Non-graphing, non-programmable, calculator (e.g. Casio FX-991, Sharp EL-W516, EL-520 , Texas Instruments TI-36X Pro, CASIO fx-991ES PLUS C*). If you are unsure if your calculator is permitted, please ask me ASAP.
One standard page cheat sheet (front and back). You will be required to hand this in at the end of the test.
Review
Describing Data
What is statistics (descriptive vs inference)
descriptive: involves describing, summarizing, and displaying data
inferential: involves using a sample of data to draw conclusions about a population
Summary statistics:
Measures of central tendency: mean, median (more robust1 than the mean), mode
Measures of dispersion: variance, standard deviation (same units as the data), IQR (more robust than sd/var),
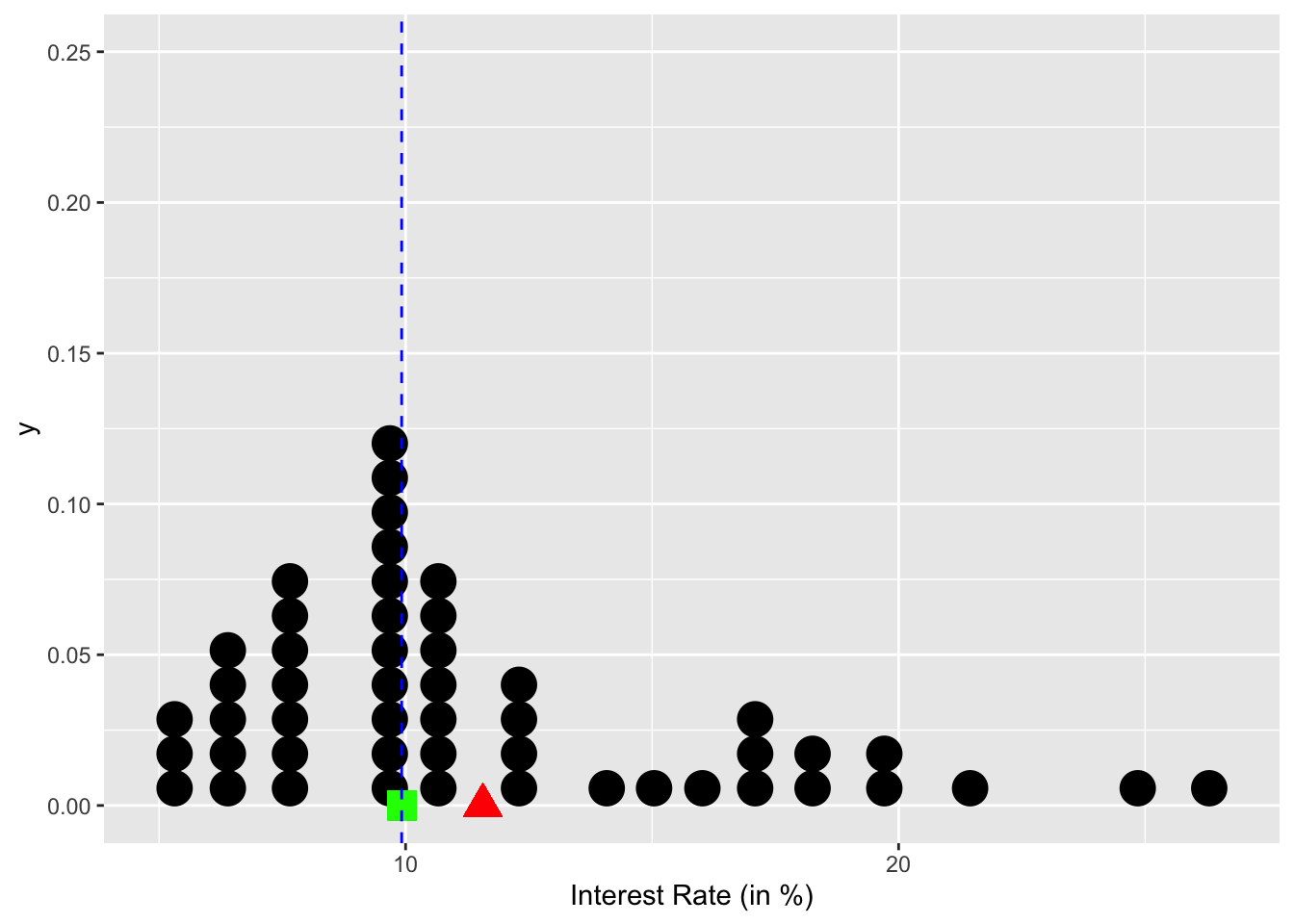
# Define a function to calculate the modeMode <-function(x) { ux <-unique(x) ux[which.max(tabulate(match(x, ux)))]}mean_value =mean(loan50$interest_rate)median_value =median(loan50$interest_rate)mode_value <-Mode(loan50$interest_rate)
Mean
Median
Mode
11.5672
9.93
9.92
Code
# Create a dot plot with mean and median using ggplot2library(ggplot2)ggplot(loan50, aes(x = interest_rate)) +geom_dotplot() +labs(x ="Interest Rate (in %)") +geom_point(aes(x = mean_value, y =0), color ="red", size =5, shape =17) +geom_point(aes(x = median_value, y =0), color ="green", size =5, shape =15) +geom_vline(xintercept = mode_value, color ="blue", linetype ="dashed") +annotate("text", x = mode_value , y =0.6, label ="Mode", vjust =1.5, color ="blue") +coord_cartesian(ylim =c(0, 0.25)) # Adjust the y-axis limits here
Warning in geom_point(aes(x = mean_value, y = 0), color = "red", size = 5, : All aesthetics have length 1, but the data has 50 rows.
ℹ Please consider using `annotate()` or provide this layer with data containing
a single row.
Warning in geom_point(aes(x = median_value, y = 0), color = "green", size = 5, : All aesthetics have length 1, but the data has 50 rows.
ℹ Please consider using `annotate()` or provide this layer with data containing
a single row.
A dotplot for the interest rates in the loan50 dataset. The mean is ploted as a red triangle, and the median is plotted as a green square. The mode (the value that appears most often in a set of data values) is 9.92 and displayed as a blue dash.
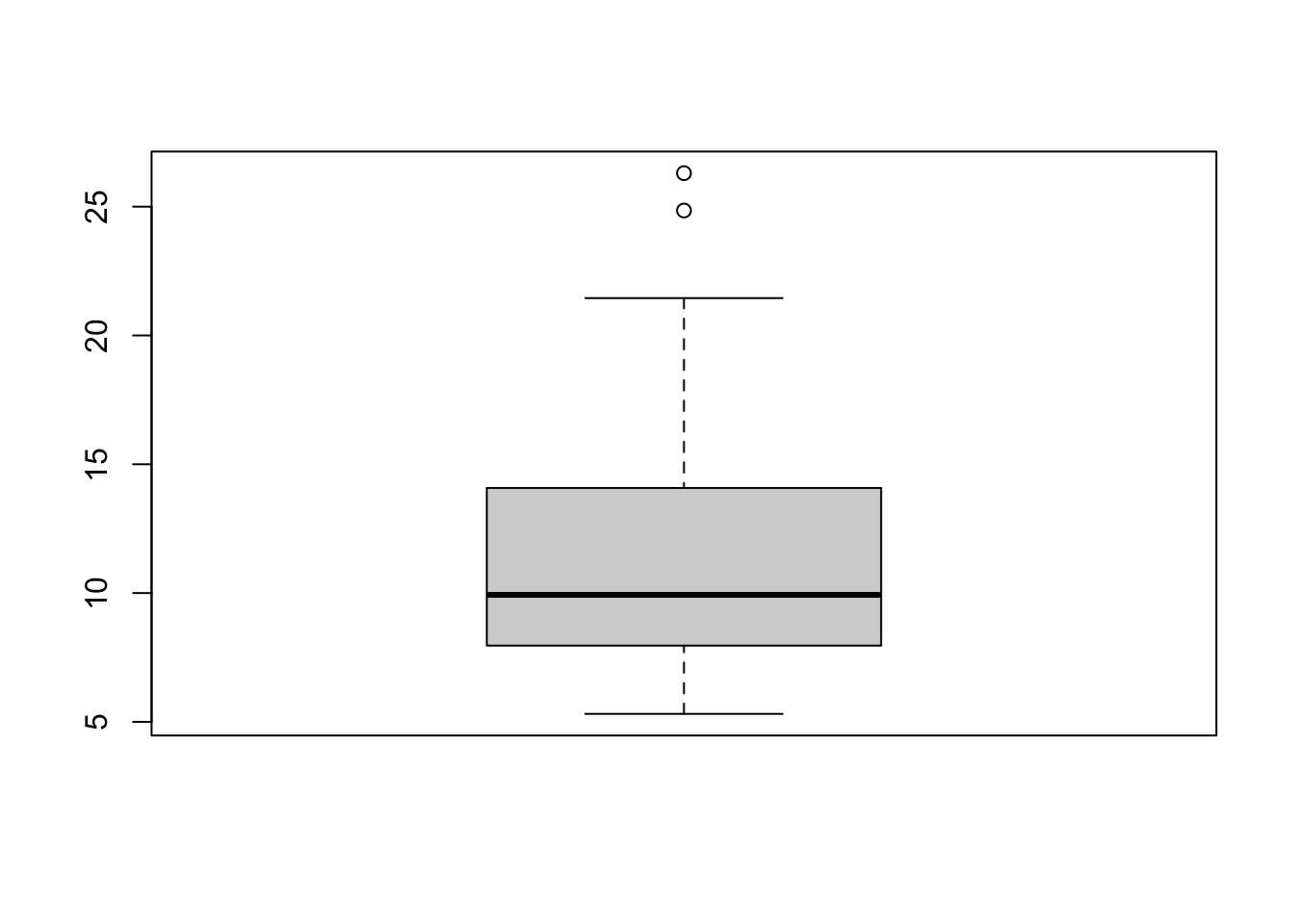
boxplot(loan50$interest_rate)
A boxplot for the interest rates in the loan50 dataset. The box in the middle of the plot represents the interquartile range (IQR), which spans from the first quartile (Q1) to the third quartile (Q3). The length of the box shows the spread of the middle 50% of the data. The horizontal line inside the box represents the median (Q2), which is the middle value of the dataset when it’s sorted in ascending order. Whiskers extend from the edges of the box to the minimum and maximum values within the range of [Q1 - 1.5XIQR, Q3 + 1.5XIQR]. Observations outside this range are considered potential outliers and are plotted individually (here there are two potential outliers as indicated by the two open circles. Notice how the skewed shape becomes apparent in this boxplot.
The shape of a distribution can be described as
symmeteric: where the left side of the distribution mirrors the right side.
The mean, median, and mode are all located at the center of the distribution.
Examples include the normal distribution and the uniform2 distribution.
skewed: asymmetrical, with the data clustering more toward one end of the distribution.
either ight (positive skew) or left (negative skew).
The mean will be less (resp. more) than the median for right (resp left) skewed distribution
The modality of a distribution describes the number of peaks:
unimodal (one peak), bimodal (two peaks), multi-modal (2 or more peaks), uniform (no peaks.
Sampling from Target Populations
Reasons for sampling vs. census: save time and money, logistics, feasibility
Sampling techniques: simple, stratified, and cluster sampling
Types of bias: non-response (e.g. illegal immigrants), selection bias (technology-based health interventions).
