Lecture 6: Confidence Intervals for Means and Proportions
STAT 205: Introduction to Mathematical Statistics
Dr. Irene Vrbik
University of British Columbia Okanagan
Introduction
Last lecture used the MM and MLE to derive point estimates (e.g. \(\bar x\), \(s^2\), \(\hat \beta\)) for population parameters (e.g. \(\mu\), \(\sigma^2\), \(\beta\)) .
A single estimate does not provide information about the reliability or uncertainty associated with the estimator.
Since the sampling distribution tells us how much the sample statistic (e.g., \(\bar{X}\)) varies from sample to sample, we can use it to construct an interval that likely contains the true population parameter.
Outline
Using our knowledge of sampling distributions we derive:
Confidence intervals for \(\mu\)
Confidence intervals for \(p\)
Confidence intervals for \(\sigma^2\)
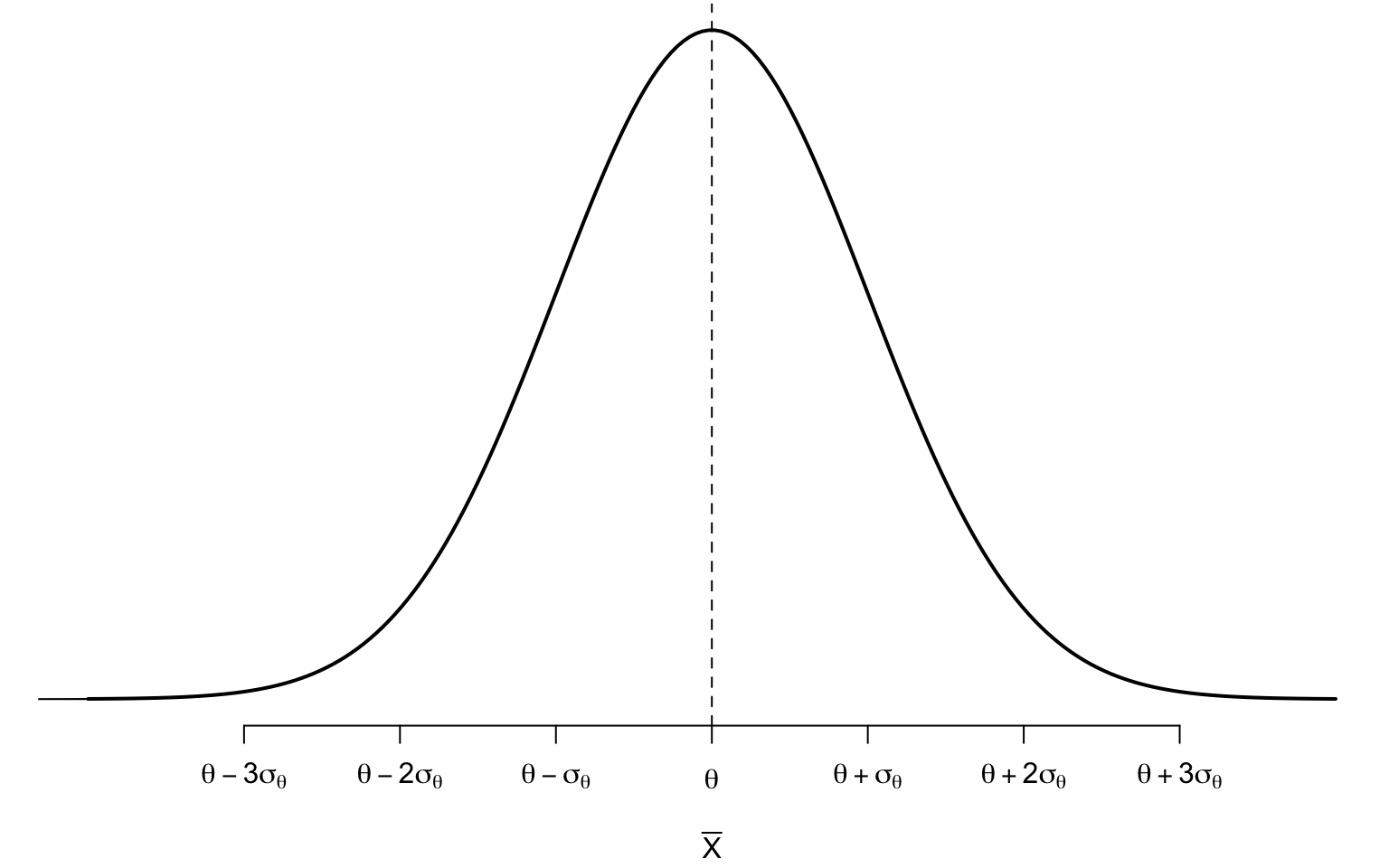
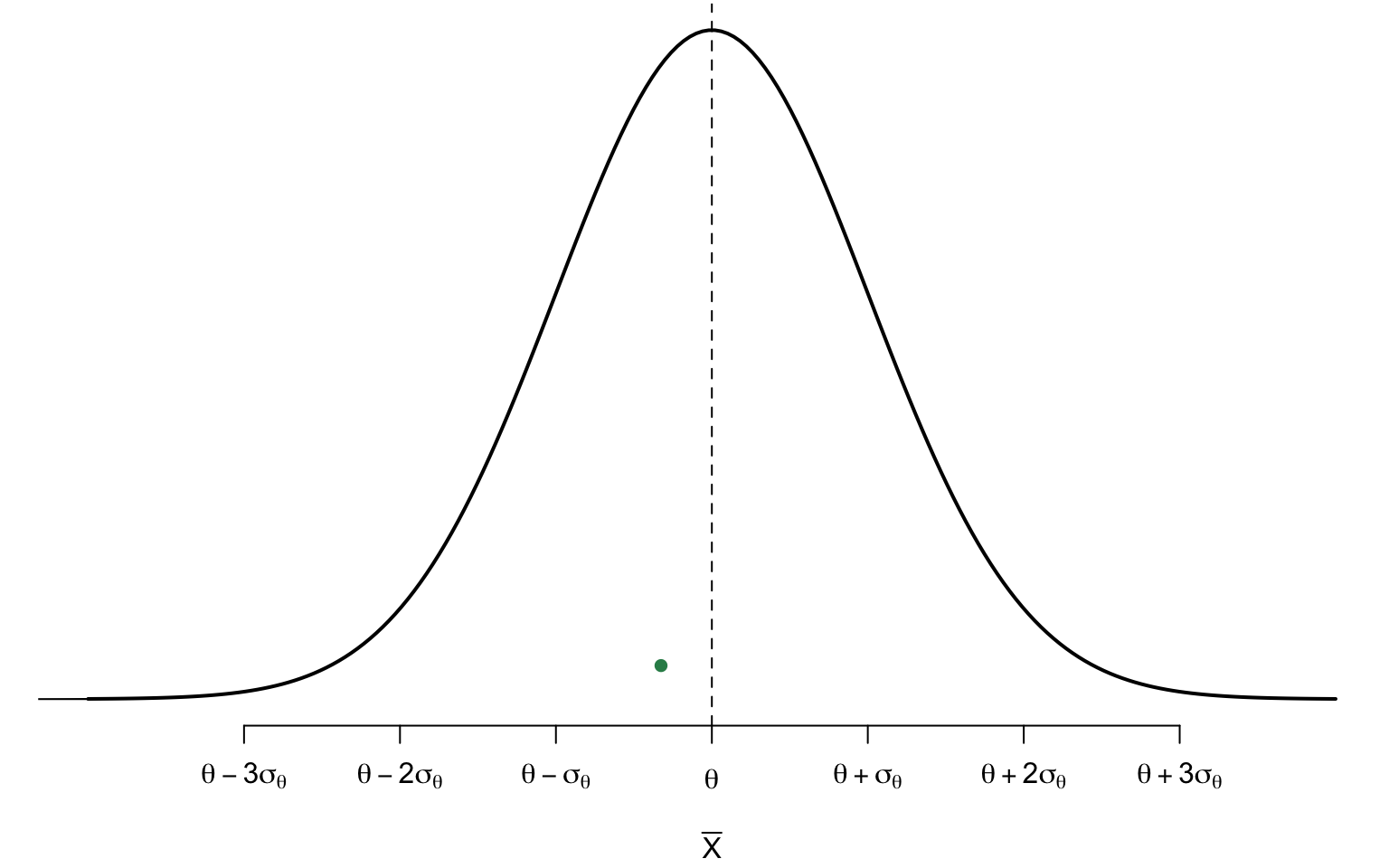
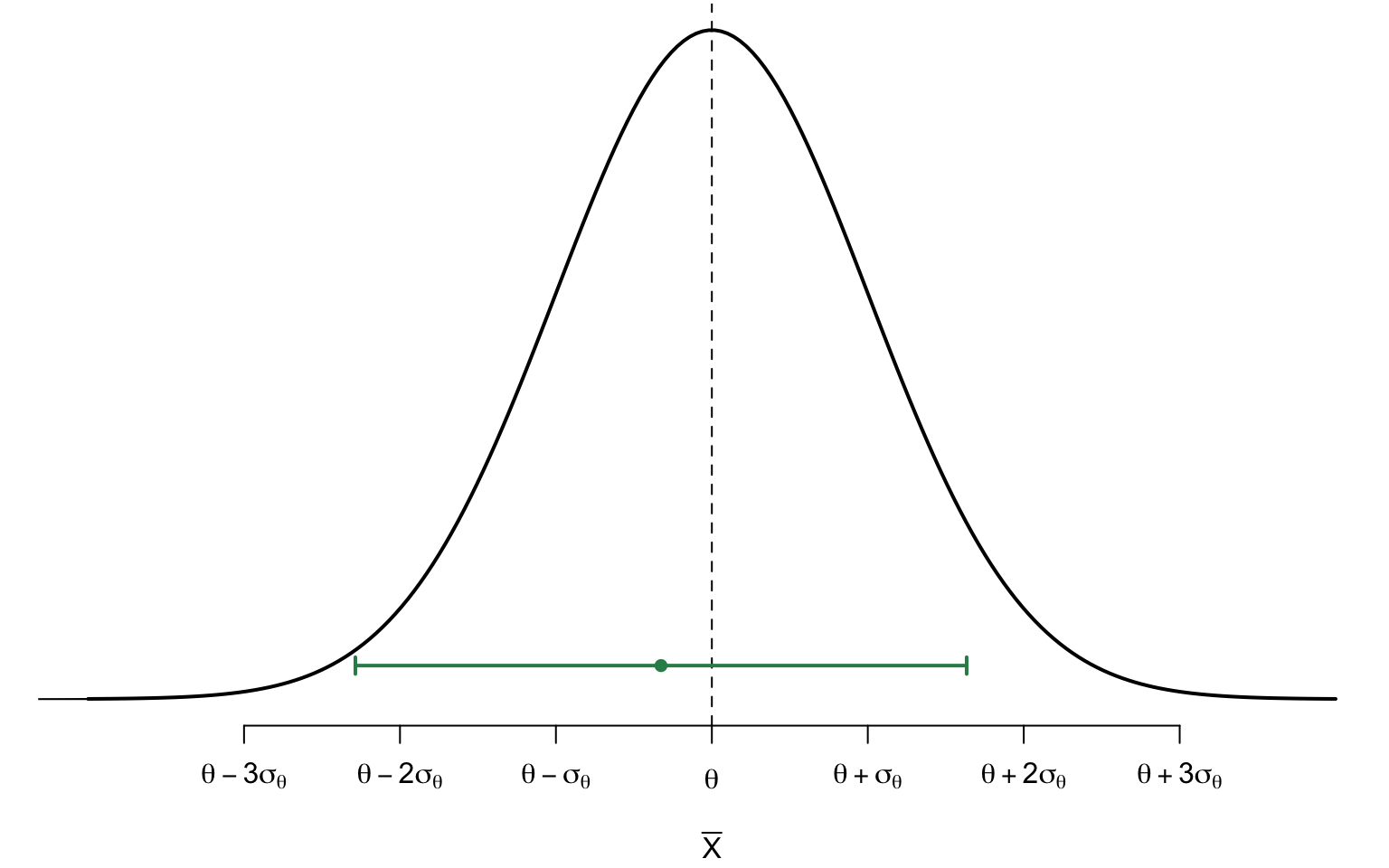
Confidence Interval
A confidence interval (CI) provides an interval or range of plausible values for the population parameter.
