Lecture 8: Hypothesis Tests for One-sample Proportions
STAT 205: Introduction to Mathematical Statistics
Dr. Irene Vrbik
University of British Columbia Okanagan
Introduction
Last class we were introduced to the critical value approach for test of hypotheses about the population mean (with \(\sigma^2\) known) based on a single sample.
We will see how the same approach can be used for tests on population proportions.
We also look at alternative approach involving \(p\)-values.
We also show the connection between two-tailed hypothesis tests and confidence intervals.
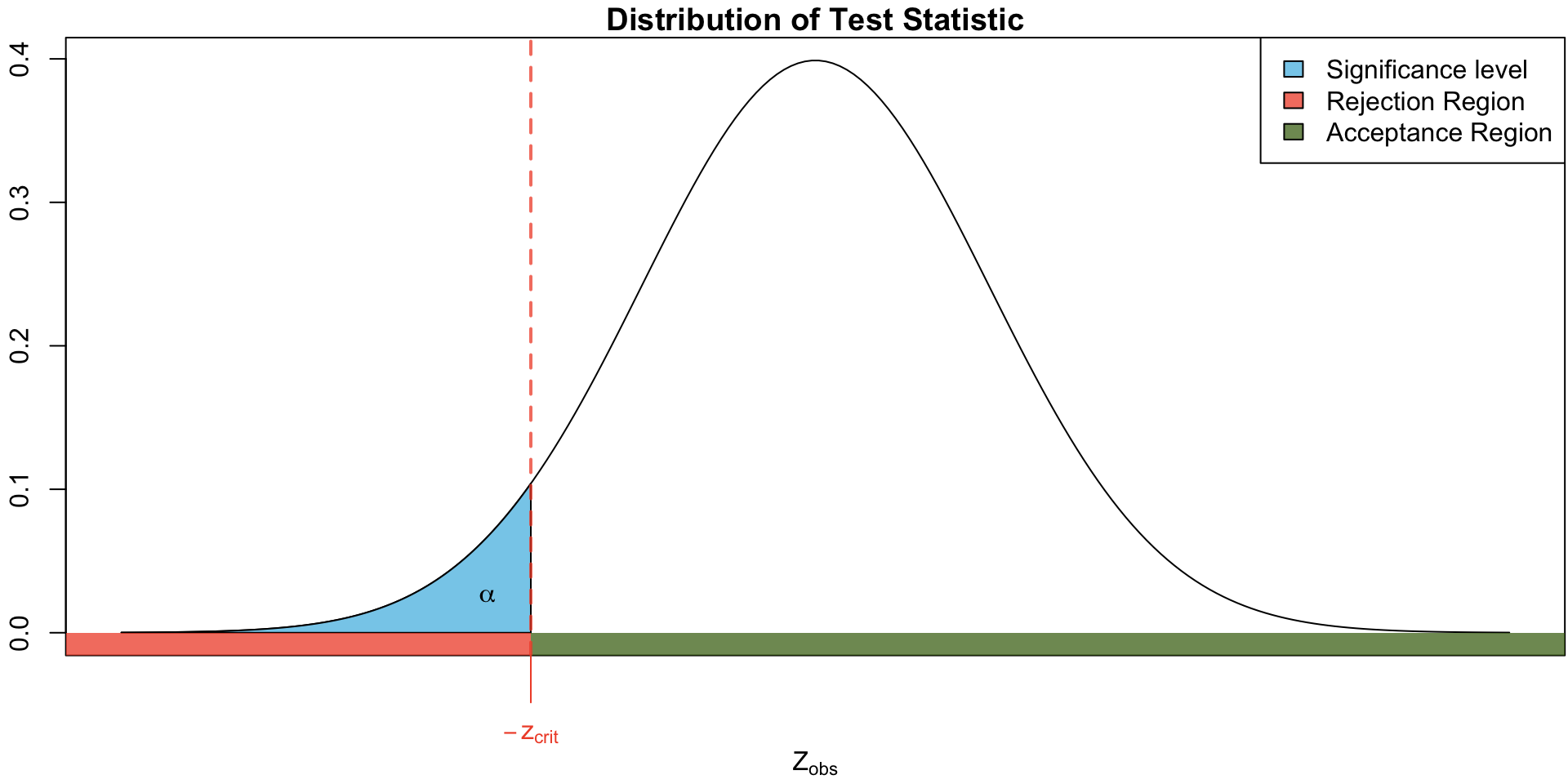
This test procedure relies on a test statistic, i.e. a function of the sample data on which serves as a basis for making decisions about whether to reject or fail to reject \(H_0\).