Difference in notation between a population and a sample
Population
Sample
size \(N\)
sample size \(n\)
mean \(\mu = \dfrac{x_1 + \dots + x_N}{N}\)
sample mean \(\bar{x} = \dfrac{x_1 + \dots + x_N}{n}\)
Numeric variables: variables that represent quantities or numerical values
continuous (numeric): can take on any value within a certain range
discrete (integer): can only take on specific, distinct values
categorical: variables that represent categories or groups
nominal/unordered categorical (factor): represent categories with no inherent order or ranking.
ordinal/ordered categorical (ordered factor): represent categories with a natural order or ranking, e.g. sanctification rating (poor, fair, good, excellent)
can be codified as numbers but treated different than iteger
logical (0/1 or boolean) variables.
check with as.logical or class; coerce with as.logical
Relationships between variables
When two variables show some connection/relationship with one another, they are called associated (or dependent) variables.
If two variables are not associated, i.e. there is no evident connection between the two, then they are said to be independent.
Outliers
Outliers: data points that significantly differ from the rest of the data
potential causes: measurement errors, data entry (human error), natural variation, or genuine anomalies (novelties in data).
potential ramifications: can distort statistical analyses and models, influencing results and interpretations.
One way that we have identified outliers is through boxplots.
Types of studies
Observational: collects data on variables of interest without intervening or manipulating any aspect of the study participants.
often used to describe patterns, associations, or relationships between variables in their natural settings.
Experiments: researcher deliberately manipulates one or more independent variables and observes the effect on one or more dependent variables while controlling for other factors.
often used to establish causality by determining whether changes in one variable (the independent/explanatory variable) cause changes in another variable (the dependent/response variable).
Rstudio and quarto docs
R basics
Types of data: numeric, factor, character, …
data structures: vector, matrix, data frame, tibble, lists,
vectors can only store one data type
data frames/tibbles can store different data types (same within each column, however)
vectorization
z =c(1,9,-6,3)z +2
[1] 3 11 -4 5
indexing using [] and $
how to read in data (e.g. read.csv)
coercing data types (e.g. as.numeric, factor, …)
examining data (e.g. head, str, View, …)
help function/operator: help(), ?<name of thing you need help manual for>
Navigating RStudio
Source vs visual editor
Rstudio panels:
editor: where your .R scripts and .qmd files populate
console: your “interactive” mode
environment and history
file, plots, help and viewer:
Working directory
Basic Rmarkdown:
## Level 2 header*italic*, **bold**, ***bold and italic***- unordered list item 1- unordered list item 2- unordered list item 31. ordered list item 11. ordered list item 21. ordered list item 2
```{r}x = 4```
My favourite number is `r x`
Which renders to:
Level 2 header
italic, bold, bold and italic
unordered list item 1
unordered list item 2
unordered list item 3
ordered list item 1
ordered list item 2
ordered list item 2
x =4
My favourite number is 4
Code chunk options
echo: to show or hide code chunks
eval: to evaluate a code chunk or not
fig-: options for figure rendering (eg. -width, -height, -cap)
out-width: controls how much space the outputted figure will take up
A statistic is a numerical quantity calculated from a sample of data: \(T(X) = g(X_1, X_2, \dots, X_n)\)
\(T(X)\) is a random variable for which you can find expected values for.
A sampling distribution is the probability distribution of a given a sample statistic.
Central Limit Theorem
Let \(X_1, X_2, \dots, X_n\) be a sequence of independent and identically distributed (i.i.d) RVs each having mean \(\mu\) and variance \(\sigma^2\). Then for \(n\) large, the distribution of the sum of those random variables is approximately normal with mean \(n\mu\) and variance \(n\sigma^2\)
In order for the Central Limit Theorem to hold, the sample size is typically considered sufficientlylarge when \(np \geq 10\) and \(n(1-p) \geq 10\) , which is called the success-failure condition.
Plug in principal: to approximate this we sub \(p\) (the unknown population parameter) with the point estimate \(\hat p\):
Let \(X_1, X_2, \dots, X_n\) be a random sample from a normal distribution with mean \(\mu\) and variance \(\sigma^2\). It can be shown that
\[\begin{align*}
\dfrac{(n−1)S^2}{\sigma^2} = \frac{\sum_{i=1}^n (X_i - \bar{X})^2}{{\sigma^2}} \sim \chi^2_{(n-1)}
\end{align*}\] where \(\chi^2_{(n-1)}\) denotes a chi-squared distribution with \(n−1\) degrees of freedom.