It is constructed using a sample statistic and its sampling distribution.
CI provides some prescribed degree of confidence (C) of securing the true parameter (typically 90%, 95%1, or 99%)
A higher confidence level results in a wider interval.
Comments
\(L\) and \(U\) will be used to denote1 the lower and upper confidence limits, respectively.
For this interval \((L, U)\) to be useful,
the true population parameter \(\theta\) should have a high probability of falling between \(L\) and \(U\)
the length of the interval should be relatively narrow
Garfield Comic Strip
Normal Distribution
For the normal distribution, 95% of observations are within 1.96 standard deivations of the distribution’s center.
Constructing confidence intervals
Using this principle, if a point estimator can be modeled using a normal distribution, we can construct a plausible range of values for a parameter by looking with 1.96 standard errors1 of the point estimate.
\[
\text{point estimate} \pm 1.96 \times SE
\]
where SE stands for the standard error of the point estimate.
A \(100(C)\)% confidence interval for \(\mu\) is given in the form
\[
\begin{align}
\bar{x} \ &\pm m & \text{ or} \\
(\bar{x} - m &, \bar{x} + m)
\end{align}
\]
where \(m\) is called the margin of error given by \(z^* \sigma/\sqrt{n}\)
\(z^*\) is the value such that \(P(-z^* < Z < z^*) = C\)
Finding z*
To find the \(z^*\) in R, you can use the qnorm() function
alpha =0.05qnorm(1-alpha/2)
[1] 1.959964
While the lower z-critical score is just the negative version of the number calculated above, for demonstration purposes lets also compute it in R:
qnorm(alpha/2)
[1] -1.959964
From a table ..
iClicker: finding \(z^*\)
What is the \(z^*\) for a 98% confidence interval?
2.33
2.05
2.58
None of the above
Note
The sign of the \(z^*\) doesn’t matter since the standard normal is a symmetric distribution about 0
Warning
Warning
For this CI to be exact, we must have the following:
The sample data must be a simple random sample from the population of interest
The population must be normally distributed
When it is not guaranteed that our population is normal, this interval is approximate for large \(n\) (thanks to the CLT)
Why “confidence”
Once the sample is observed, i.e. \(\overline{X} = \overline{x}\) and no longer a RV, the confidence interval becomes a fixed range of values.
Since the parameter is also considered fixed, there is no more randomness associate with this interval and it either contains the true population parameter or it doesn’t.
Confidence
We use confidence rather than probability when describing CIs.
e.g. we are 95 percent confident that the true population mean lies within \(1.96\cdot \frac{\sigma}{\sqrt{n}}\) of the observed sample mean.
Each row of points is a sample from the same normal distribution. The colored lines are 50% confidence intervals for the mean, μ. At the center of each interval is the sample mean, marked with a diamond. The blue intervals contain the population mean, and the red ones do not. [Source: wikipedia (Confidence interval, 2024)]
Comments
When \(\overline{X}\) is still a random variable, we can interpret a confidence interval in terms of probability.
The confidence level (e.g., 95%) represents the probability that the interval, if constructed repeatedly from different samples, will contain the true parameter.
100 95% CI based on 100 samples from a normal population with mean \(\mu\) and variance \(\sigma\). In theory 95% of them will contain the true value of μ. For this particular run, only 4 CI did not contain the true value of \(\mu\)
Example: SAT
95% Confidence Interval for the Population Mean
Suppose at a large high school, the seniors take the SAT exam. We draw a random sample of 10 of these students, and obtain their scores on the exam. These 10 students had a mean score of 1580. Construct a 95% confidence interval for the true mean SAT score of all seniors at this high school.
Important
Note: because this is a small sample size, before we take our CI we need to as ourselves if its reasonable to assuming a normal population.