It requires a critical value(s)1 which separates the
rejection region (RR): the set of observed test statistics for which \(H_0\) will be rejected) from the
“acceptance”/fail-to-reject region: the set of observed test statistics for which we would fail to reject \(H_0\))
RR for Two-tail test
RR for upper-tail test
RR for lower-tail test
Critical Value approach for proportions
Check Assumptions. If satisfied, 1. State hypotheses \[\begin{equation}
H_0 : p = p_0 \quad \text{ vs. } \quad H_A: \begin{cases}
p \neq p_0& \text{ two-sided test} \\
p < p_0&\text{ one-sided (lower-tail) test} \\
p > p_0&\text{ one-sided (upper-tail) test}
\end{cases}
\end{equation}\]
Find critical value:
\[\begin{cases}
P(-z_{crit} < Z < z_{crit}) = 1 - \alpha &\text{ if } H_A: p \neq p_0 \\
P(Z < z_{crit}) = \alpha &\text{ if } H_A: p < p_0 \\
P(Z > z_{crit}) = \alpha &\text{ if } H_A: p > p_0
\end{cases}\]
Compute the test statistic \(z_{obs} = \dfrac{\hat p - p_0}{\sqrt{p_0(1-p_0)/n}}.\)
Conclusion: reject\(H_0\) if \(z_{obs} \in\) rejection region, otherwise, fail to reject\(H_0\).
Assumptions
Assumptions for Hypothesis Tests for Proportions
We have a simple random sample
The experiment can be modeled by the binomial distribution:
number of trials is fixed
trials are independent
only two possible outcomes (‘success’ and ‘failure’)
Probabilities constant for each trial
Success-failure condition1: \(np \geq 10\) and \(n(1-p) \geq 10)\)
ChatGPT
Exercise 1 According to a November 2023 research survey conducted by Pew Research1, about 13% of all U.S. teens have used the generative artificial intelligence (AI) chatbot in their schoolwork. Suppose we wish to investigate if this the proportion of students on our campus using generative AI to do homework. We survey 80 randomly selected UBCO students and find that 14 have admitted to using generative AI to do homework. Perform a formal hypothesis test for determining the proportion at UBCO differs from that of U.S. teens.
Check Assumption
We need to check the success-fail condition: that \(np \geq 10\) and \(n(1-p) \geq 10)\).
Important
We use the hypothesized value for these checks.
Here \(n\) = 80, our hypothesized value for \(p\) is 0.13
We now consider an alternative hypothesis-testing method for for deciding whether to reject \(H_0\).
Like the rejection method, it will rely on a test statistic.
Unlike the rejection method, we will no longer require a critical value, but instead calculate a certain probability that goes by the name of a \(p\)-value.
While these two procedures should yield the same conclusion, the \(p\)-value will provide an intuitive measure of the strength of evidence in the data against \(H_0\).
P-value
\(p\)-value
Definition 1 The \(p\)-value is the probability, calculated assuming that the null hypothesis is true, of obtaining a value of the test statistic at least as contradictory to \(H_0\) as the value calculated from the available sample.
In other words, it quantifies the chances of obtaining the observed data or data more favorable to the alternative than our current data set if the null hypothesis were true.
\(p\)-value approach for proportions
State hypotheses \[\begin{equation}
H_0 : p = p_0 \quad \text{ vs. } \quad H_A: \begin{cases}
p \neq p_0& \text{ two-sided test} \\
p < p_0&\text{ one-sided (lower-tail) test} \\
p > p_0&\text{ one-sided (upper-tail) test}
\end{cases}
\end{equation}\]
Compute the test statistic \(z_{obs} = \dfrac{\hat p - p_0}{\sqrt{p_0(1-p_0)/n}}.\)
Calculate the \(p\)-value
\[\begin{cases}
2P(Z \geq |z_{obs}|) &\text{ if } H_A: p \neq p_0 \\
P(Z \leq z_{obs}) &\text{ if } H_A: p < p_0 \\
P(Z \geq z_{obs}) &\text{ if } H_A: p > p_0
\end{cases}\]
Conclusion: reject\(H_0\) if \(p\)-value is less than \(\alpha\) (typically 0.05), otherwise, fail to reject\(H_0\).
Redo example using p-values
Returning to Exercise 1, and using the same hypotheses, the \(p\)-value can be calculated as follows:
However, rather than a binary outcome (reject vs. fail to reject) the \(p\)-value gives information about the strength of evidence against the null hypothesis.
e.g a \(p\)-value of 0.04999 and 0.0000001 are both significant, but 0.0000001 indicates stronger evidence than 0.04999.