Sampling distribution of Sample Mean with unknown population variance
Let \(X_1, \ldots, X_n\) be a sample from a normal population with mean \(\mu\). If \(X\) denotes the sample mean and \(S\) the sample standard deviation, then \[
\frac{\sqrt{X - \mu}}{S/\sqrt{n}} \sim t_{n-1}
\] That is, \(\frac{n(X - \mu)}{S \sqrt{n}}\) follows a t-distribution with \(n - 1\) degrees of freedom.
Parameter Estimation
A Point estimators provide a single “best guess” for the parameter.
The sample statistic \(\hat \theta (X_1, \dots, X_n)\) is an estimator for the parameters; the observed value \(\hat \theta (x_1, \dots, x_n)\)(calculated using particular sample data) are called estimates of the parameters.
Desirable properties of estimators
An estimator, \(\hat \theta\), is unbiased if the mean of its sampling distribution is the parameter \(\theta\). The bias of an estimator, \(\hat \theta\), is given by \[\text{Bias}(\hat \theta) = B = \mathbb{E}[\theta] - \theta\]
An efficient estimator achieves the smallest possible variance among a class of unbiased estimators
The mean square error of the estimator \(\hat\theta\), denoted by \(\text{MSE}(\hat\theta)\), is defined as: \[
\text{MSE}(\hat\theta) = \mathbb{E}[(\hat\theta - \theta)^2]
\]
For unbiased estimators \(\hat\theta\) (where the bias is 0) it is clear that
Given two estimates, \(\hat\theta_1\) and \(\hat\theta_2\), of a parameter \(\theta\), the efficiency of \(\hat\theta_1\) relative to \(\hat\theta_2\), is defined to be
Thus, if the efficiency is smaller than 1, \(\hat\theta_2\) has a larger variance than \(\hat\theta_1\) has.
Minimum variance unbiased estimator (MVUE) is an unbiased estimator whose variance is smaller or equal to the variance of any other unbiased estimator for all potential values of \(\theta\).
Cramer Rao Lower Bound (CRLB) Suppose that \(X_1, \dots X_n\) is a random sample from a population having a common density function \(f(x; \theta)\) depending on a parameter \(\theta \in \Omega\). Assume that the regularity conditions \((R0)–(R4)\) hold and let \(\hat\theta\) be an unbiased estimator of \(\theta\). The variance of any estimator \(\hat{\theta}\) of such a parameter must meet the following inequality: \[\begin{equation}
\text{Var}(\hat{\theta})\geq \dfrac{1}{I_n(\theta)} = \dfrac{1}{nI(\theta)}\label{C-R}
\end{equation}\] where \(I_n(\theta)\) denotes the Fisher information in the sample, and \(I(\theta)\) denotes the [Fishers Information] in a single observation from \(f(x; \theta)\)
If CRV is the theoretical variance bound given by the CRLB theorem, then the efficiency of an unbiased estimator \(\hat\theta\) is given by:
Efficiency cannot be bigger than 1 and is usually expressed in percent. An estimator which reaches 100% efficiency when \(n \rightarrow \infty\) is called asymptotically efficient.
An estimator is sufficient if “no other statistic that can be calculated from the same sample provides any additional information as to the value of the parameter
A minimal sufficient statistics are those that are sufficient for the parameter and are functions of every other set of sufficient statistics for those same parameters.
A consistent estimator is a statistical estimator whose accuracy improves as the sample size increases. A consistent estimator must have two properties:
\[\mathbb{E}[\hat \theta] \underset{n\rightarrow \infty }{\longrightarrow } \theta\] i.e. be asymptotically unbiased, and \[
\text{Var}(\hat{\theta})\underset{n\rightarrow \infty }{\longrightarrow }0
\] meaning that its variance must tend to zero with increasing sample size.
Methods of Finding Point Estimators
Method of Moments: sample moments are equated to their corresponding population moments to obtain estimates for the parameters.