Solution
Interpretation of CI
Assuming a normally distributed population and simple random sample from all senior SAT writers at this school, an interpretation of the interval is as follows:
✅ We can be 95% confident that the true mean SAT score of all senior writers at this school lies between 1431 and 1729.
Wrong interpretations
❌ We can be 95% confidence that the true mean SAT score of 10 sampled students, falls within the range of 1431 to 1729.
Important
It’s essential to note that the confidence interval pertains to a population parameter (here \(\mu\)), not a statistic (\(\bar {X}\)).
Wrong interpretations
❌ 95% of senior SAT writers at this school have SAT scores that lie between 1431 and 1729.
implies a level of certainty about individual scores, confidence interval for the mean does not inform us about the proportion of the population that lies withinthe interval.
Recall
Sampling distribution for sample proportions
When observations are independent and the sample size is sufficiently large1, the sample proportion \(\hat p\) is given by
where \(z^* = P(Z>\alpha/2)\) (or \(z_{\alpha/2}\)) for \(Z\sim N(0,1)\).
Notation
The confidence level is given by \(C = 1-\alpha\)
e.g. when \(\alpha = 0.02\), our confidence level is 98%
While a confidence level of 0.95 is quite standard, sometimes the problem will necessitate a higher level of confidence
To find the \(z^*\) value that satisfies this formula, we could either use standard normal tables or software like R.
\(100(C)\%\) Confidence Interval for a Population Proportion
Let \(X_1, \dots, X_n\) be a random sample from a population where each observation is binary (success/failure). A \(100(C)\%\) confidence interval for the population proportion\(p\) is given in the form:
\[\hat{p} \pm m \quad \text{or} \quad (\hat{p} - m, \hat{p} + m)\]
where \(m\) is called the margin of error, given by:
\(z^*\) is the critical value from the standard normal distribution such that:
\[P(-z^* < Z < z^*) = C\]
where \(C\) is the confidence level and \(n\) is the sample size.
Assumptions for validity
The assumptions for CI are the same as that for the sampling distribution of \(\hat p\)
Random Sampling: The sample must be representative of the population.
Normal Approximation: The sample size should be large enough for the normal approximation to hold, which typically requires: \(n\hat p \geq 10\) and \(n(1-\hat p) \geq 10\)
ChatGPT example
Exercise: Use of ChatGPT
In a November 2023 research survey conducted by Pew Research about 13% of all U.S. teens have used the generative artificial intelligence (AI) chatbot in their schoolwork. This survey was conducted online from Sept. 26 to Oct. 23, 2023 and sampled 1,453 U.S. teens ages 13 to 17 who live with their parents by age, gender, race and ethnicity, household income, and other categories. Construct a 95% confidence interval for the population proportion based on this sample.
Solution
Margin of Error (m)
For the sample mean \(\overline{X}\),
\[
m = z^*\frac{\sigma}{\sqrt{n}}
\]
For the sample proportion \(\hat{p}\),
\[
m = z^*\sqrt{\frac{p(1-p)}{n}}
\]
The margin of error is a measure of the precision or uncertainty associated with the estimate derived from a sample. It is affected by \(n\) and \(z^*\).
For the same confidence level \(1-\alpha\) as \(n\) increases the CI will get narrower
For the same data as the confidence level \(1-\alpha\) increases the CI get wider
For \(\overline{X}\) as \(\sigma\) gets larger the CI get wider
For \(\hat p\), the narrowest CI is when \(p\) = 0.5
Width of CI
The width of the CI (\(U - L\)) is a directly related to the margin of error (the smaller the better!)
To accomplish this, the CI is constructed around the peak (center) of the sampling distribution such that \(\alpha/2\) appear in both tails.
This ensures that we capture the most likely values while keeping the interval as narrow as possible.
Two 95% intervals on the standard normal distribution. The one shaded in blue extends from [-1.96, -1.96] and has a width of 3.92 one shaded in yellow extends from [-1.78,-1.78] and has a width of 4.02.
One-sided CI
As an extreme case, we might talk about one-sided CI, such that the entire \(\alpha\) probability is placed in either the lower or upper tail.
