In ordinary least squares regression, estimates of the regression coefficients (i.e. the \(\beta\)s) are found by minimizing the residuals sum of squares (RSS) (this as our “cost” function)
\[RSS = \sum_{i=1}^n (y_i - \hat y_i)^2\]
Recap
We’ve now seen a couple of alternatives to the linear model for regression.
BUT, the linear model still reigns supreme in most realms of science due to its simplicity (which helps for inference).
We can improve upon the linear model (both in terms of prediction accuracy and model interpretibility) by replacing ordinary least squares fitting with some alternative fitting procedures: shrinkage (aka regularization) methods.
In regression the following can lead to overfitting:
high-dimensional1 data (e.g. \(p>n\)),
too many predictors and/or interactions
too complexity (e.g. high-degree polynomial)
Shrinkage methods (Ridge and LASSO) discourages overly complex models and reduces variance, leading to better generalization on test data.
Non-unique solutions
Think about fitting a OLS line to a single observation.
Non-unique solutions
Think about fitting a OLS line to a single observation.
This line has a 0 SSR
Non-unique solutions
Think about fitting a OLS line to a single observation.
This line has a 0 SSR
As does this one
Non-unique solutions
Think about fitting a OLS line to a single observation.
This line has a 0 SSR
As does this one
As does this one
High Variance (small \(n\))
Think about fitting a OLS line to two data points
This line has a 0 SSR
It has high variance
And low bias
Overfitting (Complexity)
Degree = 1
Degree = 3
Degree = 9
\(\hat \beta_0\)
0.53
-0.197
0
\(\hat \beta_1\)
0.171
2.057
71
\(\hat \beta_2\)
-0.862
-474
\(\hat \beta_3\)
0.084
1317
\(\hat \beta_4\)
-1974
\(\hat \beta_5\)
1754
\(\hat \beta_6\)
-950
\(\hat \beta_7\)
307
\(\hat \beta_8\)
-54
\(\hat \beta_9\)
4
Bias-Variance Tradeoff
An overfitted regression model has high complexity relative to the amount of data available, which leads to poor generalization on new data.
Combating High Variance
Instead of least squares, we will consider an alternative fitting procedure that will introduce a small amount of bias to get back a significant drop in variance (thereby improving prediction accuracy).
Multicollinearity
When predictors are highly correlated, OLS regression may yield large and unstable coefficients, as it cannot distinguish the individual effects of each predictor.
Ridge regression is particularly useful for addressing multicollinearity by penalizing large coefficients, making the estimates more stable and reliable.
LASSO can even set some coefficients to zero, effectively selecting a subset of predictors, which is useful in highly collinear datasets.
Feature Selection
We’ve look at some crude feature selection methods previously (e.g. forward and backward selection; variable importance from trees).
LASSO provides an automatic feature selection by shrinking some coefficients to zero.
This allows for a more parsimonious1 model.
Enhanced Interpretability
With many predictors, some of which may be irrelevant, OLS can become inefficient and harder to interpret.
By focusing only on the most relevant predictors, our model becomes easier to interpret
This is particularly valuable in fields where interpretability is crucial, such as medical research or finance.
Improving Prediction Accuracy
Shrinkage methods can improve the predictive accuracy of a regression model by balancing the tradeoff between bias and variance.
By introducing a small amount of bias (penalizing coefficients), we can significantly reduce variance, leading to a lower MSE on new data compared to OLS.
🤓 One can prove that if \(\mathbf{X}^T\mathbf{X}\) is full rank1, then using some amount of regularization still improves the model (Hoerl and Kennard’s, 1970)
The p-norm (or \(\ell_p\)/Lp norm) is defined as: \[
|| x ||_p = \left(\sum_i |x_i|^p\right)^{1/p}
\]
Regularization
Regularizes regression uses the following cost function:
\[\begin{align*}
\mathcal{L}(\beta)
&= \frac{1}{n} \| \mathbf{y} - \mathbf{X} \beta \|^2 \textcolor{purple}{ + \lambda R(\beta)}
\end{align*}\] where \(\textcolor{purple}{\lambda R(\beta)}\) is a penalty term and \(\lambda\) is a regularization parameter (aka a tuning parameter)
This process of adding a norm to our cost function is known as regularization.
