Exercise 1 A nutritionist wants to assess the effectiveness of a new diet plan in reducing cholesterol levels in individuals. She selects a sample of 30 participants and measures their cholesterol levels before and after following the diet plan for 8 weeks. The differences in cholesterol levels (in mg/dL) before and after the intervention are recorded in the csv here. Conduct a formal hypothesis for investigating whether of not this diet significantly reduces cholesterol levels.
# you can load the data directly from URLurl ="https://irene.vrbik.ok.ubc.ca/data/stat205/cholesterol.csv"cholesterol <-read.csv(url)
Data
cholesterol
Boxplot
boxplot(before, after, data = cholesterol, names =c("Before", "After"))
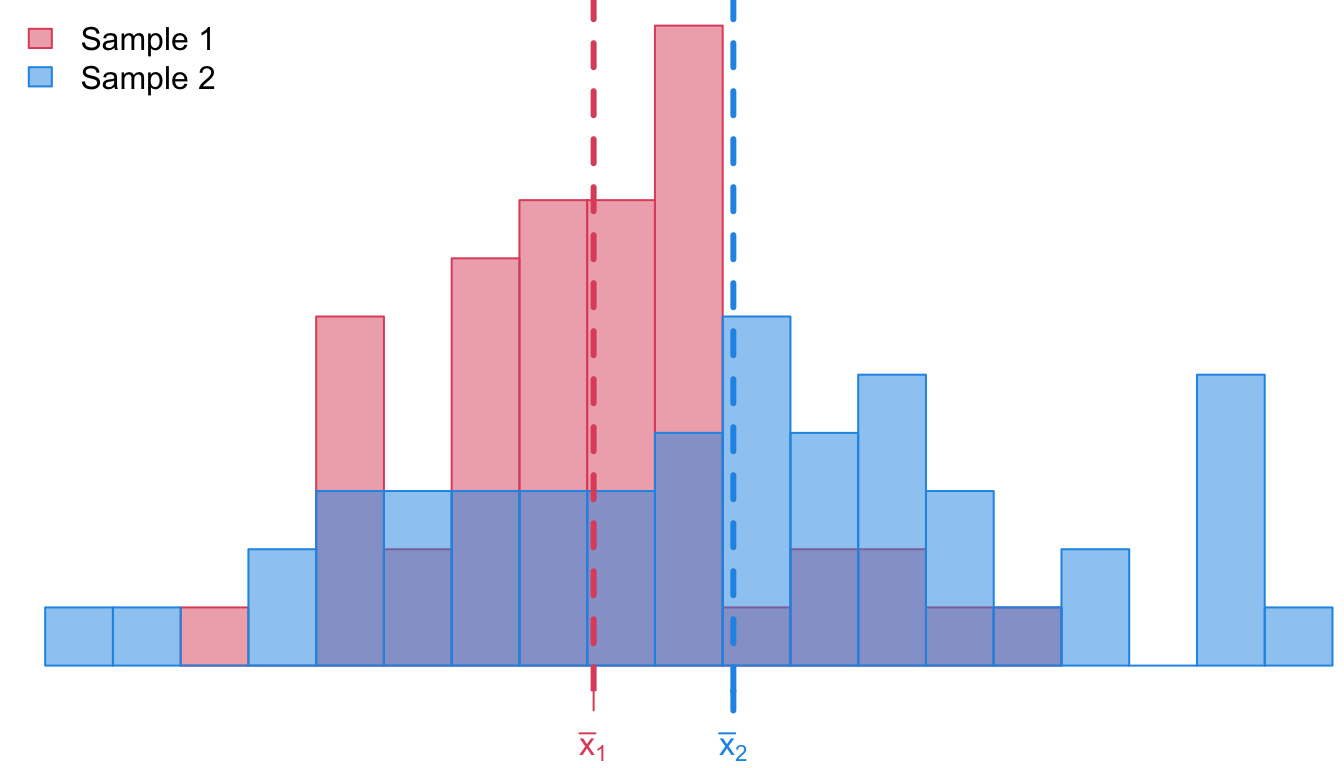
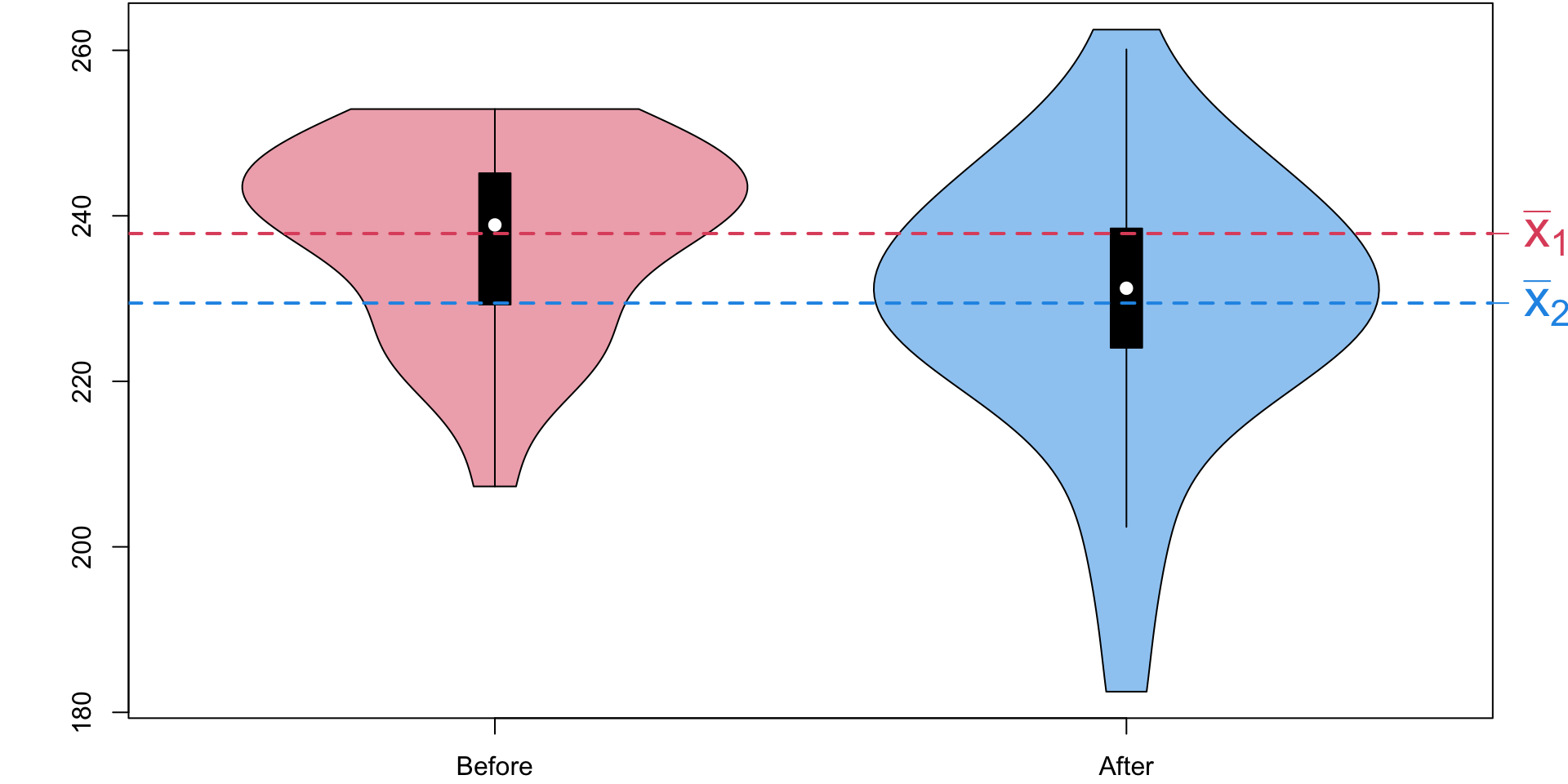
Figure 4: Do these data provide statistically significant evidence that the average level cholesterol of patients lower after this 8-week diet?