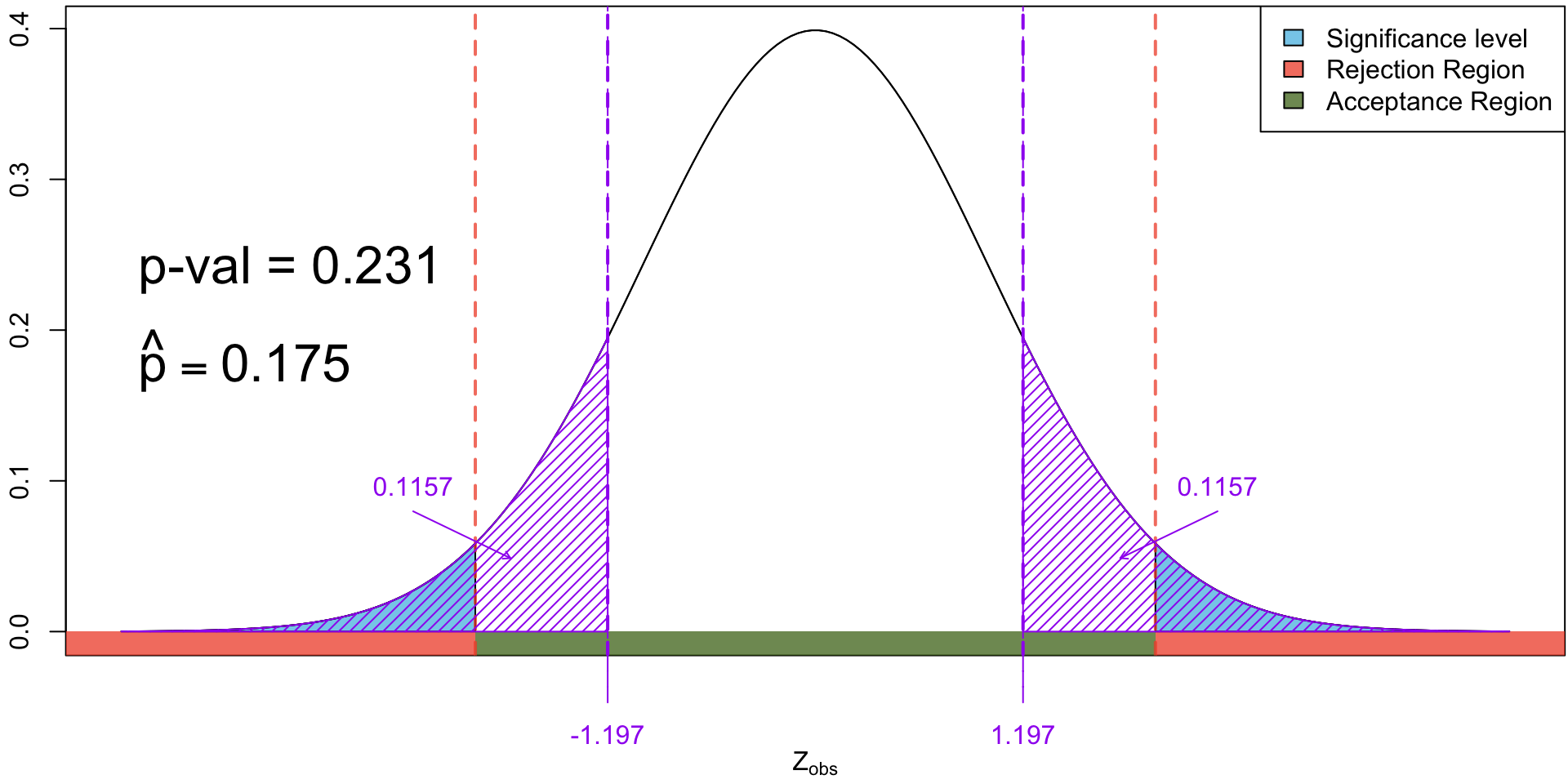
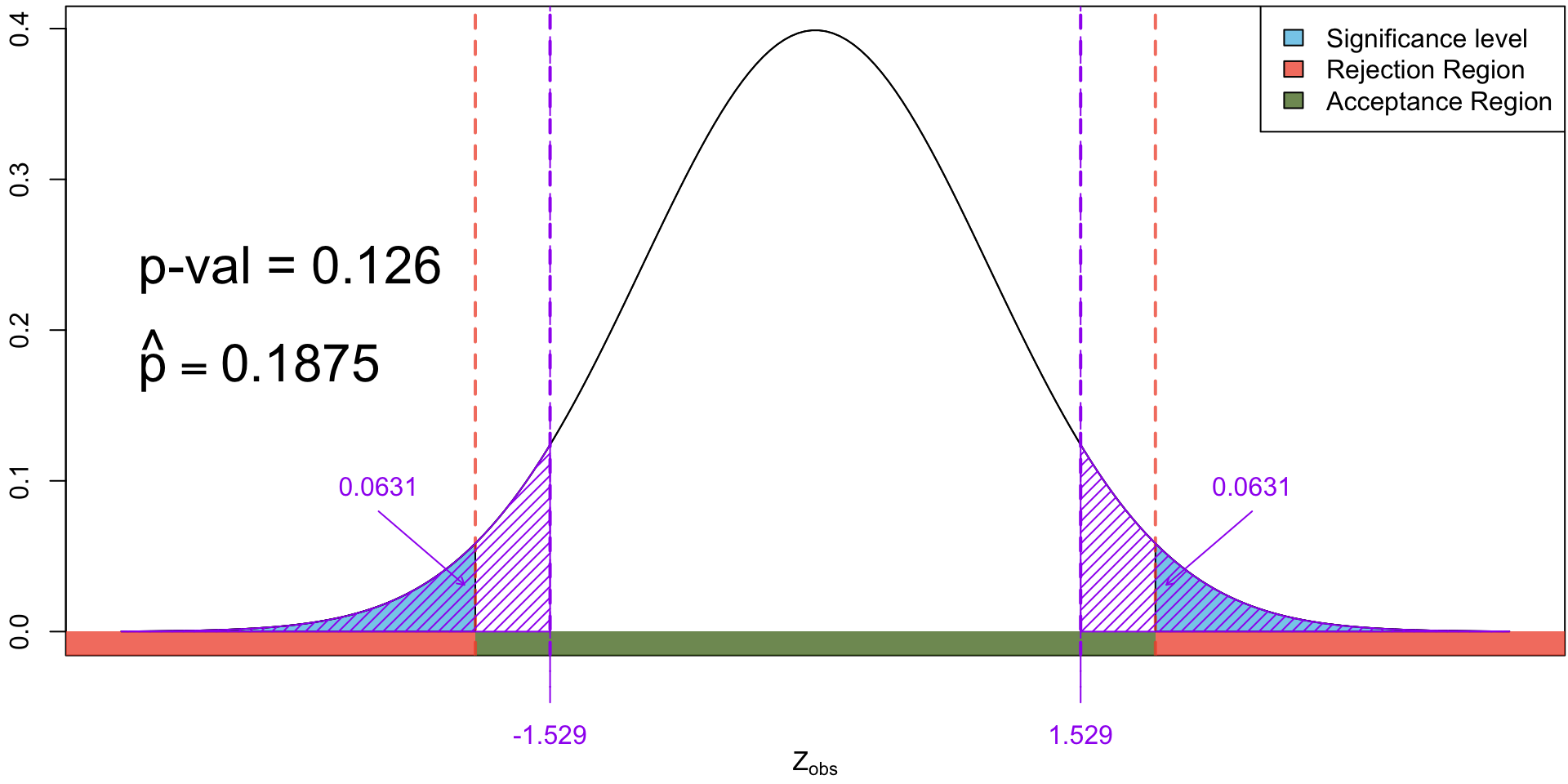
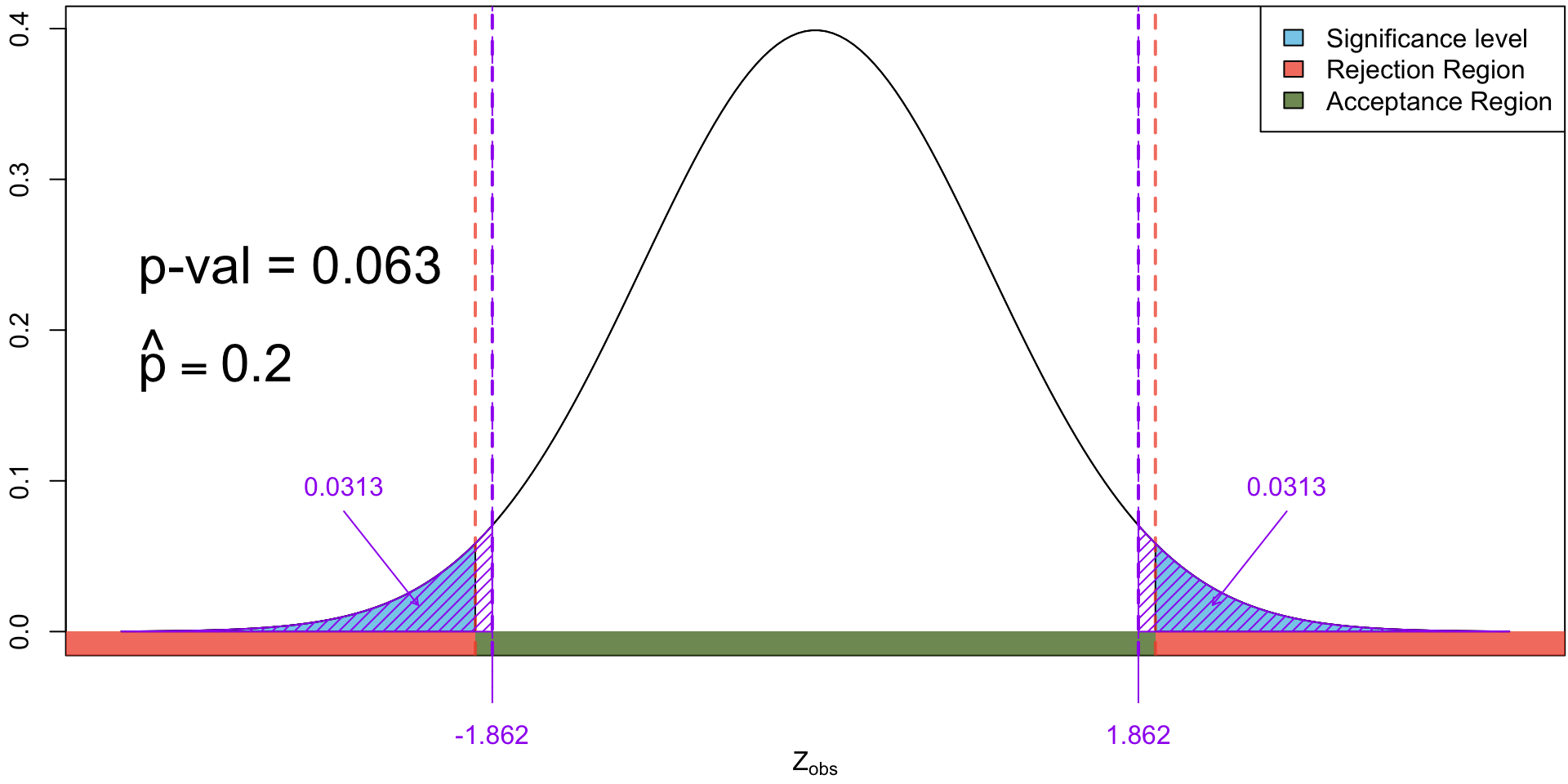
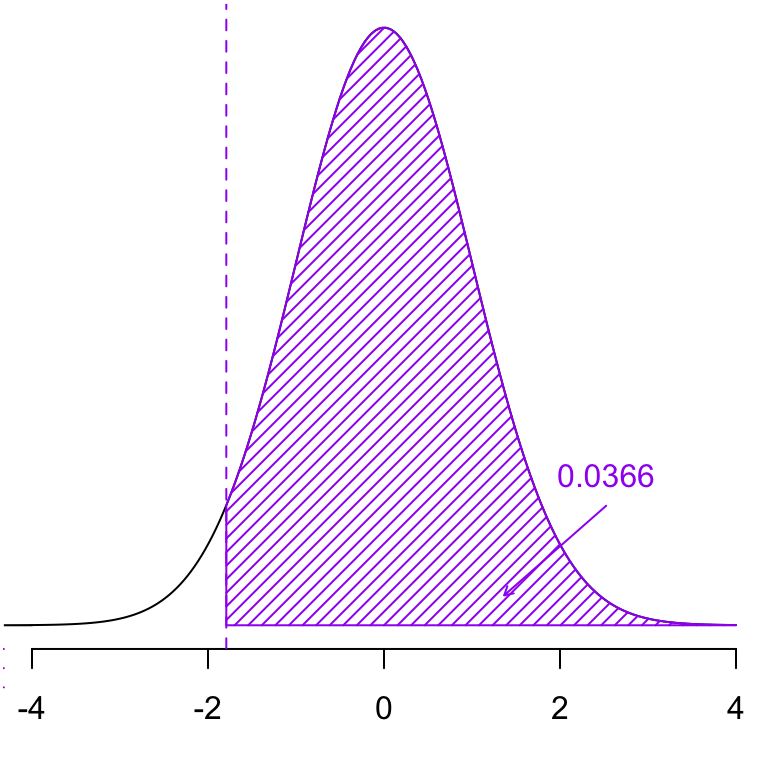
The distribution of the test statistic for testing \(H_0: p = 0.13\) vs \(H_0: p \neq 0.13\). Shaded in yellow is the \(p\)-value when we observed 14 yes’s.
The distribution of the test statistic for testing \(H_0: p = 0.13\) vs \(H_0: p \neq 0.13\). Shaded in yellow is the \(p\)-value when we observed 15 yes’s.
The distribution of the test statistic for testing \(H_0: p = 0.13\) vs \(H_0: p \neq 0.13\). Shaded in yellow is the \(p\)-value when we observed 16 yes’s.
The distribution of the test statistic for testing \(H_0: p = 0.13\) vs \(H_0: p \neq 0.13\). Shaded in yellow is the \(p\)-value when we observed 17 yes’s.