Hence this Ridge Regression is also known as L2 regularization.
Lasso
The least absolute shrinkage and selection operator or LASSO is arguably the most popular modern method applied to linear models. It is quite similar to Ridge only now it minimizes \[\begin{align*}
RSS + \lambda \sum_{j=1}^p |\beta_j|
\end{align*}\]
Important advantage
LASSO will force some coefficients to 0 (whereas RR will only force them “close” to 0)
L1 regularization
Another way that you might see this model being presented is using the L1 norm; in other words, the LASSO uses the \(\ell_1\) penalty:
Hence this method is also referred to as L1 regularization.
Shrinkage penalty
\(\lambda \sum_{j=1}^p \beta_j^2\) is the shrinkage penalty that will penalize the model for the total “size” of the coefficients1
As \(\lambda\) increases the coefficient estimates will tend to “shrink” towards 0.
The penalty will be small when \(\beta_1, \dots \beta_p\) are close to zero
Hence minimizing \(RSS + \lambda \sum_{j=1}^p \beta_j^2\) will encourage smaller (in magnitude) values for \(\beta_j\)
Tuning Parameter
Clearly our choice for \(\lambda\) will be an important one (can you guess how we will find it?)
If \(\lambda=0\) then the estimation process is simply least squares.
As \(\lambda\) increases, the flexibility of the ridge regression fit decreases, leading to decreased variance but increased bias.
As \(\lambda \rightarrow \infty\) then the penalty grows and the coefficients approach (but never equal) 0; this corresponds to the null model that contains no predictors.
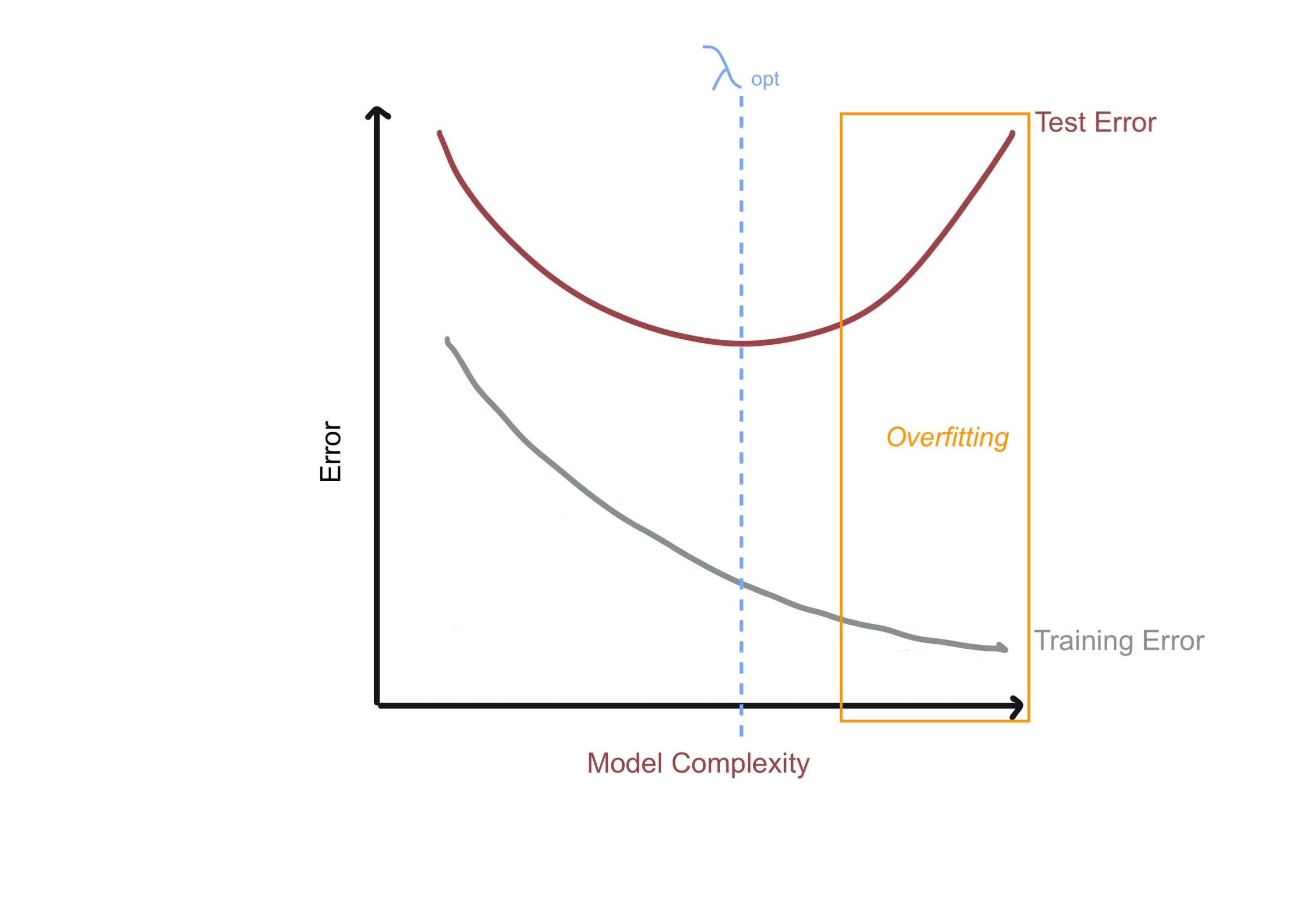
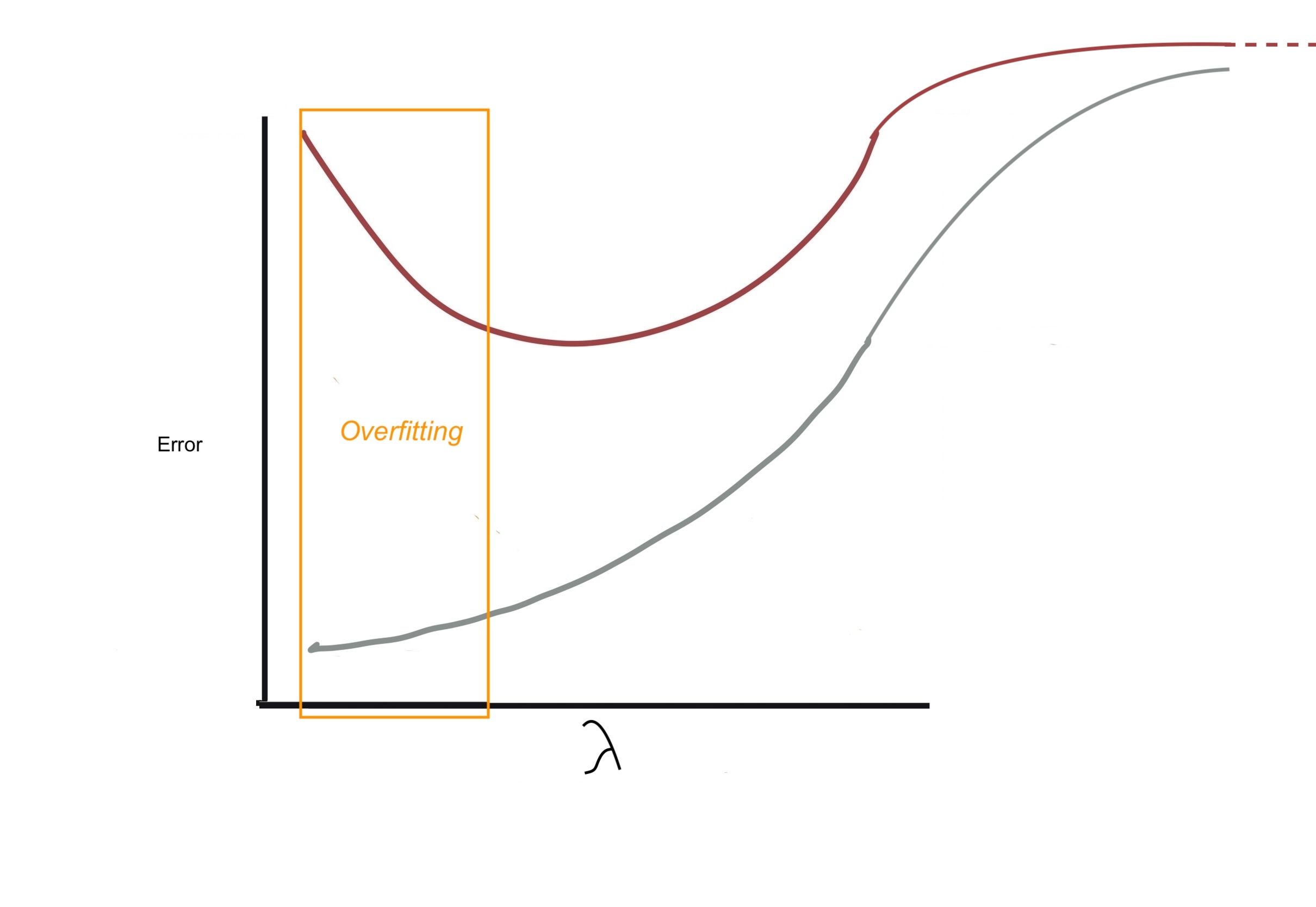
Imagine we have some regression model that is overfitting. Through regularization we aim add some bias to some bias to the model thereby decreasing variance and moving us from the overfitting zone to an optimal zone
Note that when you are reading the following plots the horizontal-axis will represent the value of \(\lambda\). The overfitting zone corresponds to small values of \(\lambda\). N.B. when \(\lambda =0\) no regularization is being performed (i.e. OLS regression). When \(\lambda \rightarrow \infty\) we have the null model
Example: Credit
The Credit dataset contains information about credit card card holders and includes 11 variables including:
Balance the average credit card debt for each individual (response) and several quantitative predictors:
Age, Cards (number of credit cards), Education (years of education), Income (in thousands of dollars), Limit (credit limit), and Rating (credit rating).
Fitting a least squares regression model to this data, we get…
MLR Credit fit
library(ISLR2); data(Credit)lfit <-lm(Balance~., data = Credit)(sfit <-summary(lfit))
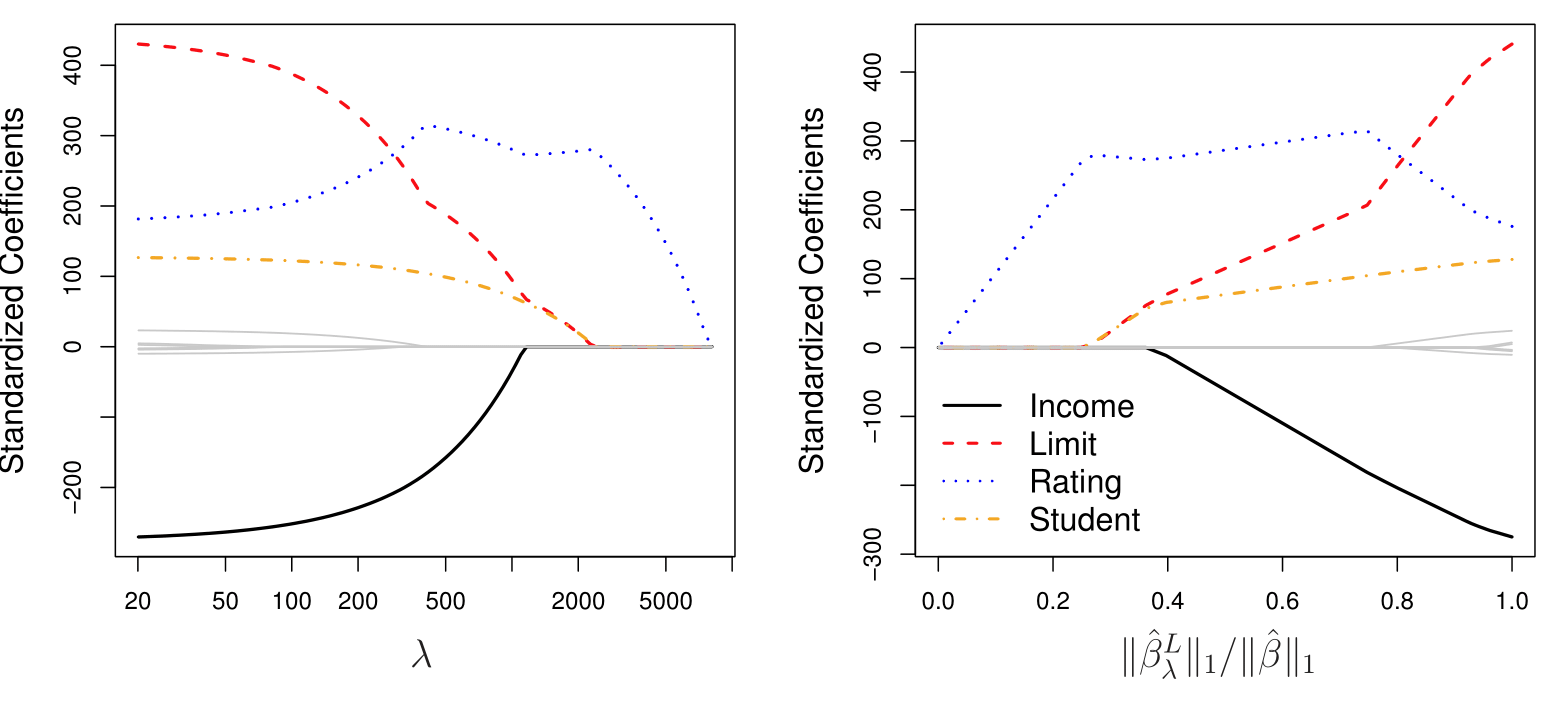
Unlike least squares, ridge regression will produce a different set of coefficient estimates, \(\beta^R_\lambda\), for each value of \(\lambda\)
Solutions as function of \(\lambda\)
ISLR Fig 6.4: The standardized ridge regression coefficients are displayed for the Credit data set, as a function of \(\lambda\) and standardized \(\ell_2\) norm.
LASSO Coefficients
ILSR FIg 6.6: The standardized lasso coefficients on the Credit data set are shown as a function of \(\lambda\) and standardized \(\ell_2\) norm. Unlike least squares, ridge regression will produce a different set of coefficient estimates, \(\beta^R_\lambda\), for each value of \(\lambda\).
ISLR simulation
A simulated data set containing \(p = 45\) predictors and \(n = 50\) observations.
ILSR 6.5 Squared bias (black), variance (green), and test mean squared error (purple) for the ridge regression predictions on a simulated data set, as a function of \(\lambda\) (left) and the standardize \(\ell_2\) norm (right). The horizontal dashed lines indicate the minimum possible MSE. The purple crosses indicate the models for which the MSE is smallest.
Scaling of predictors
Least squares coefficients are scale equivariant
i.e. multiplying \(X_j\) by a constant \(c\) leads to a scaling of the least squares coefficient estimates by a factor of \(1/c\).
In contrast, the ridge regression coefficient estimates can change substantially when multiplying a given predictor by a constant
Why? since we use the sum of squared coefficients in the penalty term of the ridge regression objective function.
Scaling of predictors (cont’d)
Therefore, it is best to apply ridge regression after standardizing the predictors, using the formula
Software will perform centering and standardizing by default and reports answers back on original scale.
iClicker
iClicker: difference between Lasso and Ridge
What is the primary difference between LASSO and Ridge regression?
Ridge regression uses the L1 penalty while LASSO uses the L2 penalty.
Ridge regression can handle non-linear relationships, whereas LASSO cannot.