Histograms
Code
attach(cholesterol)# Set up the histogram with transparencyhist(before, breaks =30, col =adjustcolor(2, alpha.f =0.5), border =2,xlim =range(c(before, after)),main ="", xlab ="", ylab ="Frequency")# Add second histogramhist(after, breaks =30, col =adjustcolor(4, alpha.f =0.5), border =4, add =TRUE)# Manually add only the y-axis (removes x-axis numbers)axis(2)# Add vertical dashed lines for meansabline(v =mean(before), col =2, lty =2, lwd =2)abline(v =mean(after), col =4, lty =2, lwd =2)# Add legendlegend("topright", legend =c("Before", "After"), fill =c(adjustcolor(2, alpha.f =0.5), adjustcolor(4, alpha.f =0.5)), border =c(2, 4), bty ="n")
Violin Plot
Code
# Load necessary packagelibrary(vioplot)par(mar=c(2,4,0,2.3)+0.1)# Create the violin plotvioplot(before, after, names =c("Before", "After"), col =adjustcolor(c(2, 4), alpha.f =0.5))# Add mean pointsabline(h=mean(before), col =2, lwd =2, lty =2) # Mean for "Before"abline(h=mean(after), col =4, lwd =2, lty =2) # Mean for "After"axis(4, at =mean(before), labels =expression(bar(x)[1]), col =2, col.axis =2,las =2, cex.axis =2)axis(4, at =mean(after), labels =expression(bar(x)[2]), col =4, col.axis =4, las =2, cex.axis =2)
Calculating sample differences
In order to do inference on the paired difference of means,
# Create new column for the differences dicholesterol$diff = cholesterol$before - cholesterol$afterhead(cholesterol)
Summary statistics
The mean of the differences, \(\bar d\) is:
(dbar =mean(cholesterol$diff))
[1] 8.406667
And the sample standard deviation of the differences is:
(sdd =sd(cholesterol$diff))
[1] 12.46133
The sample size, \(n\), is the number of mathed pairs
(n =nrow(cholesterol))
[1] 30
Normality check
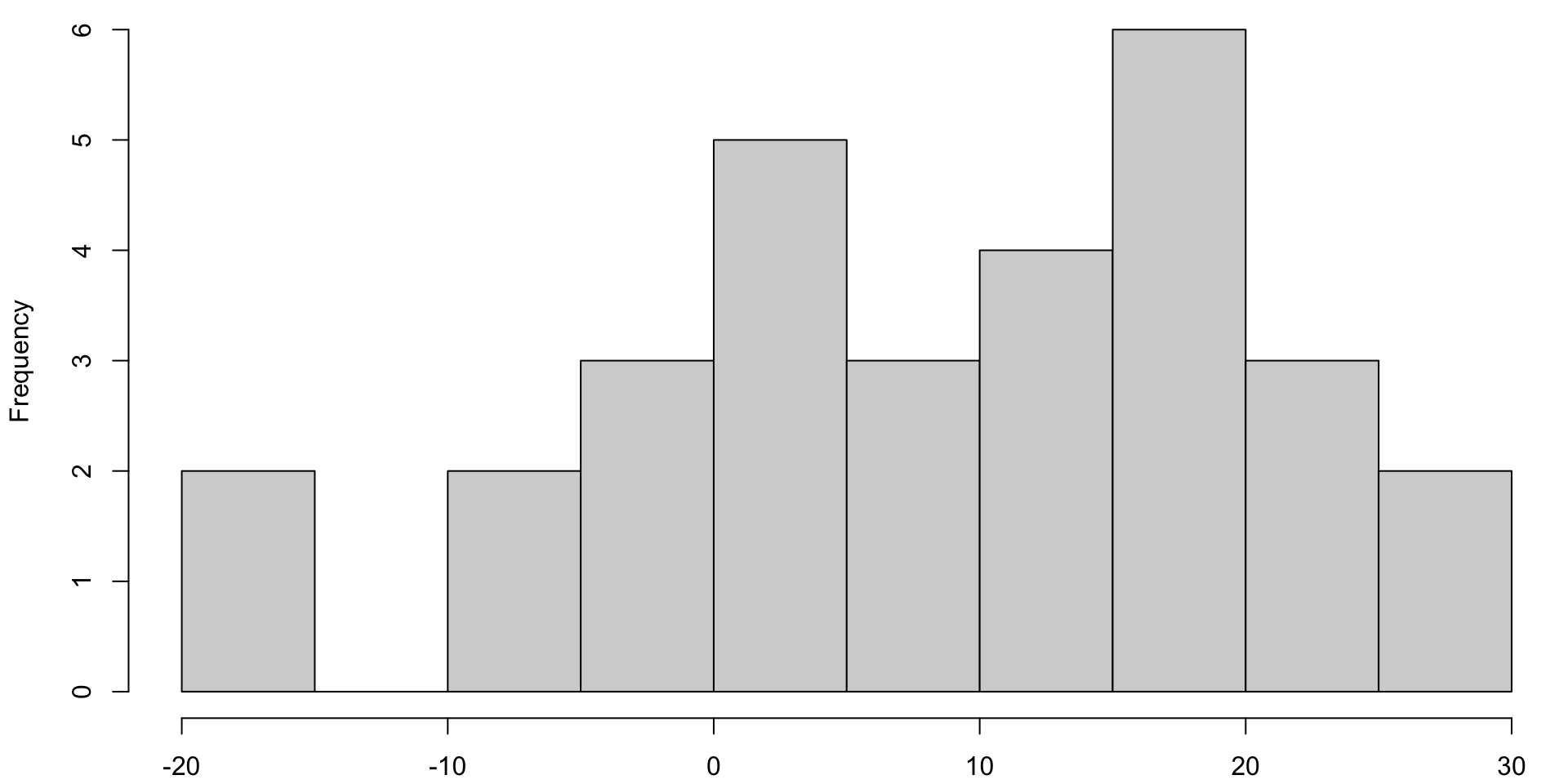
The test assumes that the differences in cholesterol follow a normal distribution.
While we have enough data points to rely on the CLT, let’s see how we’d check the normality assumption.
par(mar=c(par.sm))# histogram of differenceshist(cholesterol$diff, breaks =10, main ="")
Shapiro-Wilk Test
Rather than looking at these plots in a subjective way, we could alternative perform a statistical test called the Shapiro-Wilk test for normality.
The Shapiro-Wilk test is a statistical test used to determine whether a dataset follows a normal distribution.
It is especially useful for small sample sizes (\(n < 30\)) where visual inspections (e.g., histograms, Q-Q plots) may be less reliable.
Hypotheses for the Shapiro-Wilk Test
Null Hypothesis (\(H_0\)): The data follow a normal distribution.
Alternative Hypothesis (\(H_A\)): The data do not follow a normal distribution.
A low \(p\)-value (< 0.05) suggests that the data significantly deviate from normality.
A high \(p\)-value (> 0.05) suggests that the data does not significantly deviate from a normal distribution.
Shapiro-Wilk Test in R
In R this is conducted using:
shapiro.test(x = cholesterol$diff)
Shapiro-Wilk normality test
data: cholesterol$diff
W = 0.9616, p-value = 0.3402
This produces a non-significant \(p\)-value, meaning there is no strong evidence to suggest that the differences in cholesterol deviate from normality.
iClicker
Hypothesis Test for Cholesterol Reduction
Exercise 2 A nutritionist is investigating whether a new diet reduces cholesterol levels. She measures cholesterol levels before and after the diet for 30 participants.
What are the appropriate null and alternative hypotheses?
