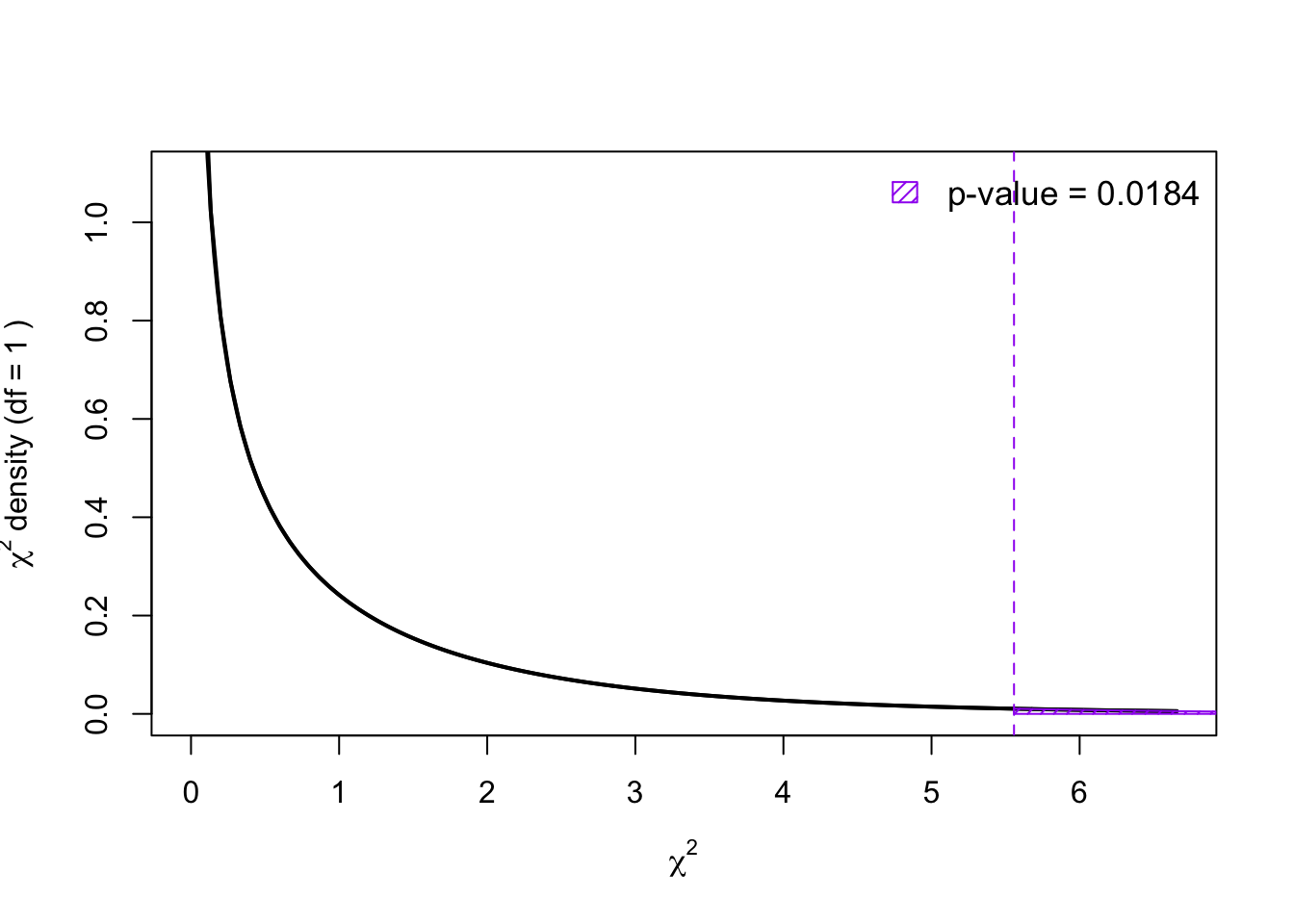
Since the \(p\)-value is less than the significance level of \(\alpha = 0.05\), we reject the null hypothesis in favour of the alternative. Hence there is sufficient statistical evidence to suggest that Health outcome of patients is indepedent of whether or not the patient took the drug.
chisq.test() functionIn the case of a null hypothesis, a chi-square test is to test the two variables that are independent. The following conducts a a chi-squared test on the treatment and improvement
chisq.test(data_frame$treatment, data_frame$improvement, correct=FALSE)To match the results above we use correct=FALSE to turn off the continuity correction (where one half is subracted from all observed - expected differences).