Example: Exclusive Relationships
A random sample of 50 college students were asked how many exclusive relationships they have been in so far. This sample yielded a mean of 3.2 and a standard deviation of 1.74. Estimate the true average number of exclusive relationships using this sample.
When the sample is not drawn from a normal distribution, this result is approximate (thanks to the CLT) under certain conditions:
Independence: The observations in the sample must be independent.
Sample Size: The sample size should be reasonably large.
CI for \(\mu\) (\(\sigma\) unknown)
100(C) Confidence Interval (unknown \(\sigma\))
Let \(X_1, \dots, X_n\) be a sample from a normal population then a \(100(C)\)% confidence interval for \(\mu\) is given in the form
\[
\begin{align}
\bar{x} \ \pm m \quad\quad\text{ or} \\
(\bar{x} - m , \bar{x} + m)
\end{align}
\]
where \(m\) is called the margin of error given by \(t^* + s/\sqrt{n}\)
\(t^*\) is the value such that \(P(-t^* < t_{\nu} < t^*) = C\) where \(\nu = n-1\) and \(n\) is the sample size.
Conditions for using \(t\)
Conditions for using the t-distribution
The conditions for using the t-distribution are as follows:
Random Sampling: The data should be collected through a process of random sampling or a process that mimics random sampling.
Independence: The observations in the sample must be independent of each other.
Approximate Normality or Sufficiently Large Sample: While the t-distribution is robust to deviations from normality, it works best when the sample size is reasonably large (typically \(n \geq 30\) ).
Note: If the sample size is small and the population distribution is heavily skewed or has heavy tails, using the t-distribution might not be appropriate.
Returning to our example…
Example: Exclusive Relationships
A random sample of 50 college students were asked how many exclusive relationships they have been in so far. This sample yielded a mean of 3.2 and a standard deviation of 1.74. Estimate the true average number of exclusive relationships using this sample.
Always round down1 to the nearest available df in the table to ensure the confidence level is at least as high as desired. Rounding up may underestimate the critical value, leading to a less conservative interval.
Which of the following is the correct interpretation of this confidence interval. We are 95% confident that…
the average number of exclusive relationships college students in this sample have been in is between 2.7 and 3.7.
college students on average have been in between 2.7 and 3.7 exclusive relationships.
a randomly chosen college student has been in 2.7 to 3.7 exclusive relationships.
95% of college students have been in 2.7 to 3.7 exclusive relationships.
Example:
Example: fecundity
A study investigated per diem fecundity (number of eggs laidper female per day for the first 14 days of life) for a strain of Drosophila melanogaster. Per diem fecundity was measured for 25 females, and the results are listed below. Calculate the appropriate 95% CI.
Plot to assess the normality of the data before calculating the confidence interval. This is necessary to determine whether using a t-distribution for constructing the confidence interval is appropriate.
QQplot
A QQ plot, or Quantile-Quantile plot, is a graphical tool used to assess whether a dataset follows a particular theoretical distribution, often the normal distribution. It compares the quantiles of the observed data to the quantiles of a specified theoretical distribution.
For a normal distribution, the QQ plot would ideally show points forming a straight line along the line of equality. Deviations from the line suggest departures from normality.
The sample size is 25, which yields \((n - 1 = 25 - 1 = 24)\) degrees of freedom. From the table or software, we can find that \(t_{24}(0.025) = 2.064\) The standard error is \[
\hat \sigma_{\bar{X}}
= \frac{s}{\sqrt{n}}
= \frac{8.9420132}{\sqrt{25}}
= 1.7884026 \approx 1.788
\]
Putting these values into the confidence interval formula: \[
\begin{align}
&\bar{X} \pm t^*\cdot SE(\bar{X}) \\
&= 33.372 \pm 2.064 \times 1.788 \\
&= 33.372 \pm 3.691
\end{align}
\] Which works out to approximately (29.7, 37.1).

















Comments
\(L\) and \(U\) will be used to denote1 the lower and upper confidence limits, respectively.
For this interval \((L, U)\) to be useful,