The distribution of the test statistic for testing \(H_0: p = 0.13\) vs \(H_0: p \neq 0.13\). Shaded in yellow is the \(p\)-value when we observed 18 yes’s.
The distribution of the test statistic for testing \(H_0: p = 0.13\) vs \(H_0: p \neq 0.13\). Shaded in yellow is the \(p\)-value when we observed 19 yes’s.
The distribution of the test statistic for testing \(H_0: p = 0.13\) vs \(H_0: p \neq 0.13\). Shaded in yellow is the \(p\)-value when we observed 20 yes’s.
Comments
When the observed test statistics falls in the rejection region, we will necessarily have a significant \(p\)-value and vice versa.
Observing 21 out of 80 in our sample who have used generative AI for homework (i.e. \(\hat p = \frac{21}{80}\) = 0.2625) yields a very small \(p\)-value (<0.001). Hence we have very strong evidence against the null hypothesis \(H_0\).
17 out of 80 (i.e. \(\hat p = \frac{17}{n}\) = 0.2125 ) yields a significant \(p\)-value (0.028), but evidence is not as strong as a sample with 20 “yes”s.
16 out of 80 (i.e. \(\hat p = \frac{16}{80}\) = 0.2) yields an almost significant \(p\)-value (0.063). Hence we have insufficient evidence against \(H_0\) but may still have our suspicions.
Interpreting \(p\)-values
Here are some guidelines for using the \(p\)-value to assess the evidence against the null hypothesis at \(\alpha = 0.05\).
\(p\)-value
Evidence against \(H_0\)
Significance code in R
\(0.1 \leq p \leq 1\)
no evidence
\(0.05 < p \leq 0.10\)
weak evidence
.