\(H_0: \mu_d = 0\), \(H_A: \mu_d \neq 0\)
\(H_0: \mu_d = 0\), \(H_A: \mu_d > 0\)
\(H_0: \mu_d = 0\), \(H_A: \mu_d < 0\)
\(H_0: \mu_d \neq 0\), \(H_A: \mu_d = 0\)
Test Statistic
\[\begin{align}
T &= \dfrac{\bar d - 0}{s_d/\sqrt{n}}
\end{align}\] which follows a \(t\)-distribution with \(\nu = n -1 = 29\) d.f. \[\begin{align}
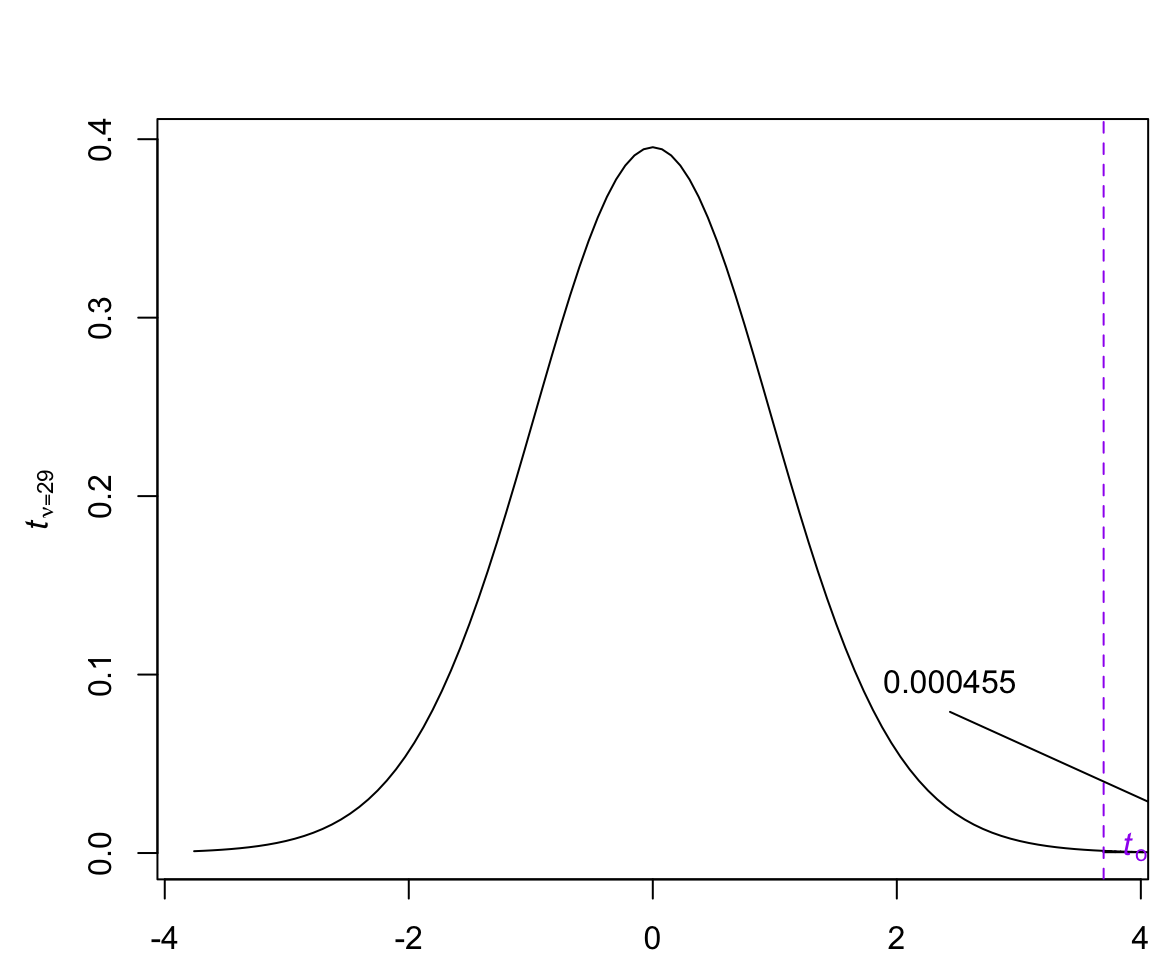
t_{obs} &= \dfrac{8.4066667}{12.4613315/\sqrt{30}} = 3.6950473
\end{align}\]
iClicker
t-critical
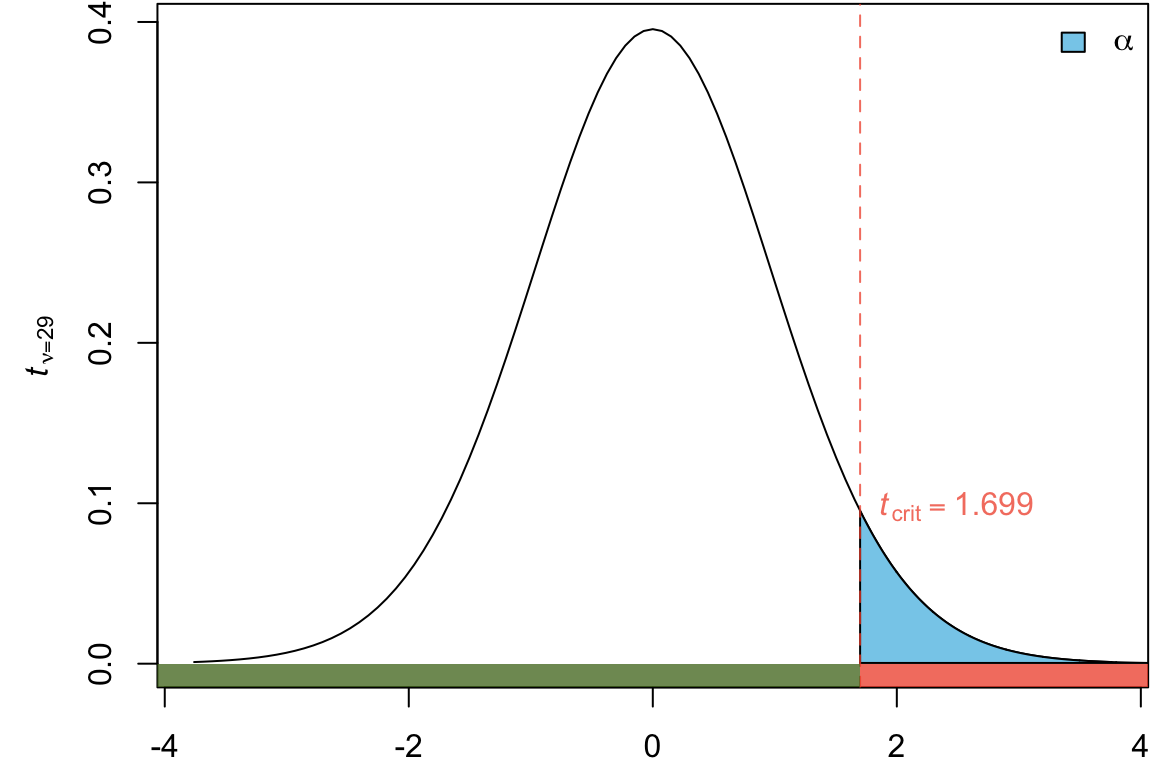
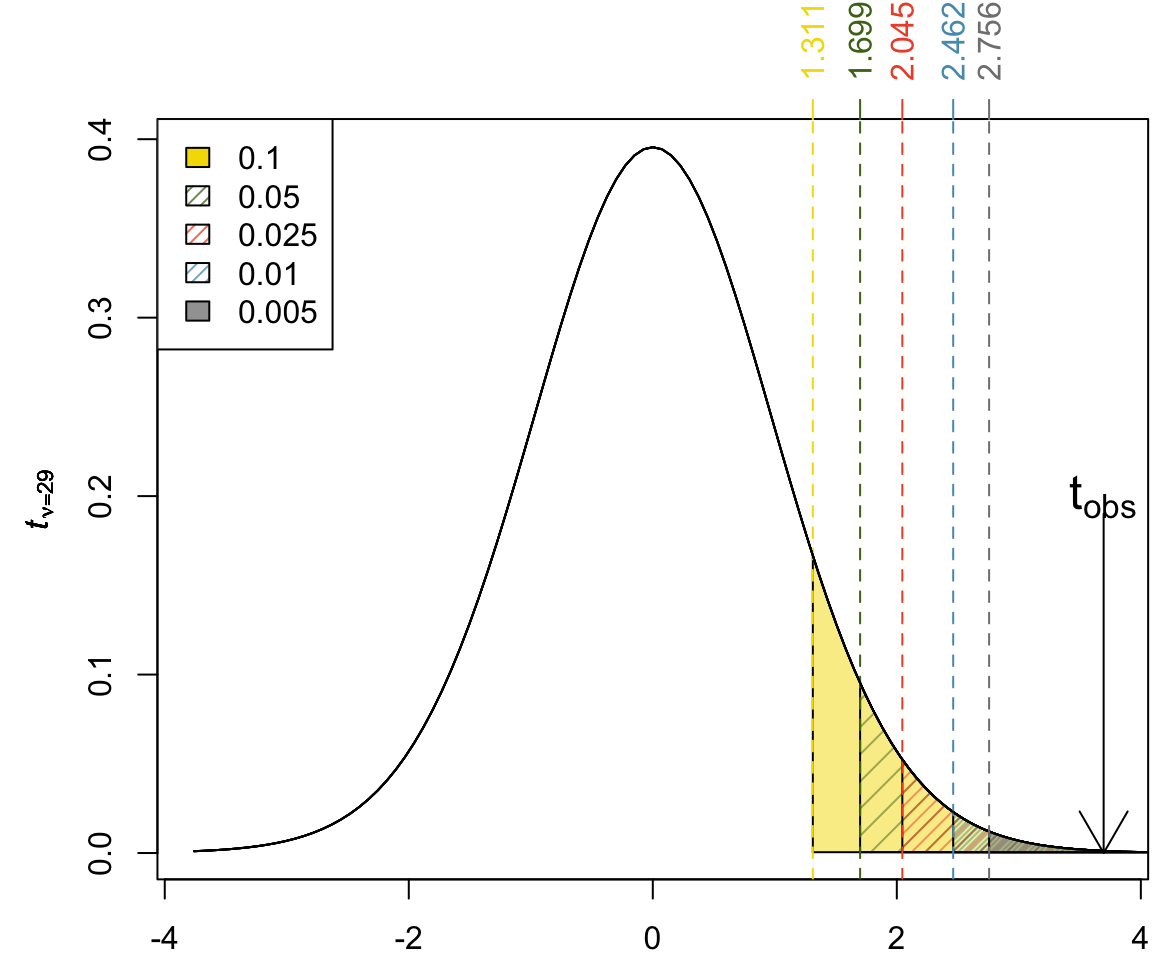
How do we calculate \(t_{crit}\), the critical value for the one-sided test.
The critical value can be found using the table t-table with \(\nu = 29\).
iClicker
Decision based on RR
Does \(t_{obs}\) fall in the rejection region?
Yes
No
iClicker
Determining the p-Value from t-Tables
Exercise 3 A paired t-test was conducted to determine whether a new diet reduces cholesterol levels. The test statistic was found to be \(t_{obs} = 3.6950473\) with \(n = 30\) participants. Using a t-table, what is the most accurate way to express the p-value?
alternative = "greater" is the alternative that x has a larger mean than y. For the one-sample case: that the mean is positive.
1t.test(x = before, y = after,2alternative ="greater",3data = cholesterol,4paired =TRUE)
1
\(H_0: \mu_{x} - \mu_{y} = 0\)
2
\(H_A: \mu_{x} - \mu_{y} > 0\)
3
Alternatively we could use x = cholesterol$before, y = cholesterol$after and leave data out.
4
Indicate the data is paired (i.e. matched)1
t-table output
t.test(x = cholesterol$before, y = cholesterol$after, alternative ="greater", paired =TRUE)