Exercise 6.2 car manufacturer claims that the proportion of defective brake pads produced across its three work shifts is consistent with historical rates: 20% during the day shift, 30% during the evening shift, and 50% during the night shift.
To assess this claim, a quality control manager inspects a random sample of 200 defective brake pads and records which shift they came from:
At the 5% significance level, is there evidence that the current distribution of defects differs from the historical pattern?
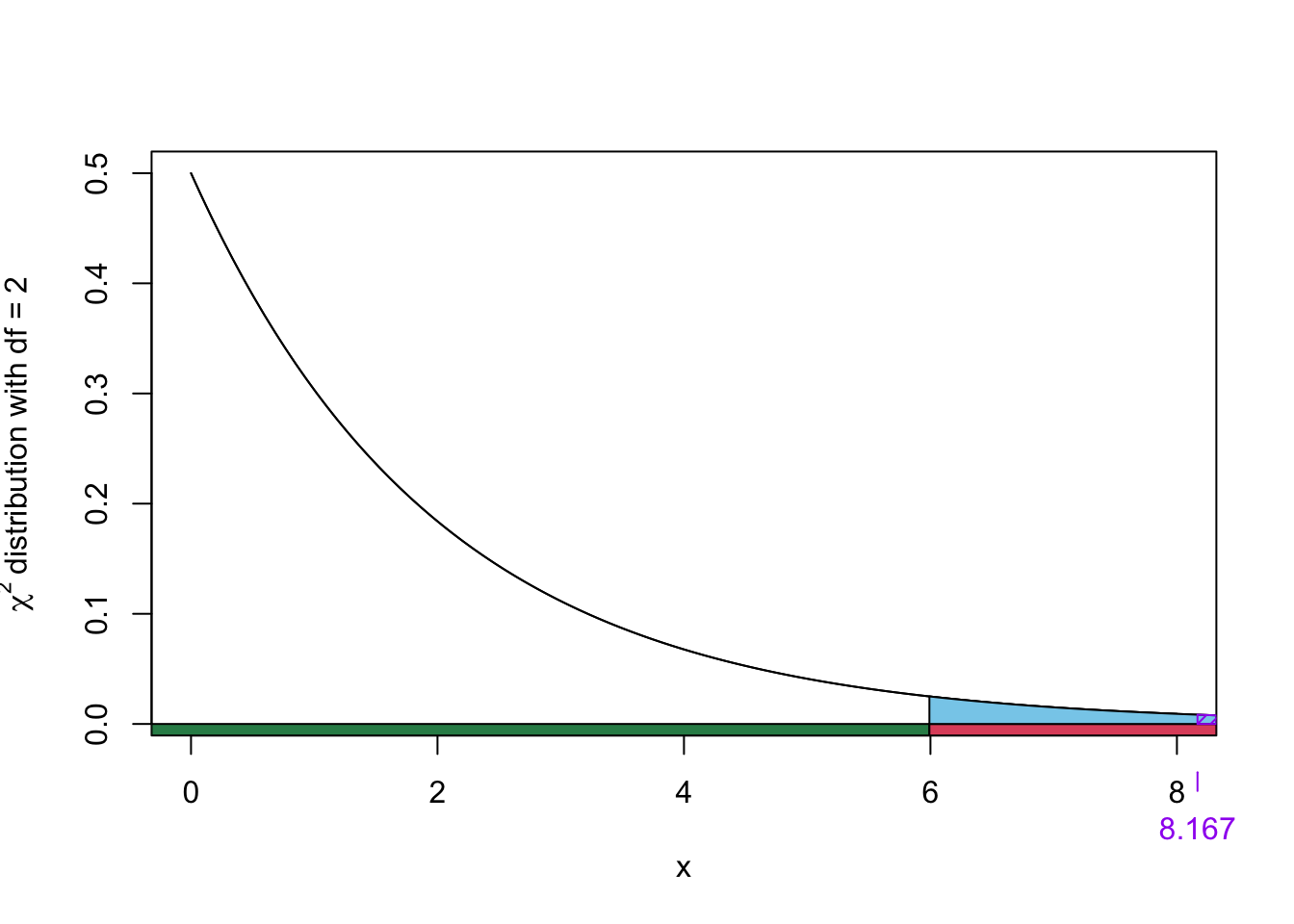
Since the observed test statistic \(\chi^2_{obs}\) = 8.1666667 falls inside the rejection rejection, we reject the null hypothesis in favour of the alternative.