\(0.01 < p \leq 0.05\)
sufficient evidence
*
\(0.001 < p \leq 0.01\)
strong evidence
**
\(0< p \leq 0.001\)
very strong evidence
***
Battery Life of a New Smartphone 📱🔋
Exercise 2 A smartphone company advertises that their new model lasts an average of 20 hours per charge under normal usage. A tech reviewer, skeptical of the claim, decides to test whether the battery actually lasts less than 20 hours on average. They collect a random sample of 40 phones and observe an average battery life of 19.66 hours. Assuming \(\sigma = 1.2\) and a significance level of \(\alpha = 0.05\), test whether the phone’s battery life is significantly less than the advertised 20 hours.
Since the \(p\)-value \(< \alpha\) we reject\(H_0\) in favour of the alternative. Hence, there is statistically significant evidence to suggest that the average battery life for this model of smartphone is less than the advertised 20 hours.
Since \(p_0\) = 0.13 does not lie within this CI would have sufficient evidence to reject the null hypothesis that \(p = 0.13\)
iClicker
Connection with p-values and CI
The \(p\)-value for a two-sided hypothesis test of \(H_0: \mu = \mu_0\) is found to be 0.021. Would a 95% confidence interval for \(\mu\) contain \(\mu_0\)
Yes
No
There is not enough information to say
iClicker
Connection with p-values and CIs