Paired t-test
data: cholesterol$before and cholesterol$after
t = 3.695, df = 29, p-value = 0.0004547
alternative hypothesis: true mean difference is greater than 0
95 percent confidence interval:
4.540953 Inf
sample estimates:
mean difference
8.406667
Comment
Note for the one-tailed test a one-sided 95% confidence interval1 is constructed.
Akin to the relationship between symmetric 95% CI and two-tailed tests, the one-sided confidence interval does provide a decision rule that aligns with the one-tailed test.
If the lower bound of the one-sided CI is below \(\mu_0\), we fail to reject\(H_0\).
If the lower bound is above \(\mu_0\), we reject\(H_0\).
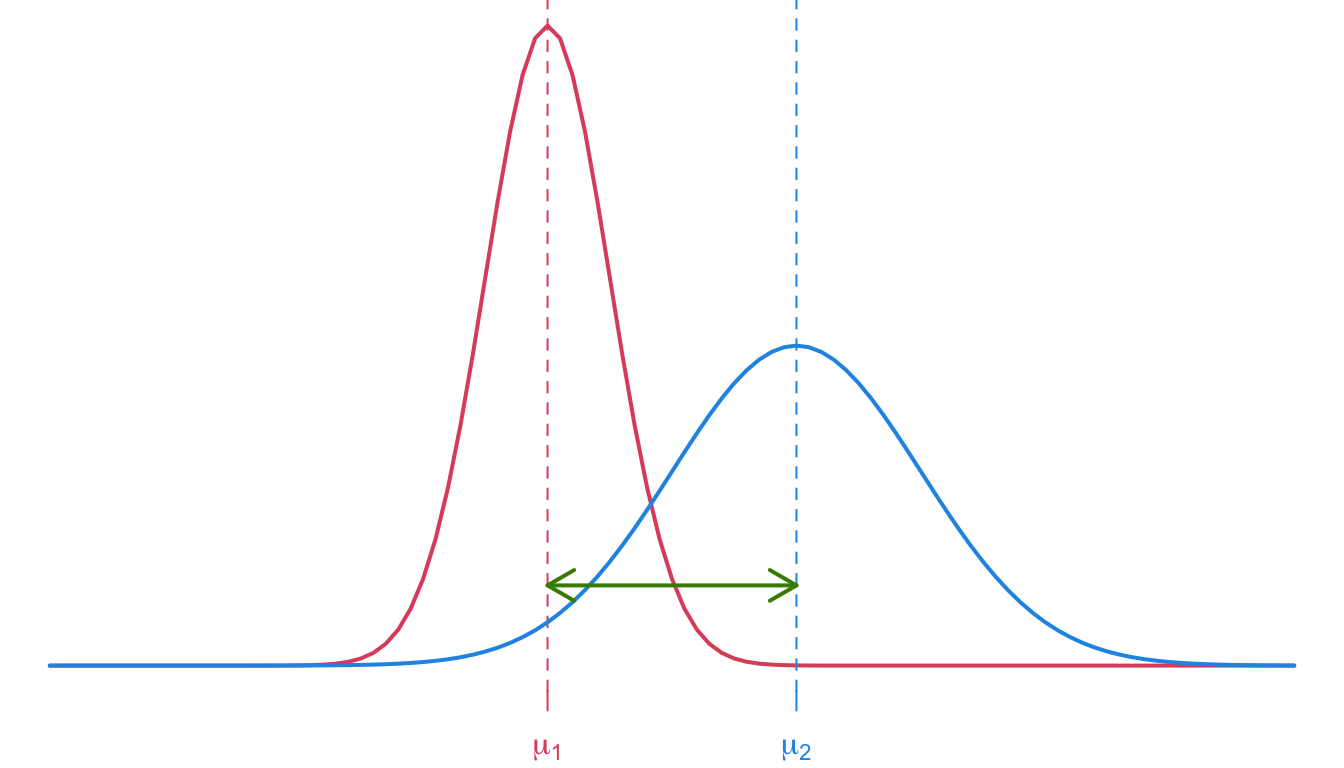
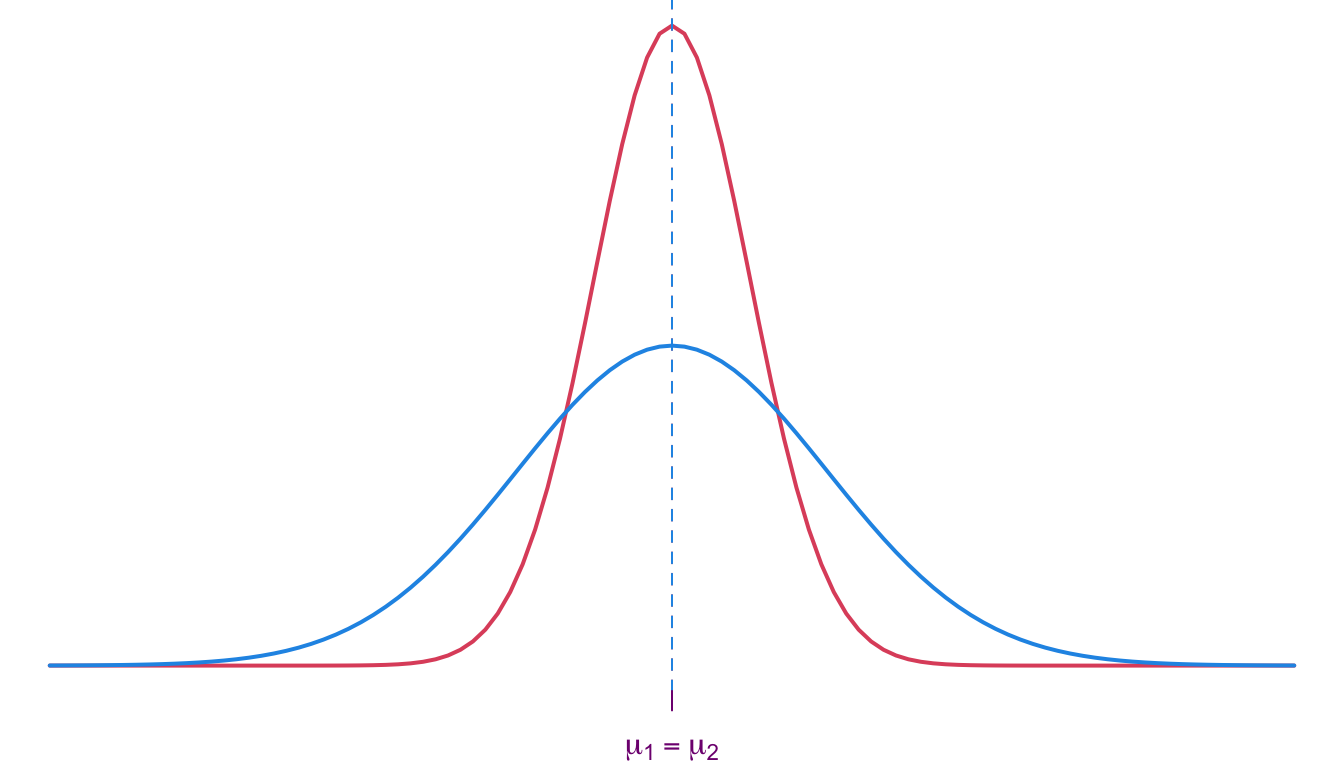
Independent Groups (equal variance)
Example
Chicken Feed
Exercise 4 An experiment was conducted to measure and compare the effectiveness of various feed supplements on the growth rate of chickens. Newly hatched chicks were randomly allocated into six groups, and each group was given a different feed supplement.
Data
The chickwts is one of the built-in dataset in R.
chickwts # see ?chickwts for more info
Summary Statistics
We will consider a subset of this data set corresponding to the chicks in the soymeal and meatmeal feed supplements.
Figure 5: Do these data provide statistically significant evidence that the average weights of chickens that were fed meatmeal and soybean are different?
Violin
Code