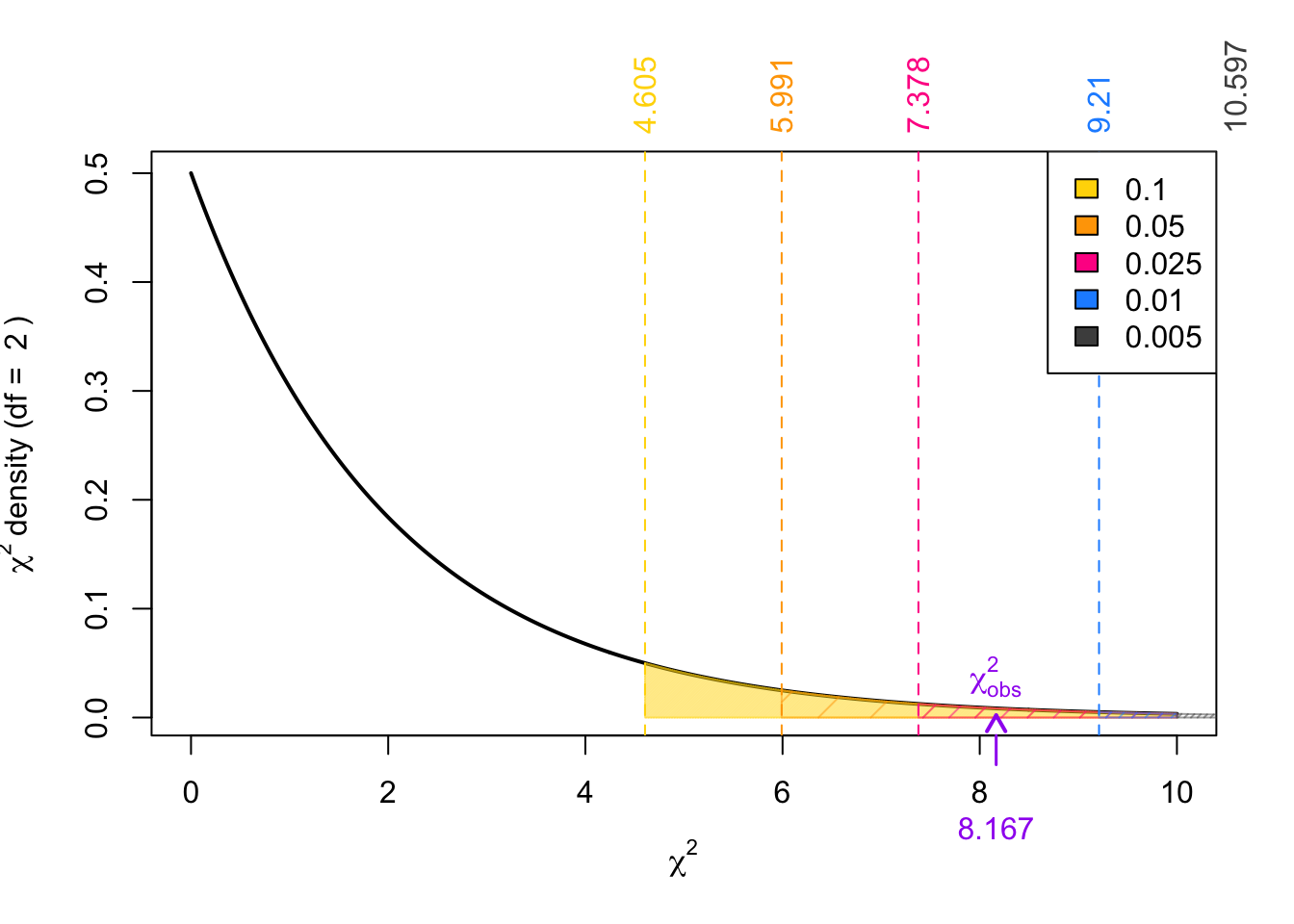
The exact p-value in R is computed using
pchisq(8.1666667, df = 2, lower.tail = FALSE)[1] 0.0168512Remember that the chi-squared tests are always upper-tailed test. The p-value is visualized below:
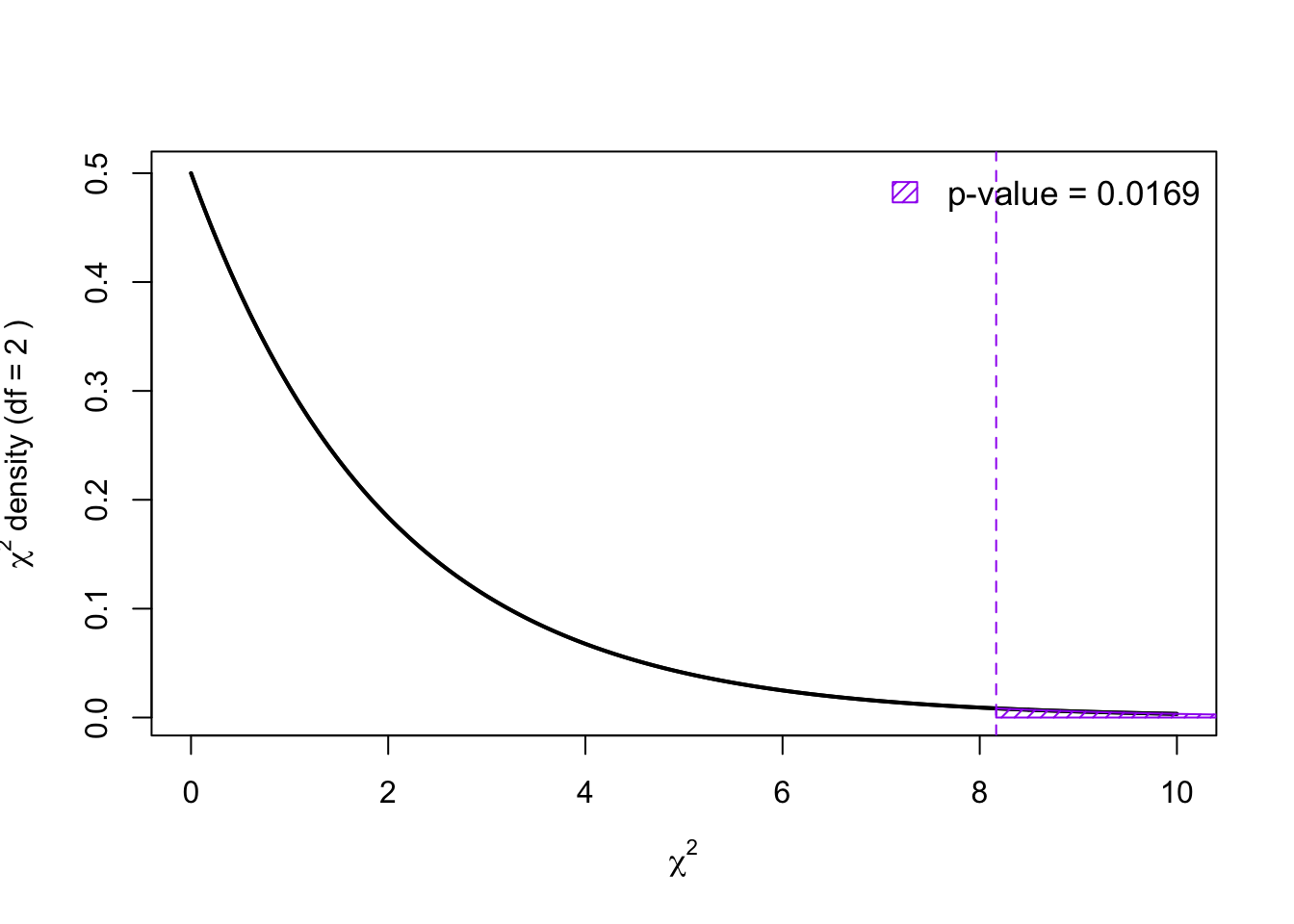
h. Which of the following R commands correctly performs a chi-squared goodness-of-fit test for this scenario?
chisq.test(30, 50, 120)chisq.test(30, 50, 120, p = c(1/3, 1/3, 1/3))chisq.test(30, 50, 120, p =0.2, 0.3, 0.5)chisq.test(0.2, 0.3, 0.5, p =30, 50, 120)Exercise 6.3 An automobile manufacturer wants to know whether three factories produce the same distribution of defect types.
A random sample of recent defects at each factory is recorded below:
Brake Steering Transmission
Factory A 35 15 25
Factory B 22 18 20
Factory C 28 12 30At the 5% significance level, is there evidence that the distribution of defect types differs across the three factories?
(a) State the hypotheses.
(b) What type of test is appropriate for this situation? i. Chi-squared test for independence ii. Chi-squared goodness of fit test iii. Chi-squared test for homogenity iv. None of the above are appropriate
(c) Conduct the appropriate test in R.
(d) State your conclusion based on the \(p\)-value and \(\alpha = 0.05\).