LASSO is used when the number of predictors is less than the number of observations, while Ridge is used when predictors exceed observations.
LASSO performs feature selection by setting some coefficients to zero, while Ridge only shrinks them. ✅ Correct
iClicker
iClicker: tuning paramter
In the context of LASSO and Ridge regression, what does the parameter \(\lambda\) control?
The intercept of the regression model
The degree of the polynomial in the model
The strength of regularization applied to the coefficients ✅ Correct
The number of predictors included in the model
Comment
Unlike subset selection, which will generally select models that involve just a subset of the variables, ridge regression will include all predictors in the final model.
In other words, \(\beta\) coefficients approach 0 but never are actually equal to zero.
But adopting a small change on our penalty term, we will be able shrink coefficients exactly to zero (and hence perform feature selection) \(\dots\)
Benefits of LASSO
It is worth repeating that the \(\ell_1\) penalty forces some of the coefficient estimates to be exactly equal to zero when the tuning parameter \(\lambda\) is sufficiently large
Hence the lasso performs variable selection
As a result, models generated from the lasso are generally much easier to interpret than those of ridge regression
We say that the lasso yields “sparse” models — that is, sparse models that involve only a subset of the variables.
Benefits of Ridge Regression
The lasso implicitly assumes that a number of the coefficients truly equal zero
When this is not the case, i.e. all predictors are useful, Ridge Regression would leads to better prediction accuracy
These two examples illustrate that neither ridge regression nor the lasso will universally dominate the other.
The choice between Ridge Regression and LASSO can also boil down to the Prediction vs. Inference trade off (aka Accuracy-Interpretability trade off);
When to use what?
One might expect the Lasso to perform better in a setting where a relatively small number of predictors have substantial coefficients, and the remaining predictors have coefficients that are very small or that equal zero
Ridge regression will perform better when the response is a function of many predictors, all with coefficients of roughly equal size.
Since we do not typically know this, a technique such as cross-validation can be used in order to determine which approach is better on a particular data set.
When to use Regularization
\(p > n\)
These methods are most suitable when \(p > n\).
Even when \(p < n\) these approaches (especially lasso) is popular with large data sets to fit a linear regression model and perform variable selection simultaneously.
Being able to find, so-called “sparse” (as opposed to “dense”) models that select a small number of predictive variables in high-dimensional datasets is tremendously important/useful.
When to use Regularization
Multicollinearity
Less obviously, when you have multicollinearity1 in your data, the least squares estimates have high variance.
Furthermore, multicollinearity makes it difficult to distinguish which which variables (if any) are truly useful.
Using the same argument as before, we can use ridge regression and lasso to reduce the variance and improve prediction accuracy and simultaneous shrink the coefficients of redundant predictors.
Multicollinearity in Credit
pairs(Credit[,1:3])
iClicker
iClicker: which to choose
Why might you choose LASSO over Ridge regression?
When you want a model with non-zero coefficients for all predictors
When you want to reduce multicollinearity but retain all predictors
When the predictors are known to be independent of each other
When you want to perform feature selection and have some coefficients exactly equal to zero ✅ Correct
iClicker
iClicker
Which of the following statements is true about the bias-variance trade-off in LASSO and Ridge regression?
Increasing \(\lambda\) in both methods increases bias but decreases variance. ✅ Correct
Increasing \(\lambda\) in both methods decreases bias but increases variance.
Increasing \(\lambda\) in LASSO increases variance, while it decreases variance in Ridge.
LASSO increases bias, while Ridge increases variance.
Choosing \(\lambda\)
Both the lasso and ridge regression require specification of \(\lambda\)
In fact, for each value of \(\lambda\) we will see different coefficients.
So how do we find the best one?
The answer, as you may have guessed, is cross-validation.
glmnet
To perform regression with regularization we use the function glmnet() function (from package glmnet )
glmnet(x, y, ... )
Note that glmnet does not allow the formula argument1.