# Create violin plotvioplot(weight ~ feed, data = data, col ="lightblue", main ="Weight by Feed Type", xlab ="Feed Type", ylab ="Weight")# Add jittered pointspoints(jitter(as.numeric(data$feed)), data$weight, col ="red", pch =16)# Compute and add mean linesfeed_levels <-levels(data$feed)means <-tapply(data$weight, data$feed, mean) # Compute meansfor (i in1:length(feed_levels)) {lines(c(i -0.2, i +0.2), rep(means[i], 2), col =1, lwd =2, lty =2) # Add mean lines}
Checking Assumptions
Independence Within Observations: we a assume that these are a simple random sample of chickens (verified in details; see ?chickwts)
Independence Between Groups: we assume that the groups of chickens are unpaired.
Equal Variance Judging by the shapes of the side-by-side boxplot, it appears that the equal variance assumption is reasonable.
Equal variance assumption
If it is safe to assume \(\sigma^2_1 = \sigma^2_2\), we can carry out the pooled\(t\)-test. We therefore assume Group 1 \(\sim N(\mu_1, \sigma^2)\) and Group 2 \(\sim N(\mu_2, \sigma^2)\).
Pooled variance
To estimate this unknown population parameter \(\sigma^2\), we can use a single pooled estimate for this common variance \(\sigma^2\): \[\begin{equation}\label{eq:pooled}
s_p^2 = \frac{(n_1 - 1)s_1^2 + (n_2 - 1)s_2^2}{n_1 + n_2 -2}
\end{equation}\]
\(n_i\) is the sample size from Group \(i\) and
\(s_i\) sample standard deviation from Group \(i\).
Alternative, you may write your hypothesis in words:
\(H_0\): there is no difference in the long-run average weight of chickens fed with soymeal (\(\mu_1\)) compared to the long-run average weight of chickens fed with meatmeal (\(\mu_2\)).
\(H_A\): The long-run average weight of chickens fed with soymeal (\(\mu_1\)) is different than the long-run average weight of chickens fed with meatmeal (\(\mu_2\)).