The \(p\)-value for a two-sided hypothesis test of \(H_0: \mu = \mu_0\) is found to be 0.021. Would a 99% confidence interval for \(\mu\) contain \(\mu_0\)
Yes
No
There is not enough information to say
Resources
Devore, J. L., K. N. Berk, and M. A. Carlton. 2021. Modern Mathematical Statistics with Applications. Springer Texts in Statistics. Springer International Publishing. https://books.google.ca/books?id=ghcsEAAAQBAJ.



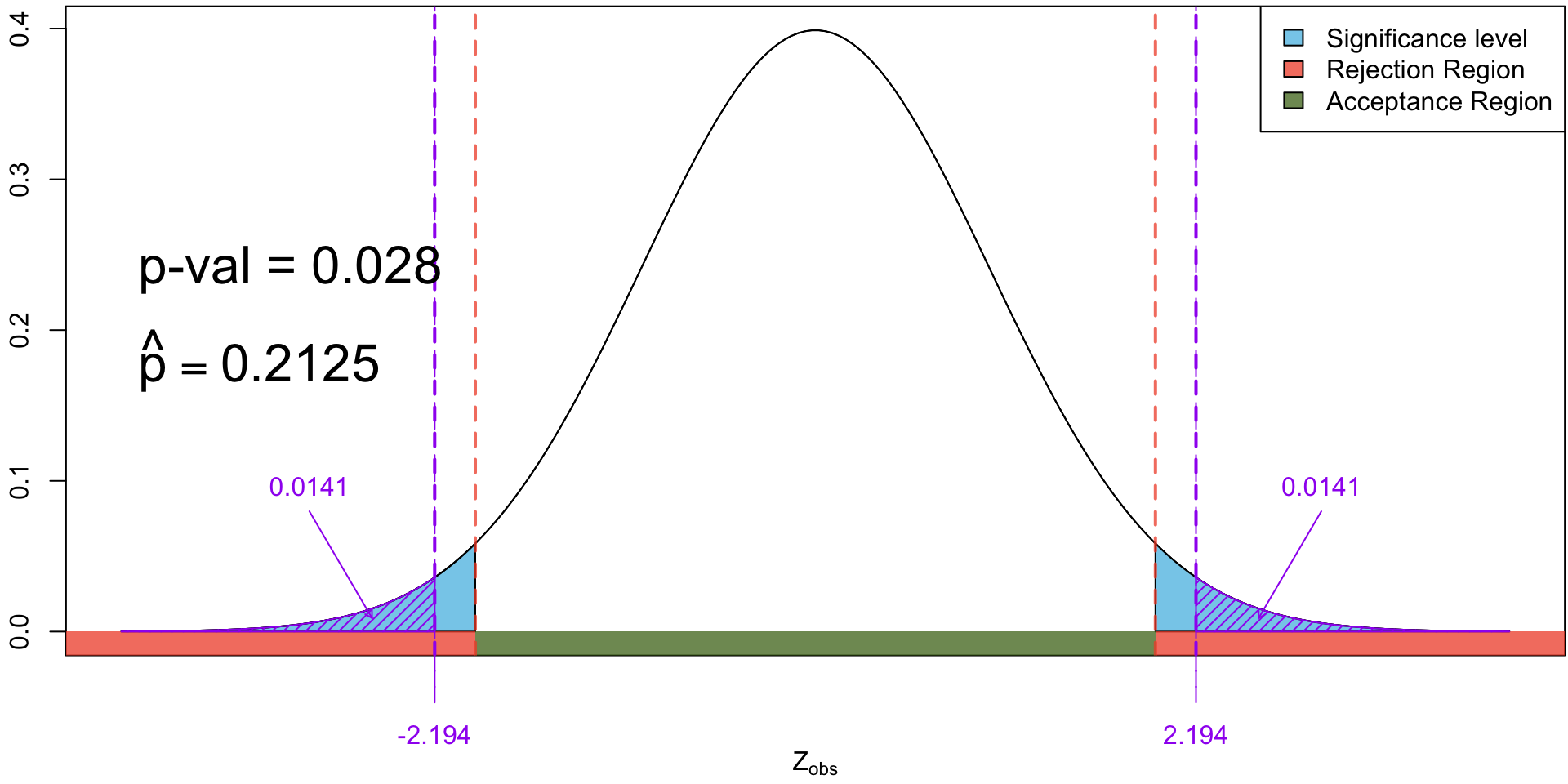

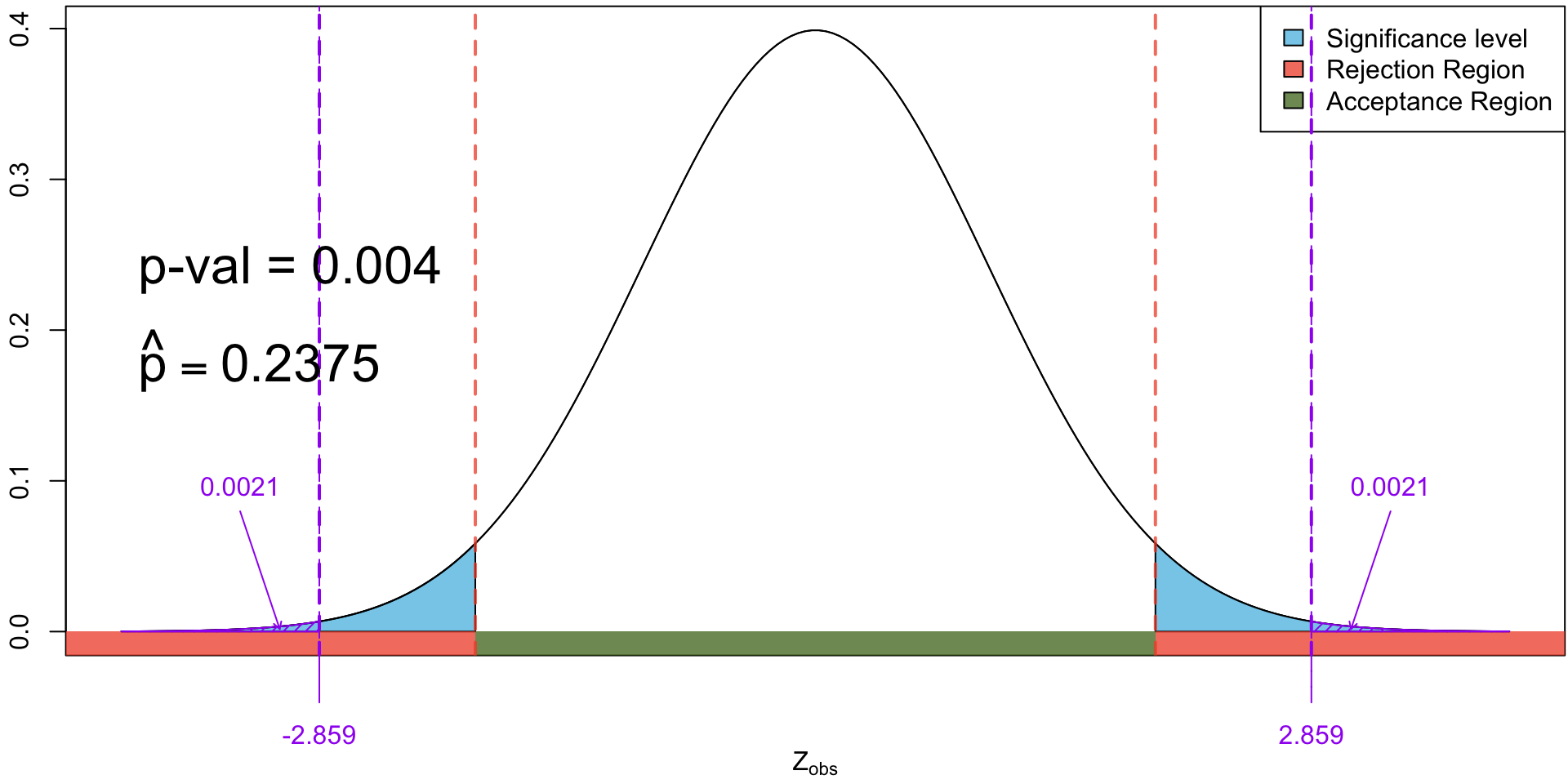
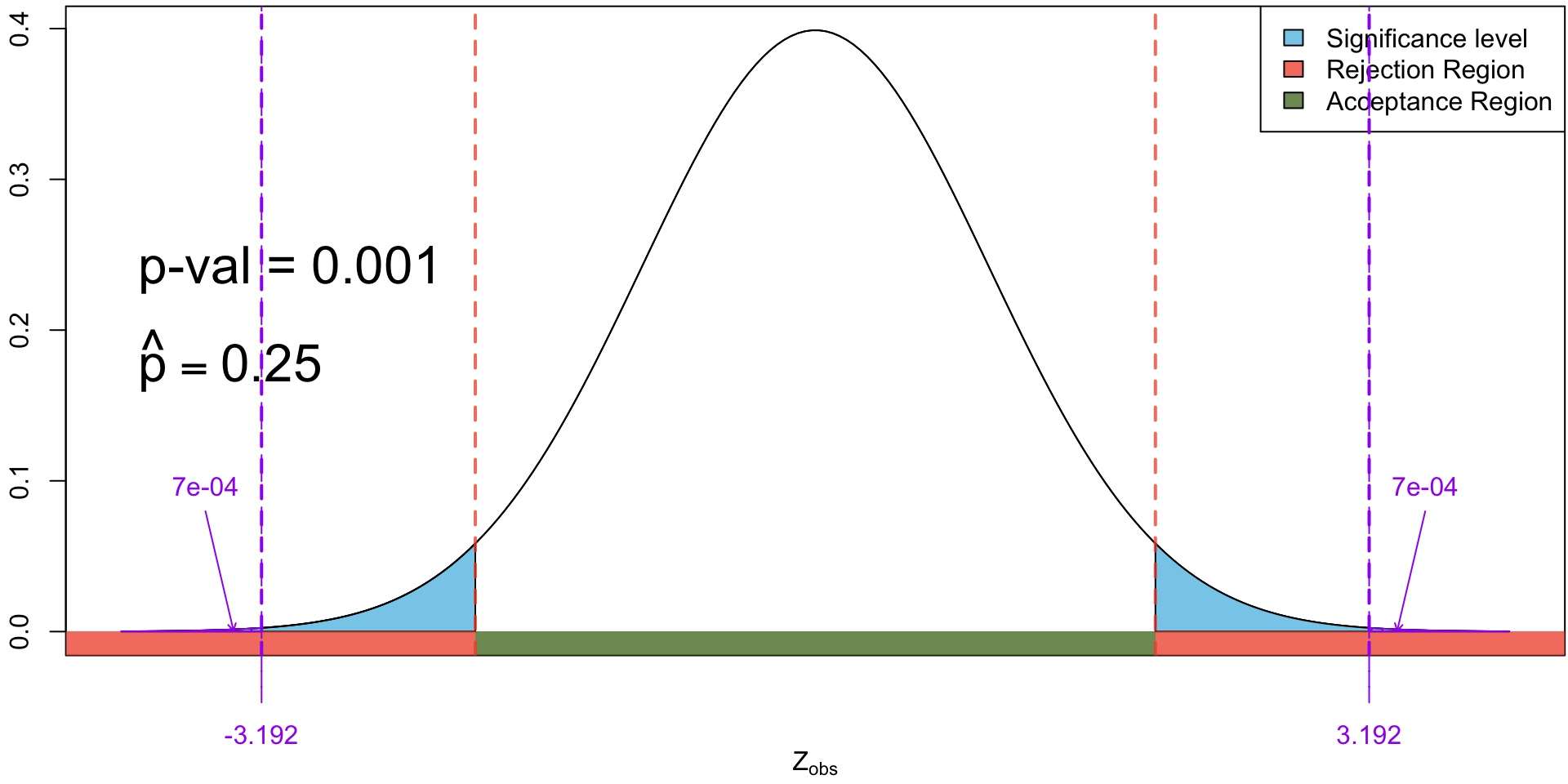
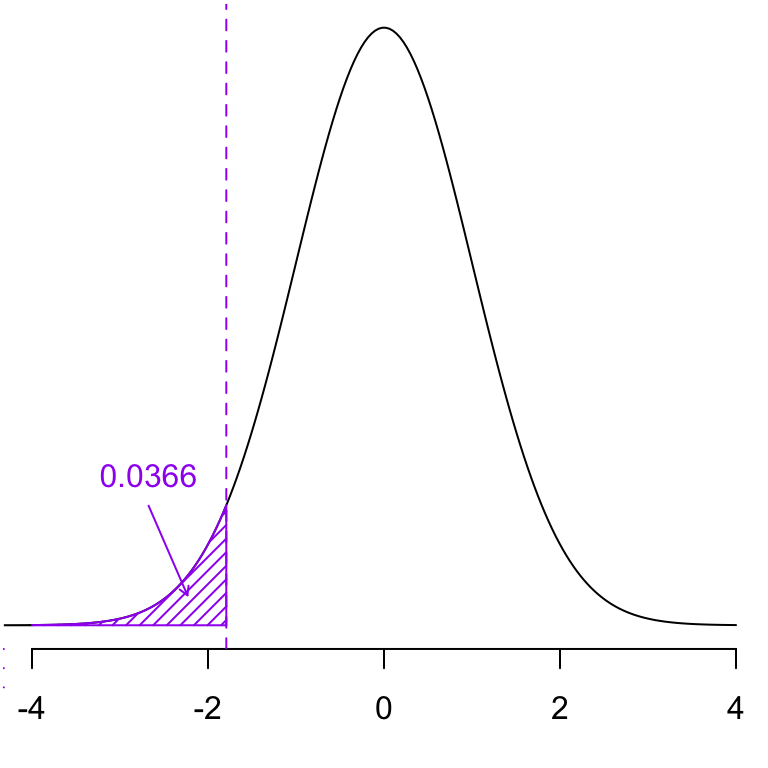

Comments
When the observed test statistics falls in the rejection region, we will necessarily have a significant \(p\)-value and vice versa.