Hence we will need specify x and y.
glmnet penalty
glmnet(x, y, alpha =1, ... )
The penalty used is: \[
\frac{(1-\alpha)}{2} || \beta ||_2^2 + \alpha ||\beta||_1
\]
alpha=1 is the lasso penalty \(||\beta||_1\) (default)
alpha=0 is the ridge penalty
glmnet\(\lambda\)
glmnet(x, y, alpha =1, nlambda =100 ... )
A grid of values for the regularization parameter \(\lambda\) is considered
nlambda: the number of \(\lambda\) values considered in the grid (default=100)
The actually values are determined by nlambda and lambda.min.ratio (see the help file for more on this)
Alternatively, the user may supply a sequence for \(\lambda\) (in the optional lambda argument), but this is not recommended.
The model.matrix() function is particularly useful for creating x
Not only does it produce a matrix corresponding to the predictors but it also automatically transforms any qualitative variables into dummy variables1
Lasso with Credit
lasso <-glmnet(x = x, y = y, family ="gaussian", alpha =1)plot(lasso, xvar ="lambda")
Lasso Coefficient Estimates
To see the values for the coefficient estimates use coef(). For example to the see coefficients produced when \(\lambda\) the 60th value in our sequence ( log \(\lambda\) = 0.4938434 in this case):
set.seed(10) # use cross-validation to choose the tuning parametercv.out.rr <-cv.glmnet(x, y, alpha =0)plot(cv.out.rr); log(bestlam <- cv.out.rr$lambda.min)
[1] 3.680249
Cross-validation for Lasso
set.seed(1) # use cross-validation to choose the tuning parametercv.out.lasso <-cv.glmnet(x, y, alpha =1)plot(cv.out.lasso); log(bestlam <- cv.out.lasso$lambda.min)
[1] -0.5295277
CV output plot
The cv.glmnet ouptut plot produced from a simulation that you will see in lab
lasso <-glmnet( x = beer[,c(3:7)], y = beer[,2], family ="gaussian", alpha =1)plot(lasso, xvar ="lambda")
Best \(\lambda\) for LASSO
Lasso on beer
# superimpose the best lambda on trace plotplot(lasso, xvar ="lambda")abline(v =log(bestlam.lasso), col ="gray", lwd =2, lty =2)
Lasso on beer
library(plotmo) # allows us to label the x biggest coefsplot_glmnet(lasso, xvar ="lambda", label =5)abline(v =log(bestlam.lasso), col ="gray", lwd =2, lty =2)
Lasso on beer
library(plotmo) # allows us to label the x biggest coefsplot_glmnet(lasso, xvar ="lambda", label =5)lambda2 = cv.out.lasso$lambda.1se # 2nd choice abline(v =log(lambda2), col ="gray", lwd =2, lty =2)
Coefficients
cbind(coef(beer.lm), # OLS (least squares estimates)# LASSO estimates ...coef(lasso, s = bestlam.lasso), # ... at best lambdacoef(lasso, s = lambda2)) # ... at lambba within 1 s.e.
6 x 3 sparse Matrix of class "dgCMatrix"
s1 s1
(Intercept) 3.7174521392 3.334440257 3.25063467
qlty -0.0111434572 -0.008782345 .
cal -0.0055034319 . .
alc 0.0764519623 . .
bitter 0.0677117274 0.062008057 0.04831986
malty 0.0002831604 . .
Summary
Ridge regression and LASSO works best in situations where the least squares estimates have high variance.
This can happen when \(p\) exceeds (or is close to \(n\))
It can also happen when we have multicollinearity
LASSO shrinks coefficient estimates to exactly 0 hence it can be viewed as a variable selection technique
Ridge Regression shrinks coefficient estimates close to 0 so it never actually eliminates any predictors.
Different Formulation
The coefficient estimates can be reformulated to solving the following two problems.
Contours of the error and constraint functions for the lasso (left) and ridge regression (right). The solid blue areas are the constraint regions, \(|\beta_1| + |\beta_2| \leq s\) and \(\beta_1^2 + \beta_2^2 \leq s\), while the red ellipses are the contours of the RSS.