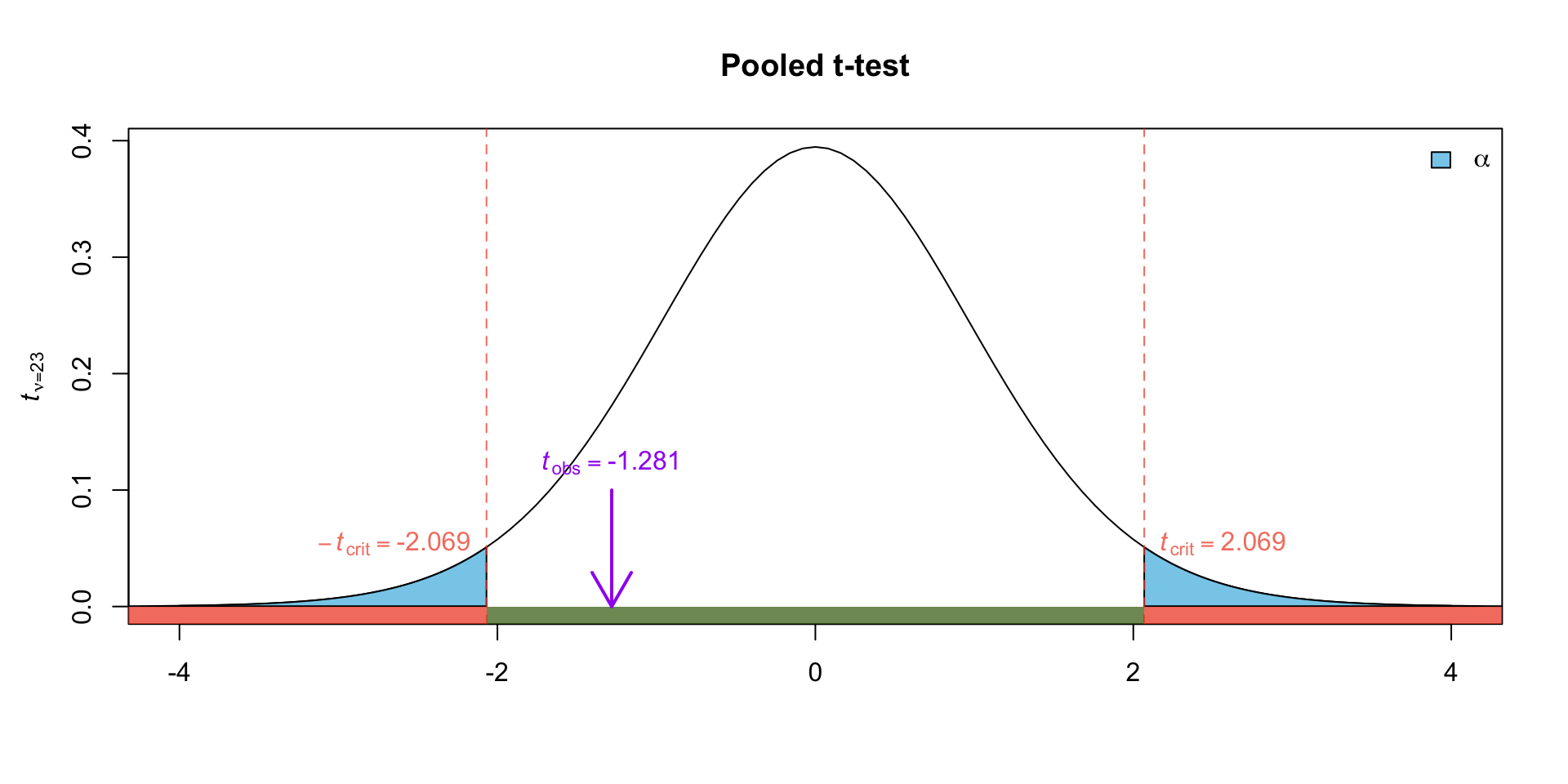
Plugging in our sample statistics and our pooled estimate we get our observed test statistic: \[\begin{equation}
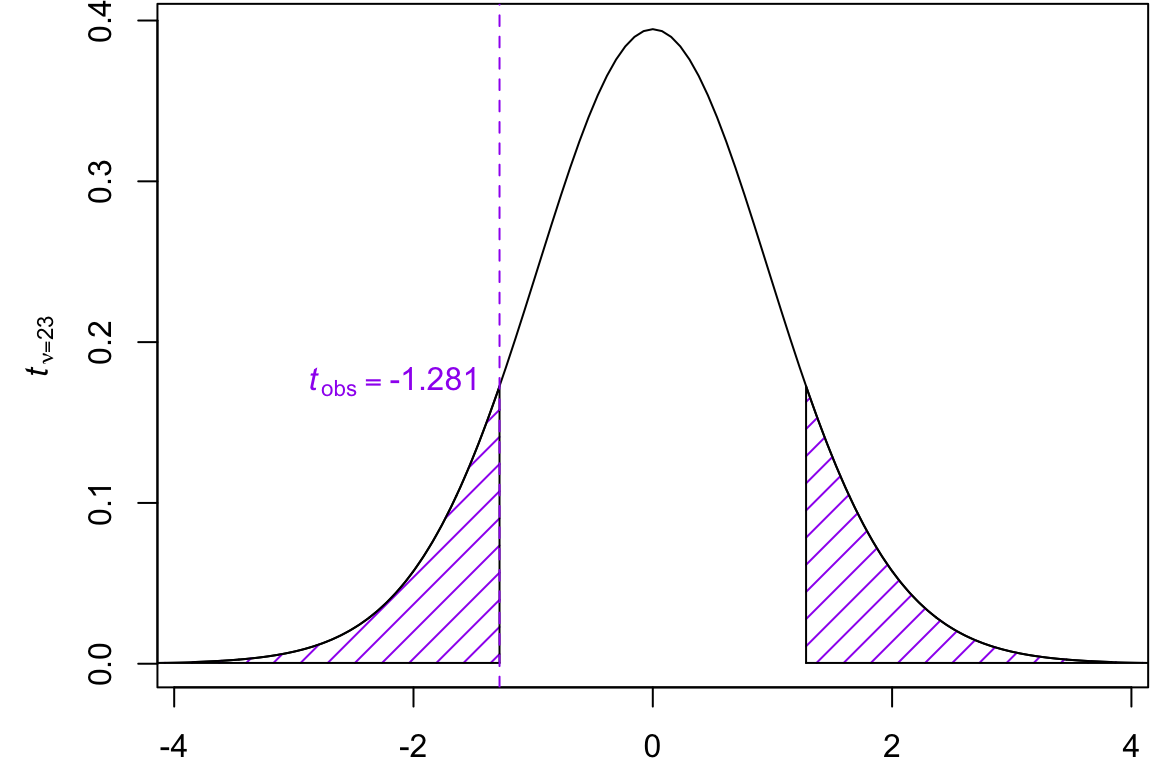
t_{obs} =\dfrac{246.43 - 276.91}{59.0544479\sqrt{\frac{1}{14} + \frac{1}{11}}} \approx -1.281
\end{equation}\]
Critical Value
The critical value can be found using the \(t_{\nu = 23}\) distribution.
Find the approximate \(p\)-value using the t-table. \(p\)-value = \[\begin{align}
&2 \Pr(t_{23} > |t_{obs}|) \\
&2\Pr(t_{23} > 1.281)
\end{align}\]
iClicker
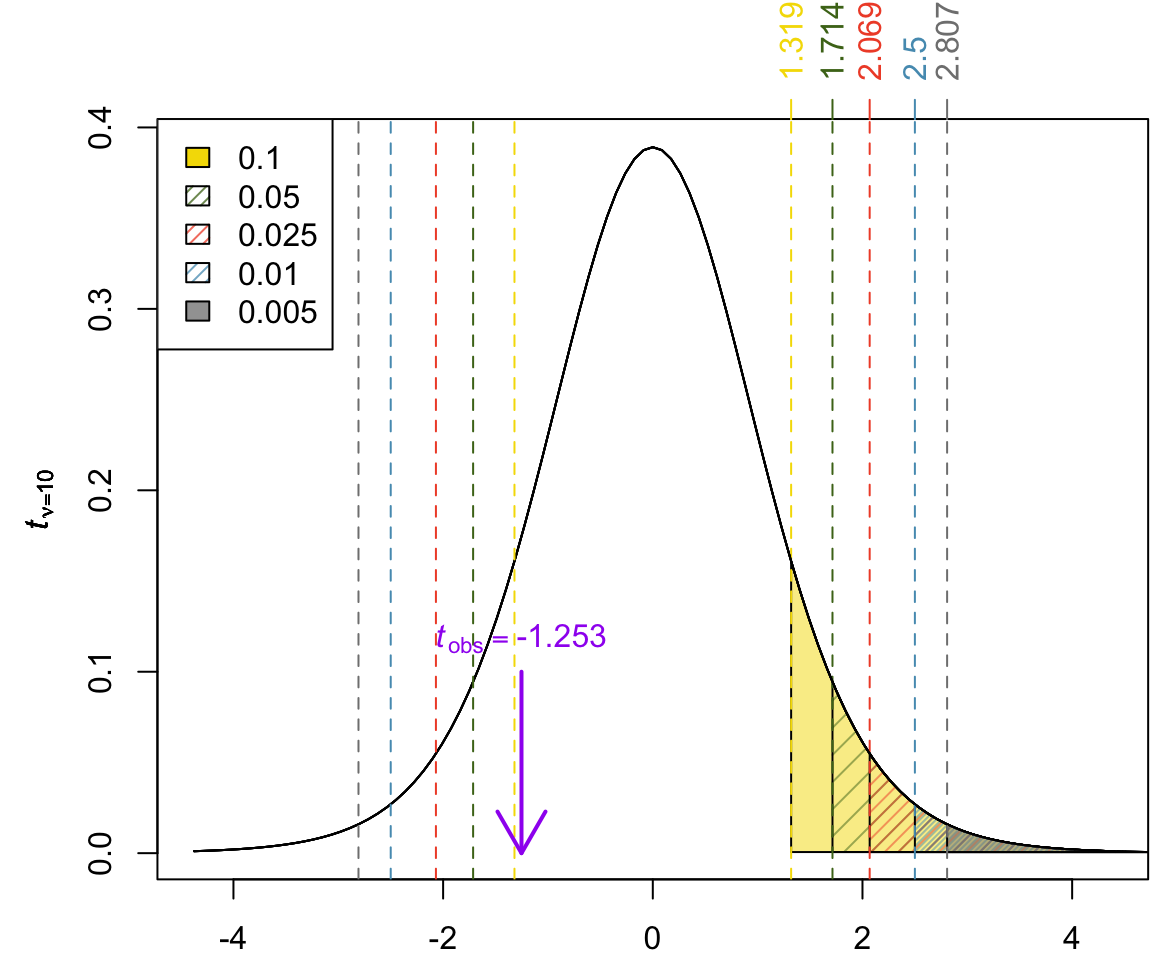
Determining the p-Value from t-Tables
The test statistic was found to be \(t_{obs} = -1.2810105\) with \(n = 30\) participants. Using a t-table, what is the most accurate way to express the p-value for the chicken feed example comparing soymeal and meatmeal?
