
Main Idea
Premise: \(m_k'\) should provide good estimates of the corresponding population moments \(\mu_k'\).
e.g. the sample mean (aka the first sample moment \(m'_1 = \frac{1}{n}\sum_{i=1}^n X_i\)) should provide a good guess for the population mean (aka the first population moment \(\mu_1' = \mathbb{E}[X^1]\)
similarly \(m'_2 = \frac{1}{n}\sum_{i=1}^n X_i^2\) provides a good guess for the second population moment \(\mu'_2 = \mathbb{E}[X^2]\)


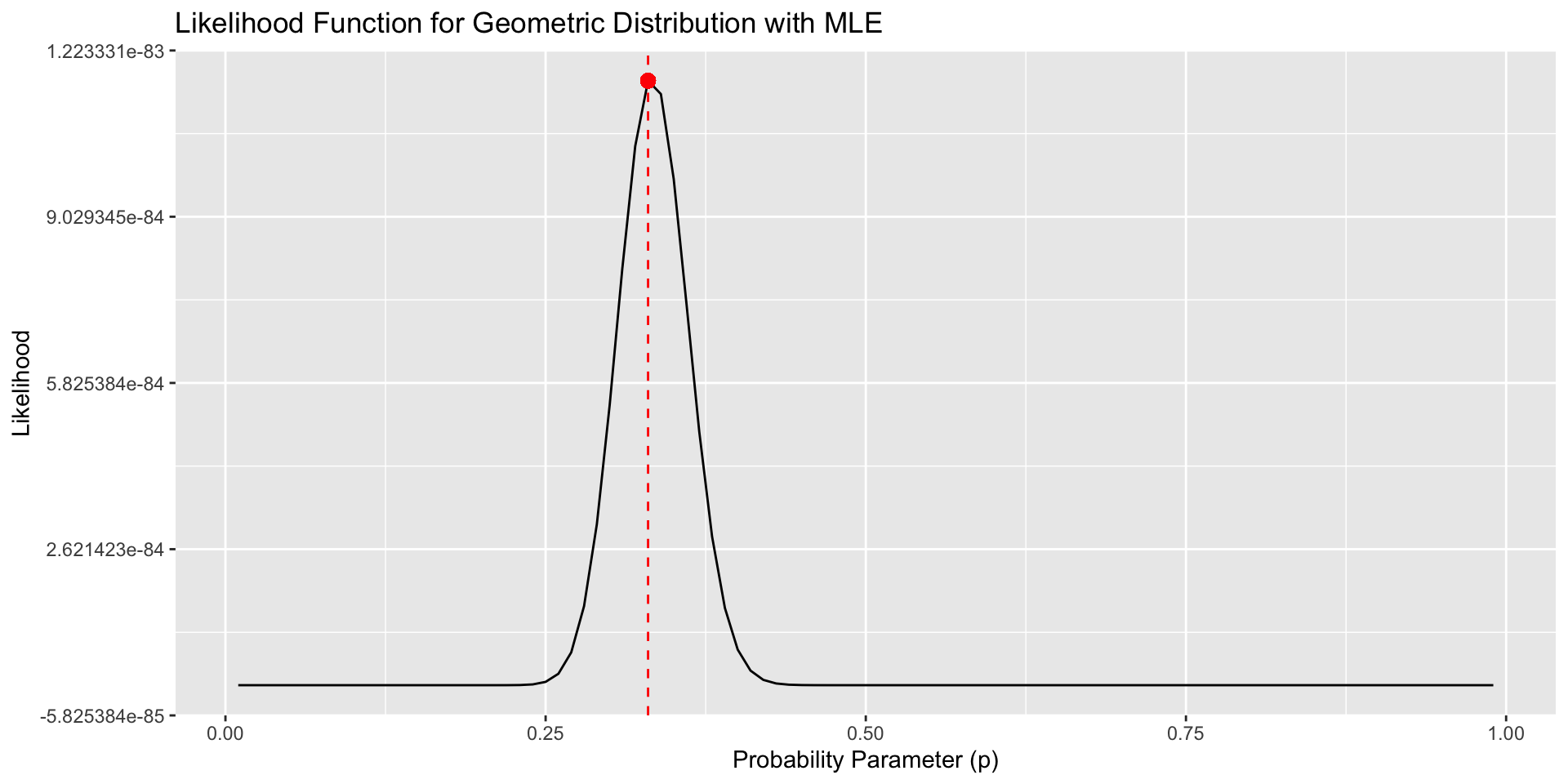
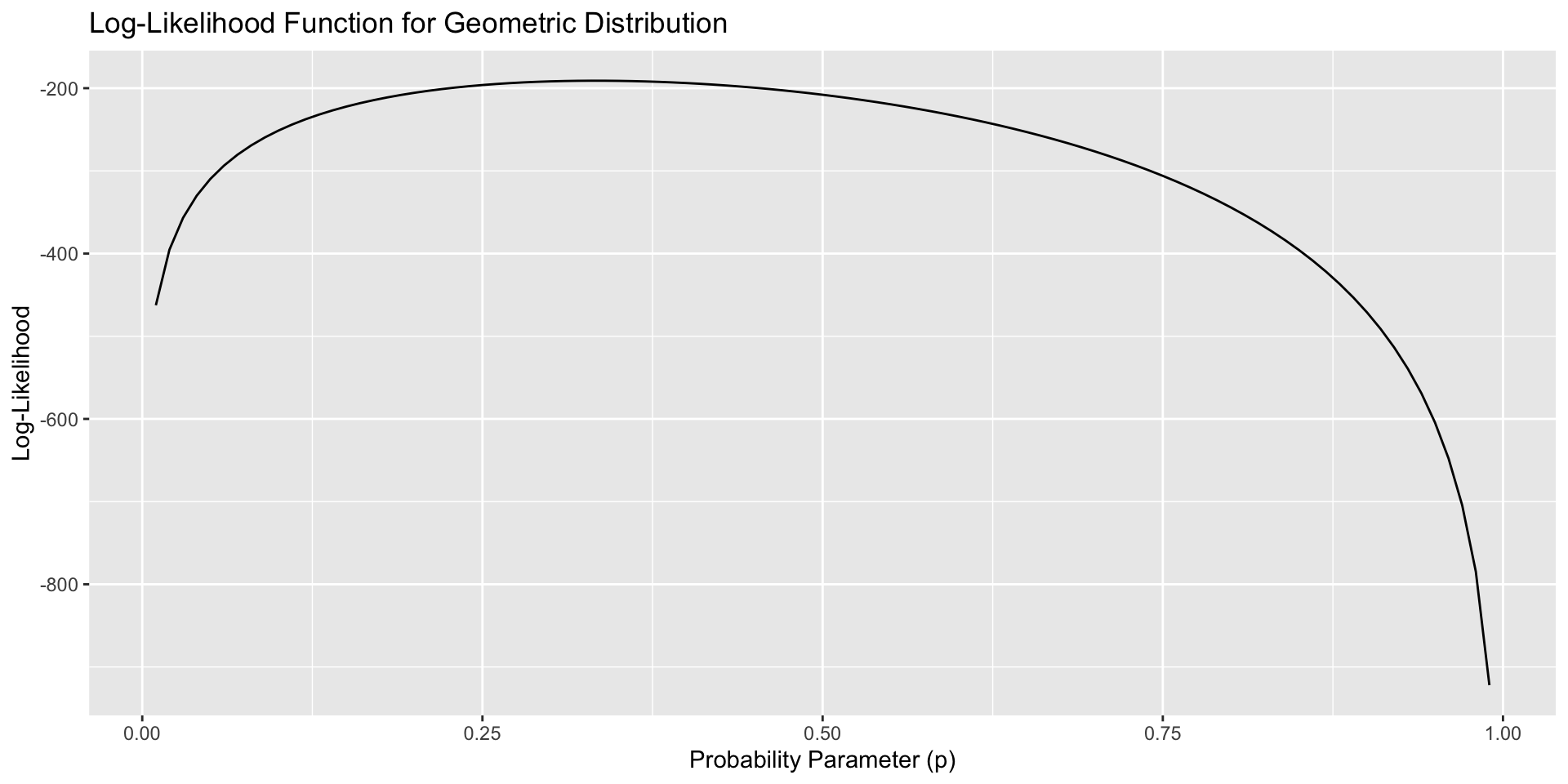
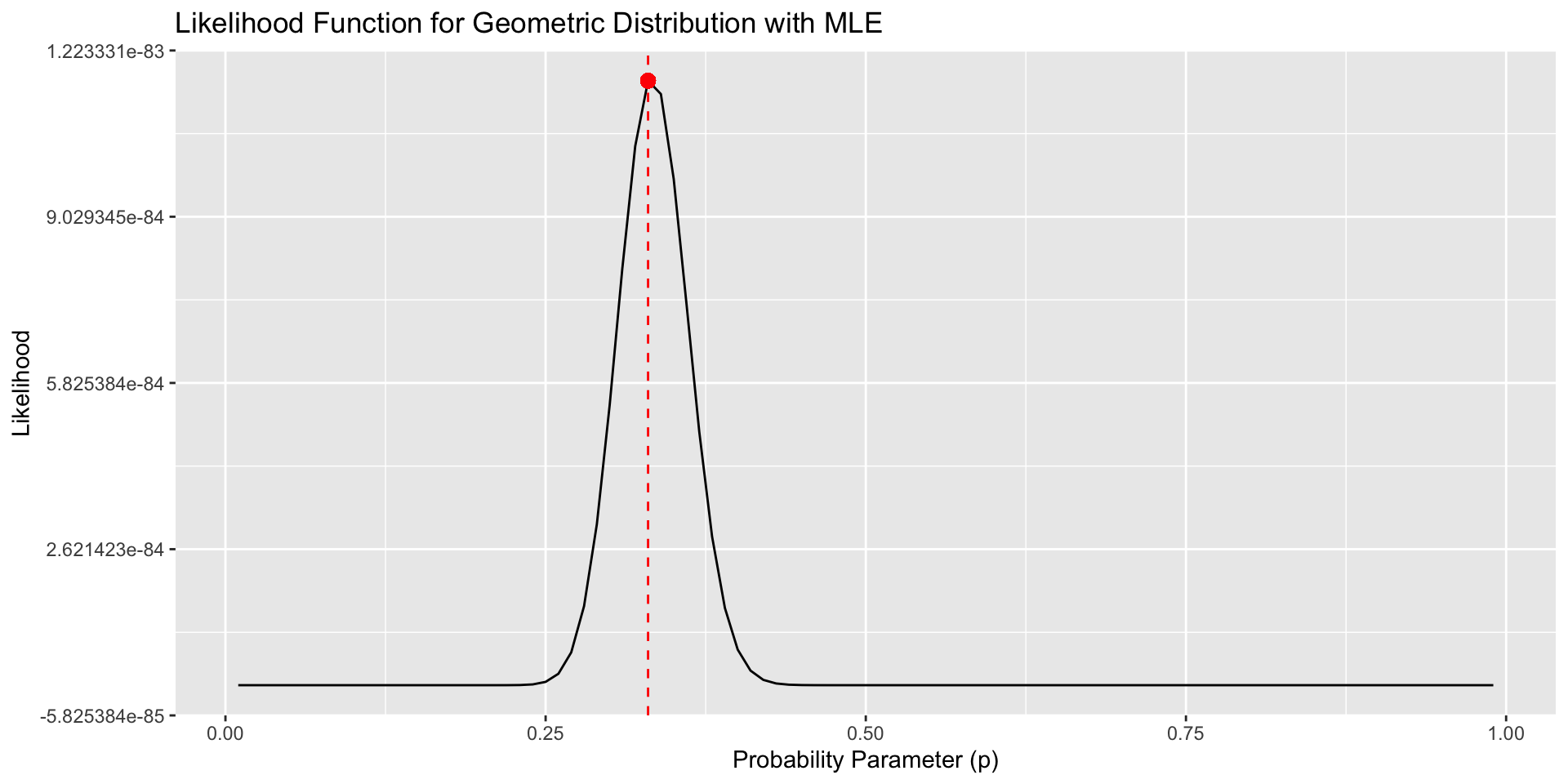
Comments
While intuitive and easy to apply, the method of moments usually does not yield “good” estimators (they are not always efficient)
In some cases, the method of moments estimator may coincide with other well-known estimators, providing a unique solution.
However, in more complex models or under certain conditions, the method of moments may not produce a unique estimator.