The \(k\)th (population) moment (about the origin) of a random variable \(X\), denoted \(\mu_k'\) is the expected value of \(X^k\).
\[\mu_k' = \mathbb{E}[X^k]\]
The \(k\)th sample moment (about the origin) \(m_k'\) is defined as the average of the \(k\)th powers of the observed data points.
\[m_k' = \frac{1}{n} \sum_{i=1}^n X_i^k\]
Suppose there are \(l\) parameters to be estimated. From the system of equations
\[\mu_k' = \frac{1}{n} \sum_{i=1}^n X_i^k\]
for \(k = 1,2, \dots, l\) solve for \(\Theta = (\theta_1, \dots, \theta_l)\)
Maximum likelihood estimation (MLE): seeks to find the values of model parameters that maximize the so-called likelihood function.
Likelihood (definition)
Let \(f(x_1, \ldots, x_n; \theta)\), \(\theta \in \Theta \subseteq \mathbb{R}^k\), be the joint probability (or density) function of \(n\) random variables (\(X_1, \ldots, X_n\)) with sample values (\(x_1, \ldots, x_n\)). The likelihood function of the sample is given by: \[\begin{equation}
L(\theta; x_1, \ldots, x_n) = f(x_1, \ldots, x_n; q)
\end{equation}\] Note: \(L\) is a function of \(\theta\) for fixed sample values.
If \((X_1, \ldots, X_n)\) are independent and identically distributed (iid) discrete random variables with probability mass function (PMF) \(p(x, \theta)\), then the likelihood function is given by: \[
\begin{align*}
L(\theta) &= P(X_1 = x_1, \dots, X_n = x_n) \\
&= \prod_{i=1}^{n} P(X_i = x_i) \text{ from independence}\\
&= \prod_{i=1}^{n} p(x_i; \theta)
\end{align*}
\]
And in the continuous case, if the density is \(f(x, \theta)\), then the likelihood function is:
\[
L(\theta) = \prod_{i=1}^{n} f(x_i; \theta)
\]
Maximum likelihood estimators (MLEs)
Maximum likelihood estimators or MLEs are those values of the parameters that maximize the likelihood function with respect to the parameter \(\theta\). That is, \[
\hat{\theta}_{\text{MLE}} = \underset{\theta \in \Theta}{\arg\max} \, L(\theta)
\] where \(\Theta\) is the set of possible values of the parameter \(\theta\).
It is often easier to work with the log-likelihood function denoted by \(\ell(\theta)\).
Confidence Interval
Interval estimators, also known as a confidence interval (CI), provides a range of values within which the true value of the parameter is expected to fall, along with a level of confidence.
CI provides some prescribed degree of confidence of securing the true parameter (typically 90%, 95%, or 99%)
Assumptions: When the sample data is a SRS from the population of interest, this CI is exact with population is normal, and approximate when (\(n>30\) as a rough guideline).
CI for \(\mu\) (unknown \(\sigma^2\))
CI for population mean (\(\mu\)) with unknow population standard deviation (\(\sigma\) )
Assumptions: When the sample data is a SRS from the population of interest, this CI is exact with population is normal, and approximate when (\(n>30\) as a rough guideline).
CI for \(p\)
A (\(1-\alpha\))% CI for population proportion (\(p\)) is given by:
Assumptions: The sample is drawn from a binomial distribution and we satisfy the success-failure condition for normal approximation to be valid (we use \(np > 10\) and \(n(1-p) > 10\)).
CI for \(\sigma^2\)
A \((1 - \alpha) \times 100\%\) confident that the population variance \(\sigma^2\) falls in the interval \[
\left(\frac{(n - 1)S^2}{\chi_{\frac{\alpha}{2}}^2}, \frac{(n - 1)S^2}{\chi_{1 - \frac{\alpha}{2}}^2}\right),
\]
where the \(\chi^2\) distribution has \((n - 1)\) degrees of freedom.
If we feel like the assumptions of the above procedures are not justified we can use nonparametric procedures instead.