Conclusion: there is insufficient evidence to suggest that the long-run average weight of chickens fed with soymeal is different than the long-run average weight of chickens fed with meatmeal.
we reject the null hypothesis in favour of the alternative.
. . .
Conclusion there is sufficient evidence to suggest that the long-run average weight of chickens fed with soymeal is different than the long-run average weight of chickens fed with meatmeal.
pooled t-test in R
t.test(soybean, meatmeal, var.equal =TRUE)
Two Sample t-test
data: soybean and meatmeal
t = -1.281, df = 23, p-value = 0.2129
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-79.70142 18.74038
sample estimates:
mean of x mean of y
246.4286 276.9091
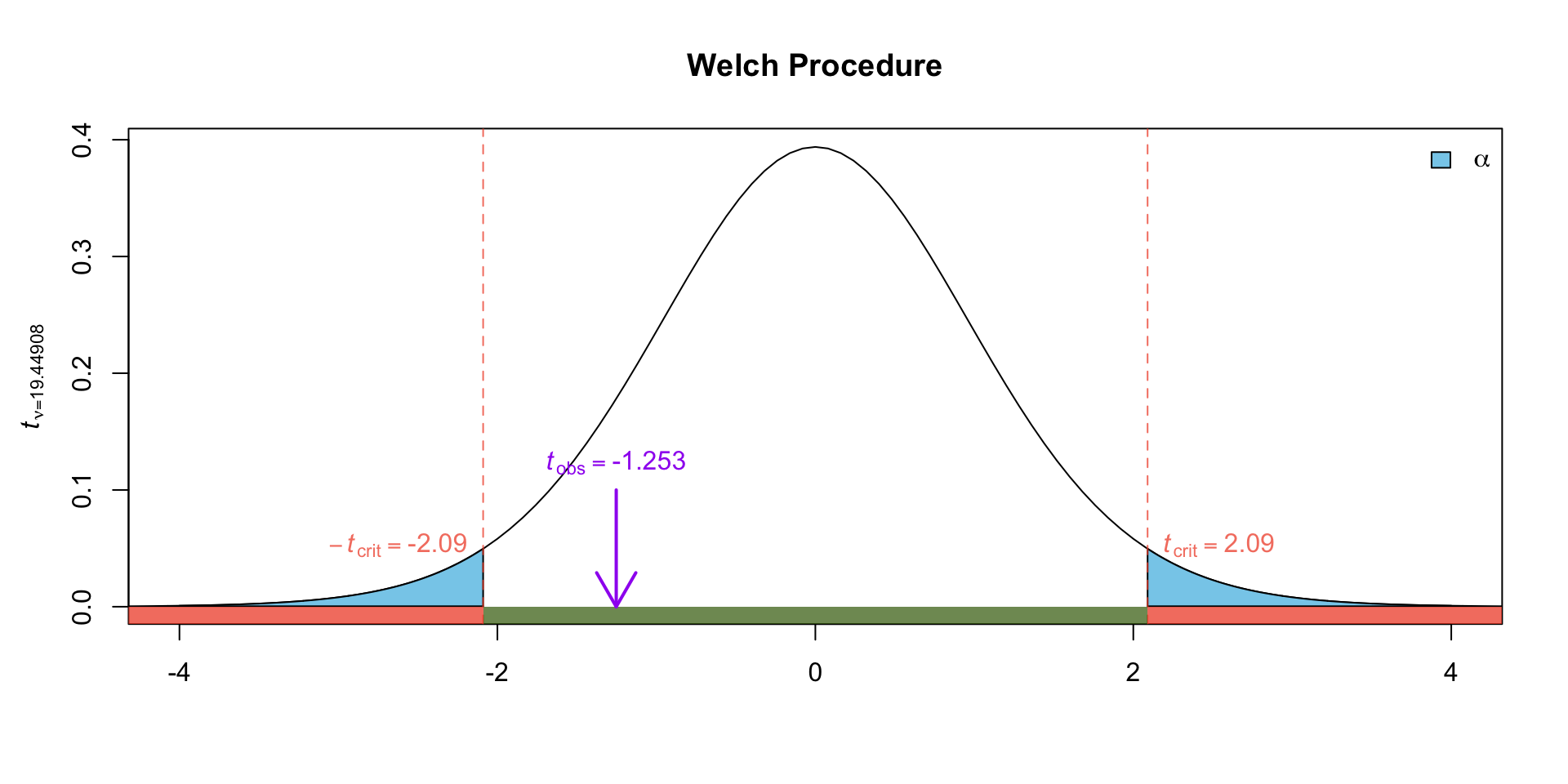
If it is not safe to assume \(\sigma^2_1 = \sigma^2_2\), we can carry out the Welch procedure (approximate \(t\)-test). We therefore assume Group 1 \(\sim N(\mu_1, \sigma_1^2)\) and Group 2 \(\sim N(\mu_2, \sigma_2^2)\).
Welch Procedure
The Welch procedure is similar to the pooled \(t\)-test, however the test statistic is an approximation even for normal populations (rather than an exact result).
More importantly, the Welch procedure does not require the assumption of equal population variances.
While the assumption of equal variance appears reasonable based on the boxplot in Figure 5, let’s carry out the Welch procedure to highlight the difference.
Hypotheses and Test statistic
The null and alternative hypothesis will be the same as stated before. The test statistic is now:
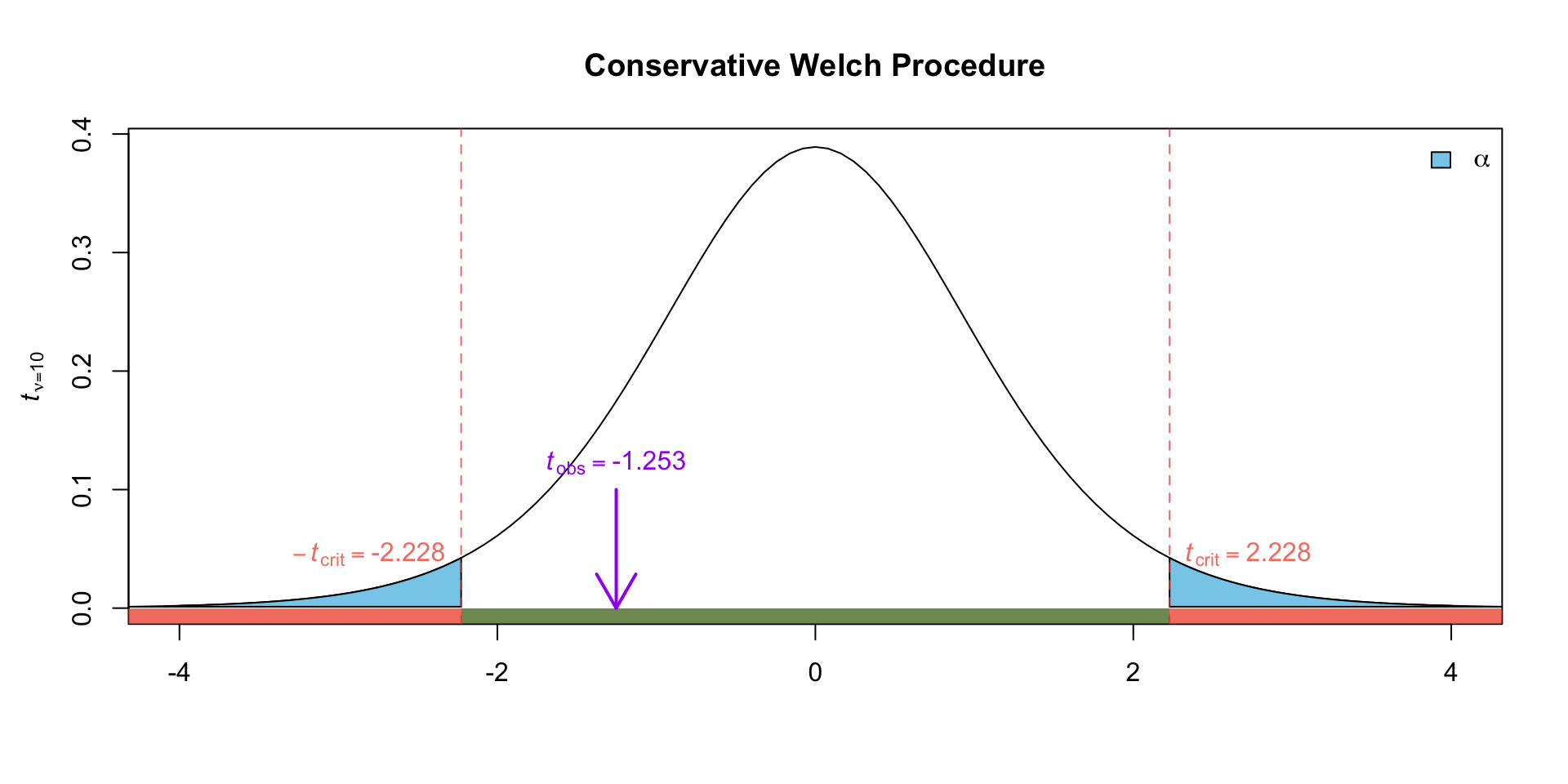
The calculation on the previous page is extremely tedious to do on paper. On a test where you don’t have access to software like R, you may use the following conservative estimate:
Conservative degrees of freedom for Welch’s Procedure
A conservative estimate for the degrees of freedom for the Welch procedure is
\[ \tilde \nu_w = \min(n_1 -1, n_2-1)\]
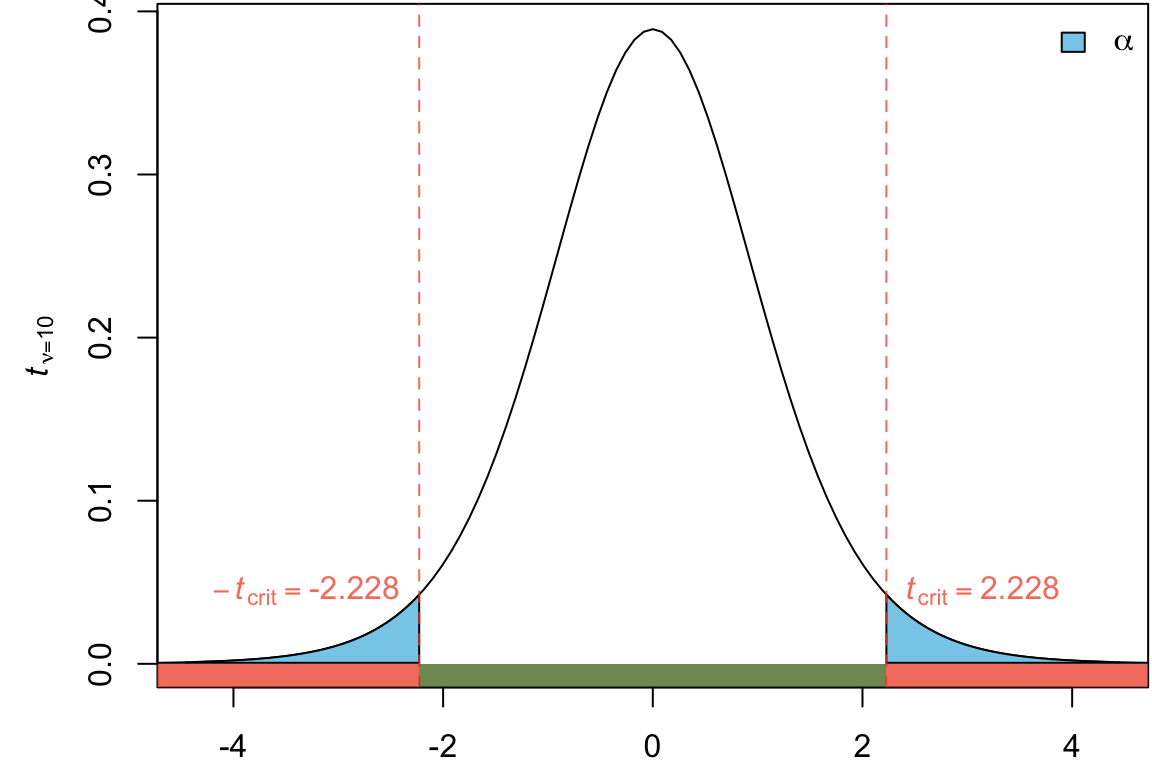
Here our \(\tilde \nu_w = \min(14 -1, 11-1) = 10\)
We can find the approximate \(p\)-value using the t-table with the conservative df \(\tilde \nu_w = 10\)\[\begin{align}
p\text{-value} =
2\Pr(t_{10} > 1.281)\\
p-value > 0.20
\end{align}\]
Welch Two Sample t-test
data: soybean and meatmeal
t = -1.2525, df = 19.449, p-value = 0.2252
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-81.33511 20.37407
sample estimates:
mean of x mean of y
246.4286 276.9091
Comments about Welch
While the differences were not dramatic in these examples, when the underlining variances \(\sigma_1^2\) and \(\sigma_2^2\) are very different, we begin to see more discrepancy between the solutions.
The Welch procedure is a more versatile and robust option in many real-world scenarios, since it has one less assumption than the pooled \(t\)-test (which requires \(\sigma_1 = \sigma_2\))
Recall, however, that the Welch procedure is only an approximate procedure. Hence, you should perform the exact pooled \(t\)-test instead whenever appropriate.
Comments about Pooled
If in fact \(\sigma_1 = \sigma_2\), pooling the standard deviation in the pooled \(t\)-test allows for a more precise estimation of the standard deviation for each group.
Another benefit is that the pooled \(t\)-test uses a larger degrees of freedom parameter for the t-distribution (which will lead to narrower CI, and more powerful test)
Both of these changes may permit a more accurate model of the sampling distribution of \(\bar X_1 - \bar X_2\), if the standard deviations of the two groups are indeed equal.
Guidelines
While formal hypothesis tests for equal variance exist1, one general rule of thumb2 is that if the sample sizes are similar we will require that the variance of one group to be more double the other in order to use the pooled estimate. In other words:
\[
0.5 < \frac{s_1}{s_2} < 2
\]
Summary
Tests for the difference of population means, i.e. \(H_0: \mu1 - \mu_2 = \delta_0\). All require the normality assumption (which is not very important is the sample sizes are large) and a a simple random sample from the population.











Comment
Note that the slightly different numbers is due to rounding. You can get the exact numbers using the following code: