
Data 311: Machine Learning
Lecture 10: Classification and Regression Trees
Motivating Classification Example
Task: partition the feature space into subsets, with each subset/region corresponding to a specific class.

True classes are colour/shape-coded
Rules: Regions can only be split horizontal or vertically.
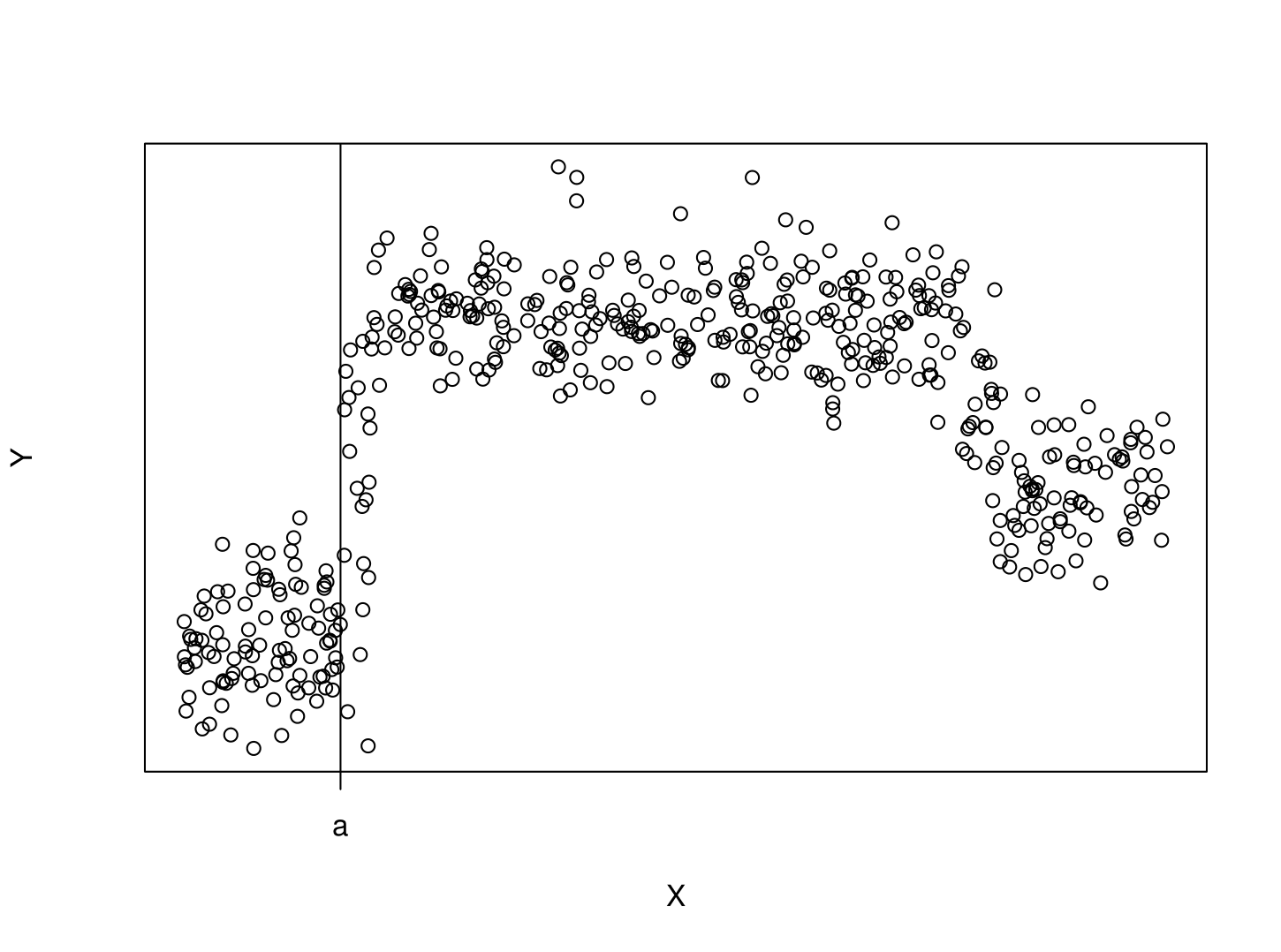
First Rule on X1
As a first go, let this line represent a decision

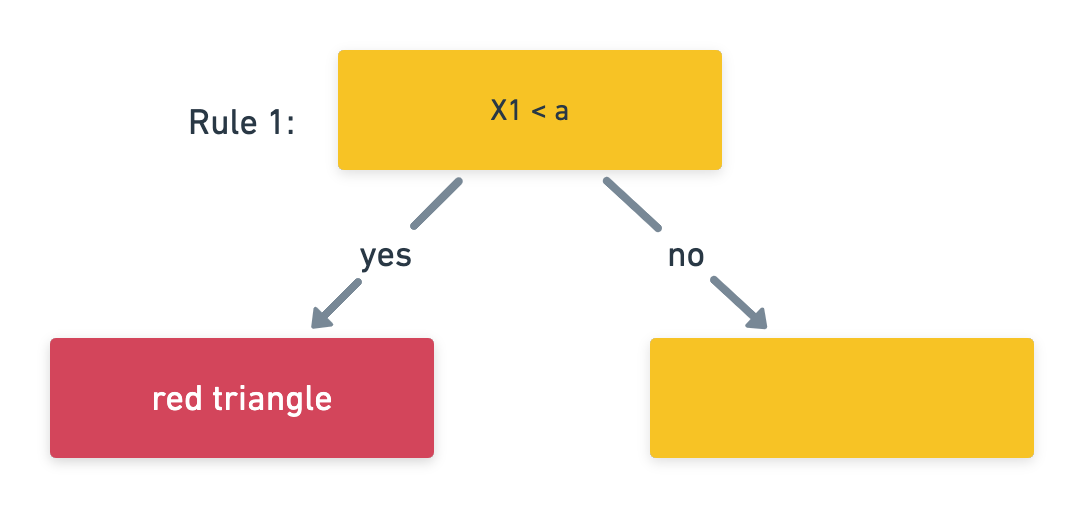
Rule 1:
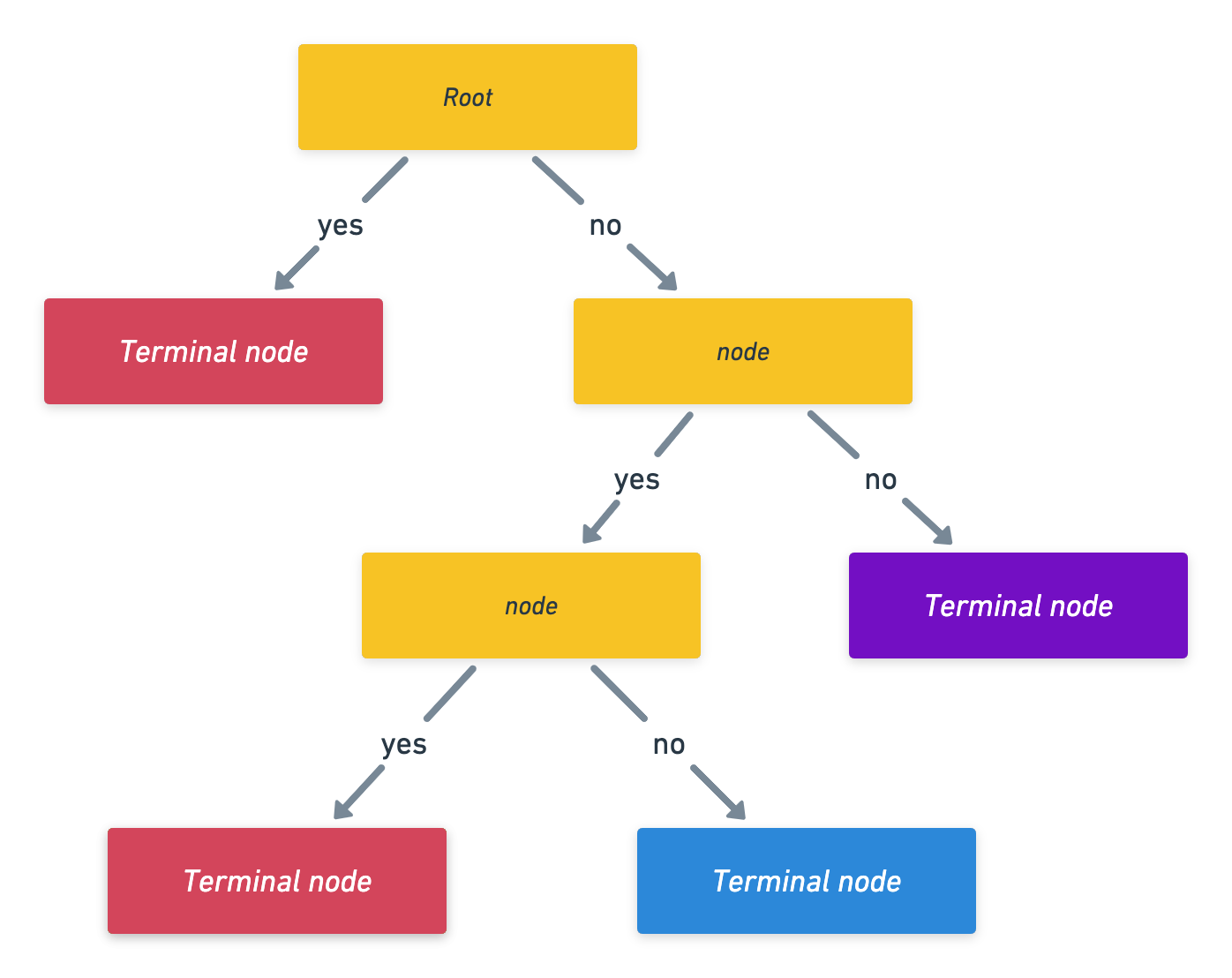
Let’s summarize this as a flow chart:
Second Rule on X1

the left-most region is said to be pure (i.e. only containing observations from the red triangle group; see Gini Index)
Rule 2

Third Rule on X2

Rule 3

The prediction at a terminal node is the majority class for that corresponding region in the feature space.
Notation (on tree)
8 Regions

Motivating Regression Example

Split 1
Split 2

Split 3

Split 4

\(Y\) Predictions

Baseball Example:


Hitters dataset from Major League Baseball player data from 1986-87. y-axis: number of years playing in the major leagues. x-axis: number of hits in the previous year. Colour: salary (low salary is blue/green, and the high salary is red/yellow)
Im/Possible Regions

Left: A partition of two-dimensional feature space that could not result from recursive binary splitting. Right: The output of recursive binary splitting on a two-dimensional example.
Resulting Tree


The tree (left) corresponding to the feature space partition (right).
Problem

Building a tree through the description just given will tend to overfit1 to the training data and lead to poor test set performance.
A common strategy is to grow a large tree, \(T_0\), and then prune it back to obtain a subtree.
Intuitively, our goal is to select a subtree that leads to the lowest test error rate.
A good StatQuest video on the subject.
CV Plot

Each point on this plot is calculated using these steps
Redo Motivating Example

Rule 1
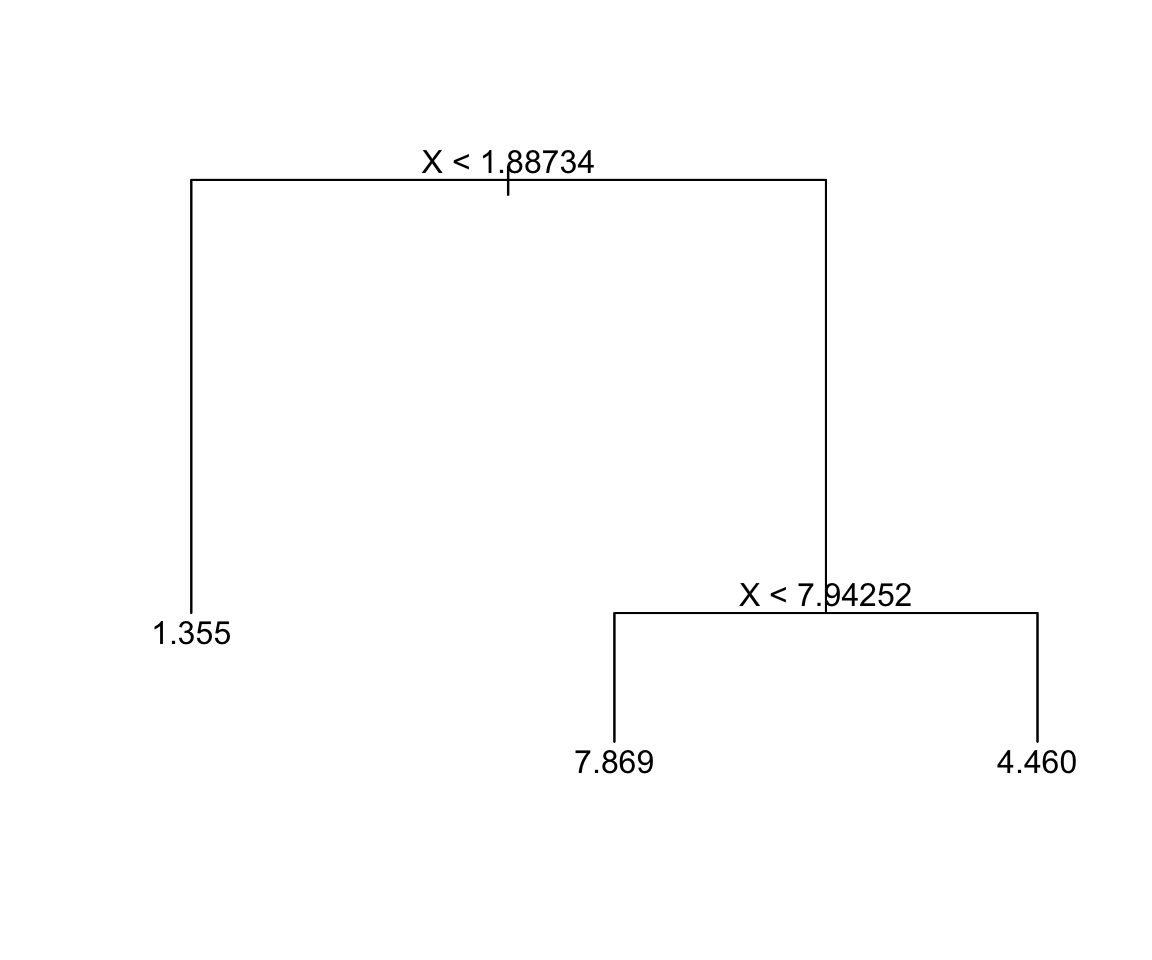
x < 1.88734?
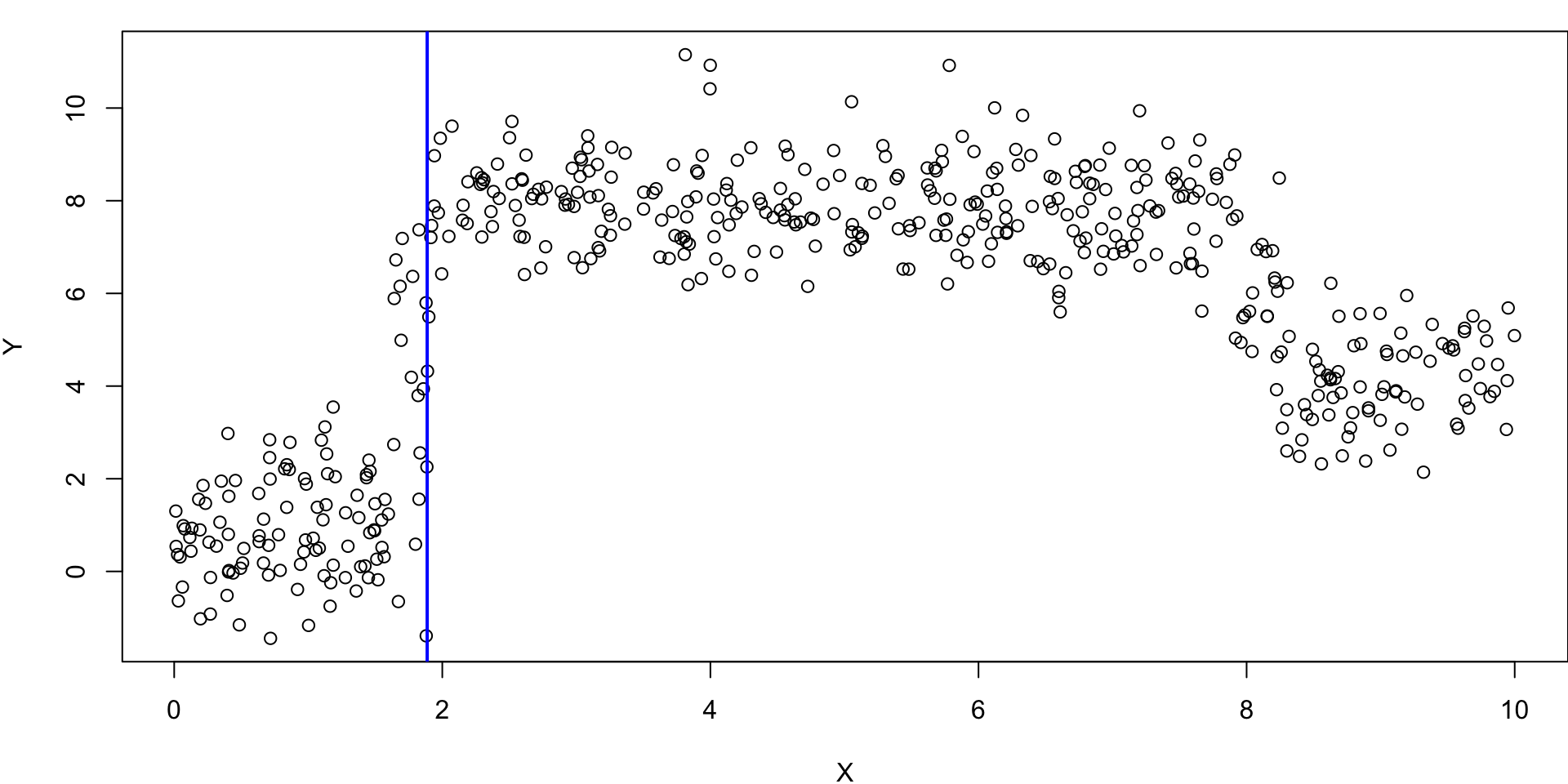

This split was determine by this
Rule 1: No. Rule 2
x < 1.61789?

This split was determined using this
Rule 1: Yes. Rule 2: Yes
predict 0.893184

Rule 1: Yes. Rule 2: No
predict 3.8922321
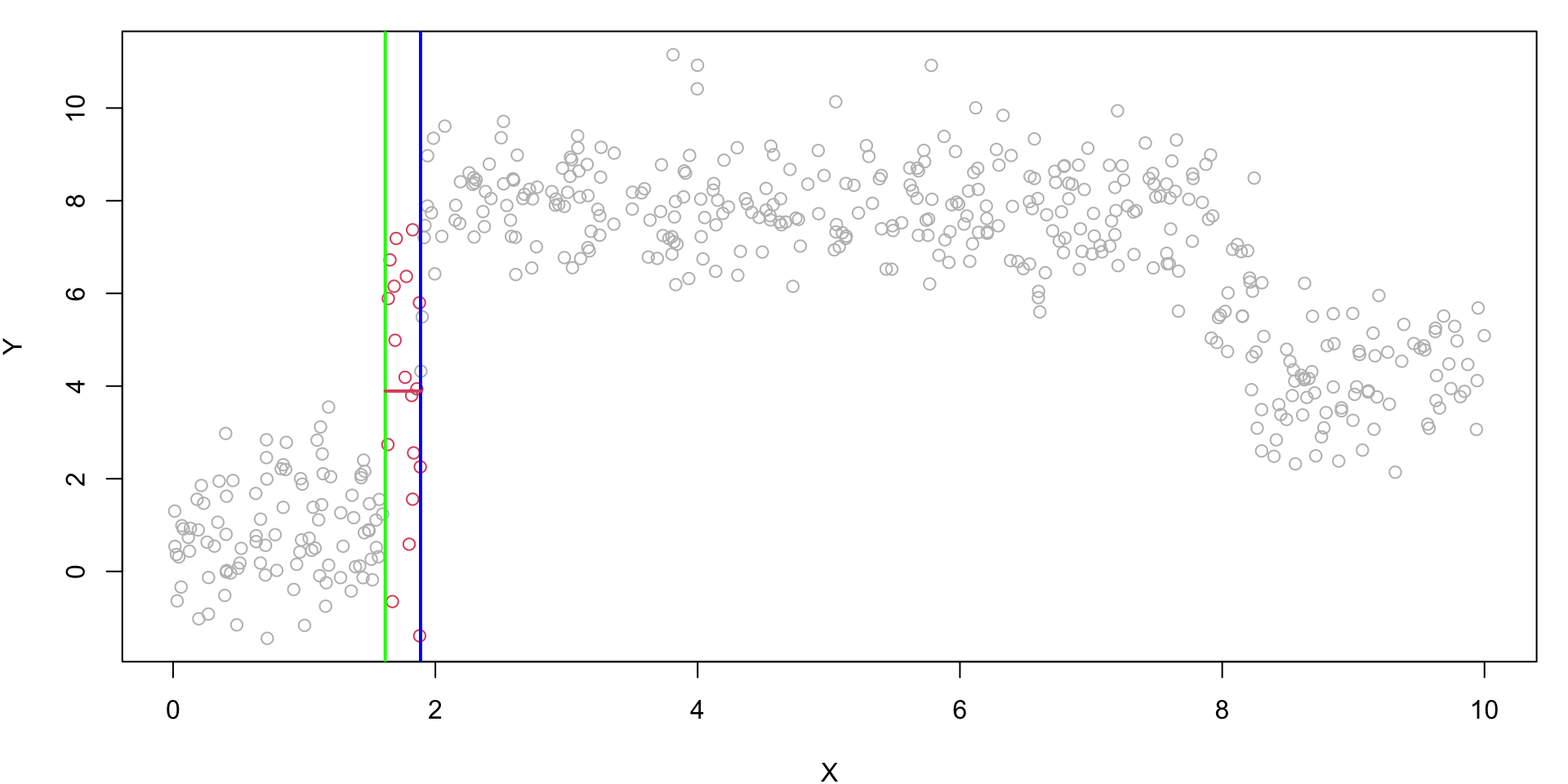
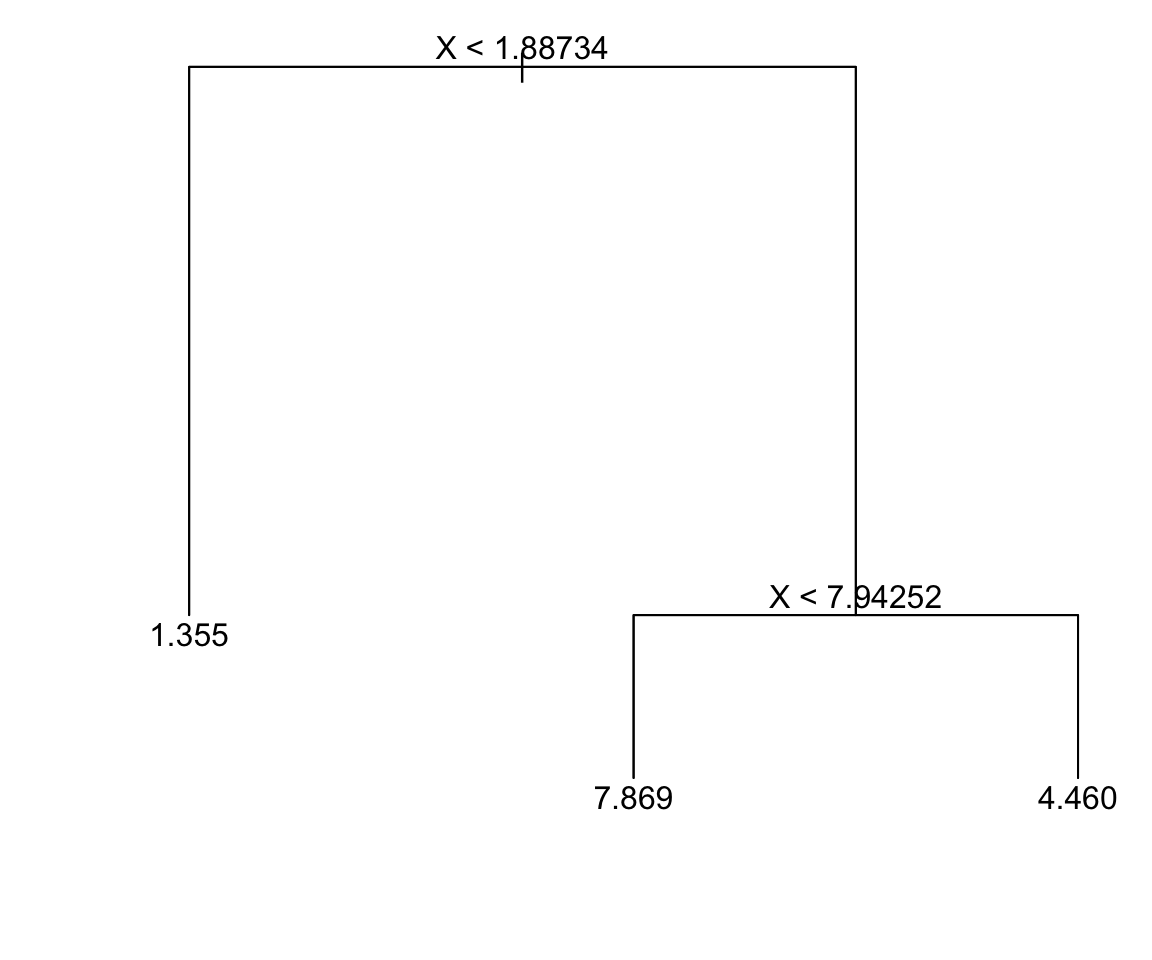
Rule 1: No. Rule 3
X < 7.94252?
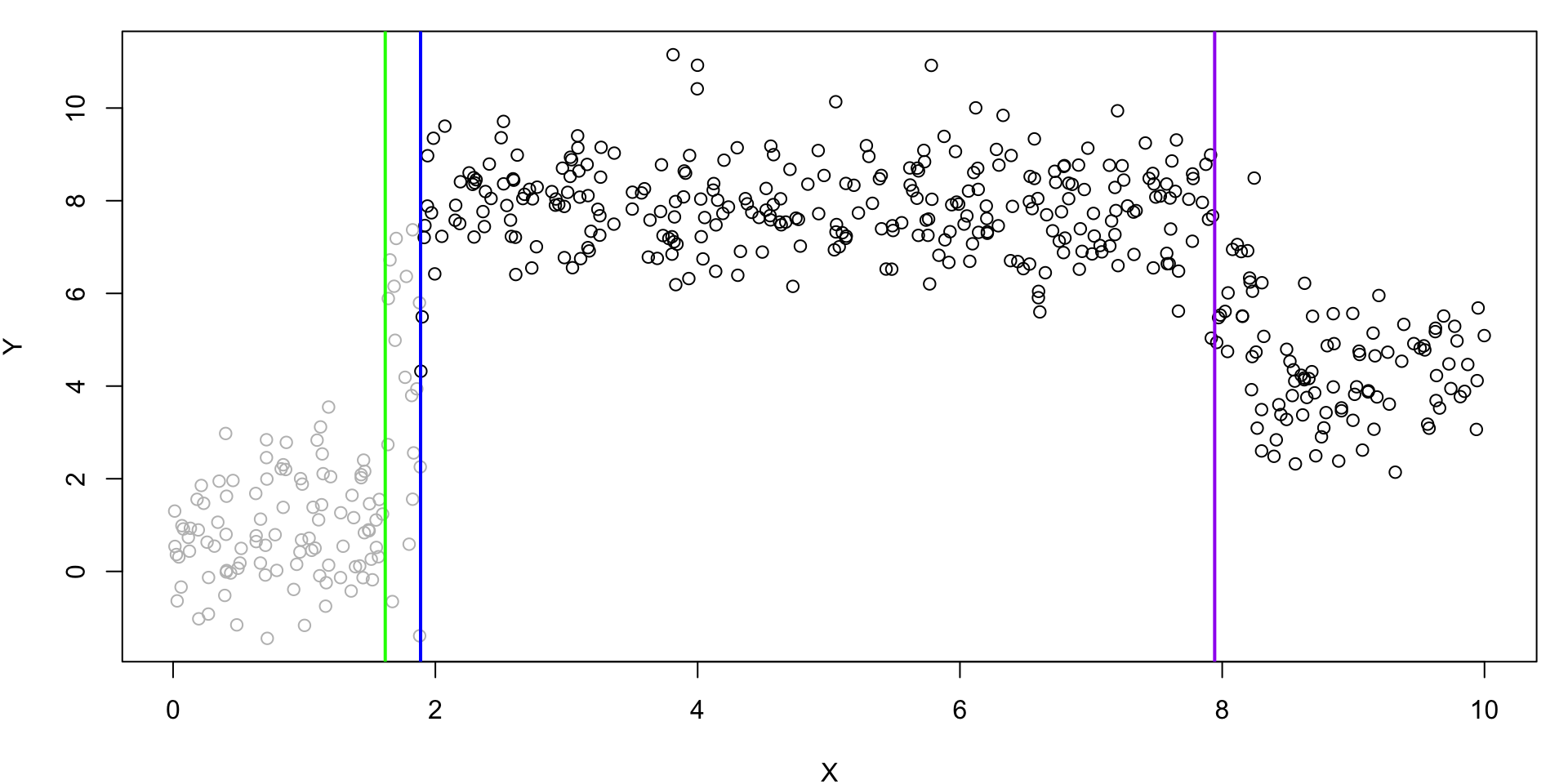

Rule 1: No. Rule 3 Yes.
predict 7.8689239


Rule 1: No. Rule 3 No. Rule 4
X < 8.25091?
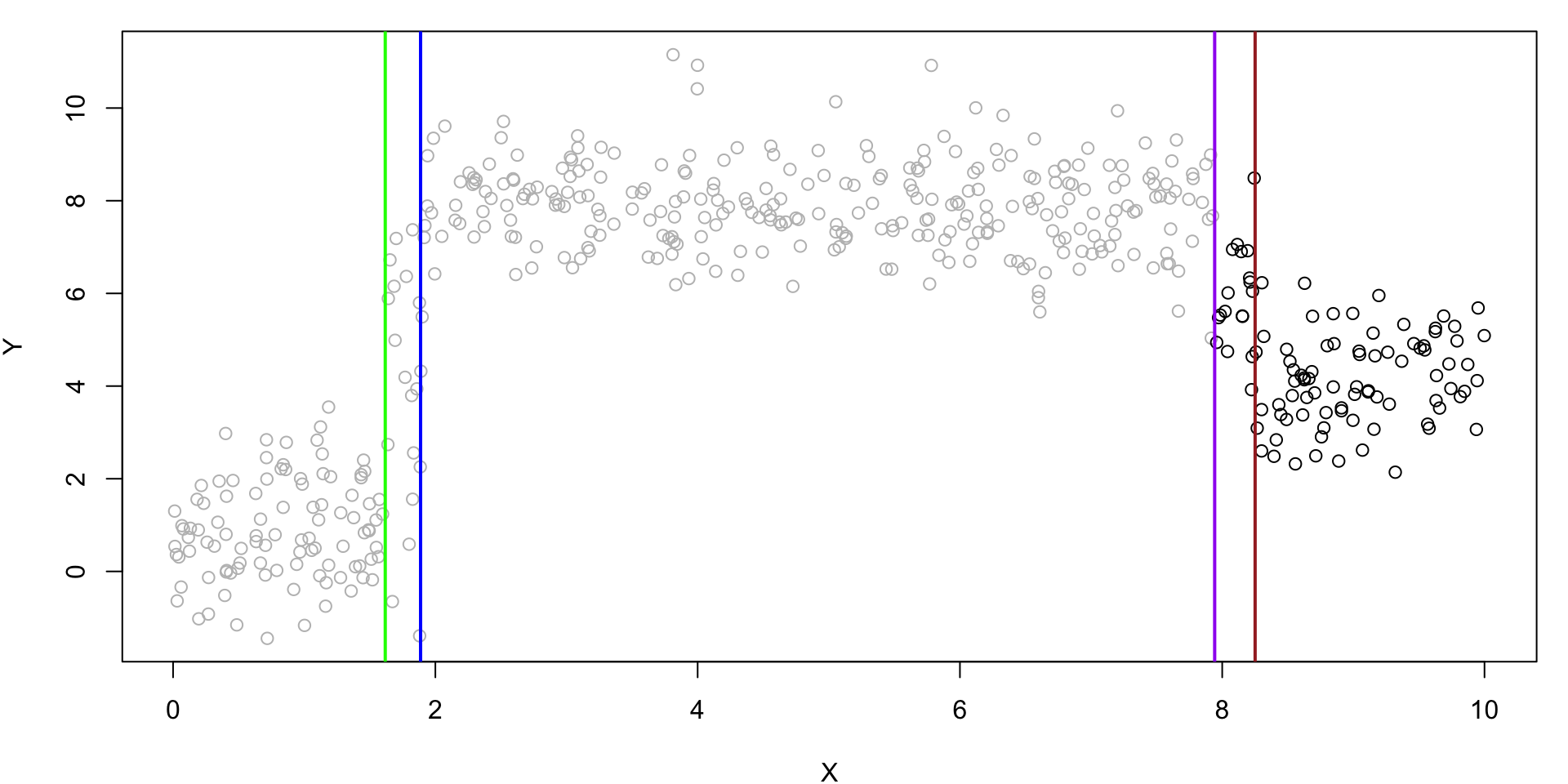

Rule 1: No. Rule 3 No. Rule 4 Yes.
predict 5.935194

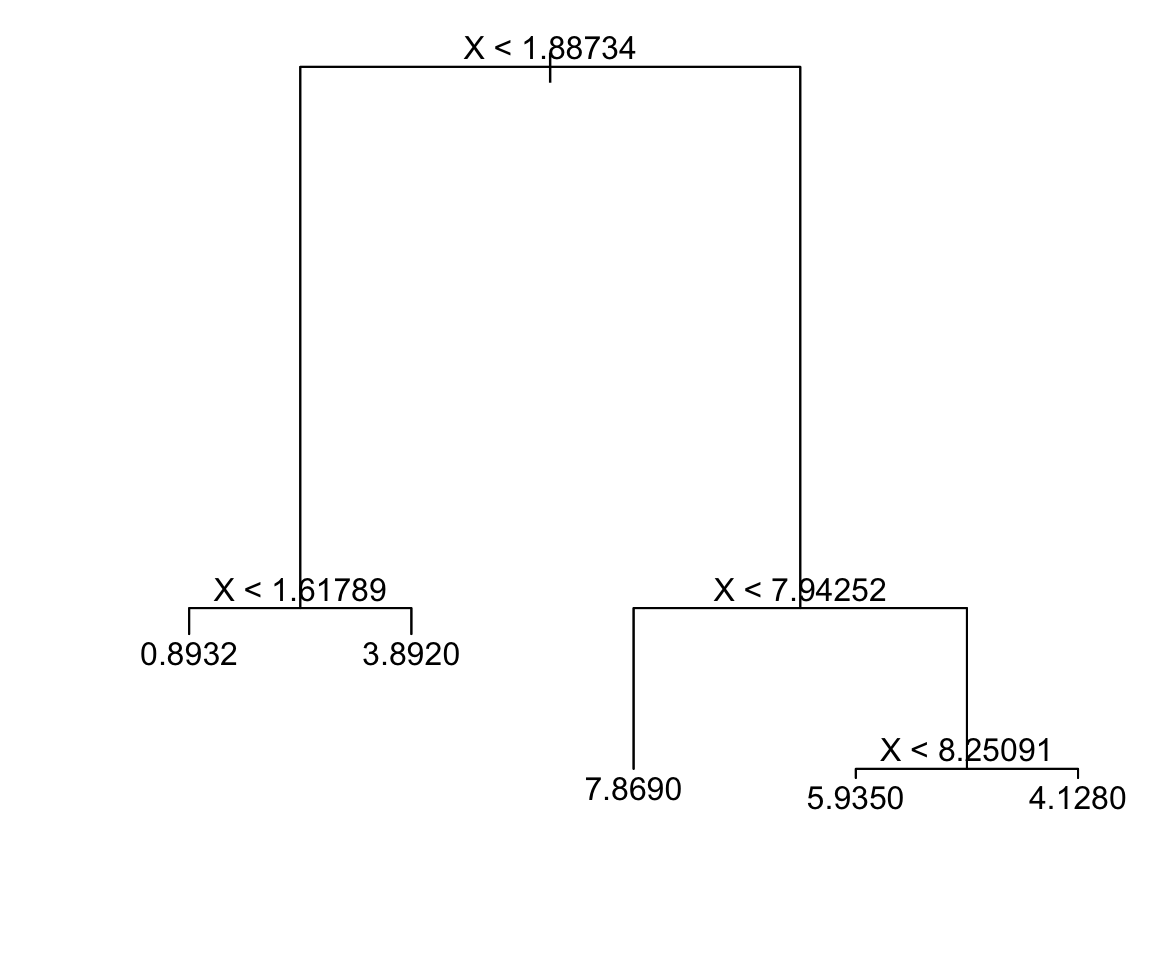
Rule 1: No. Rule 3 No. Rule 4 No.
predict 4.1281582


Optimal \(\alpha\)
It turns out, no pruning needed, according to CV.

Bushy Tree

cross validation

Pruned Tree

Non-deterministic

Pruned tree with 6 terminal nodes

Classification Example
Back to the motivating example for classification.

Full tree
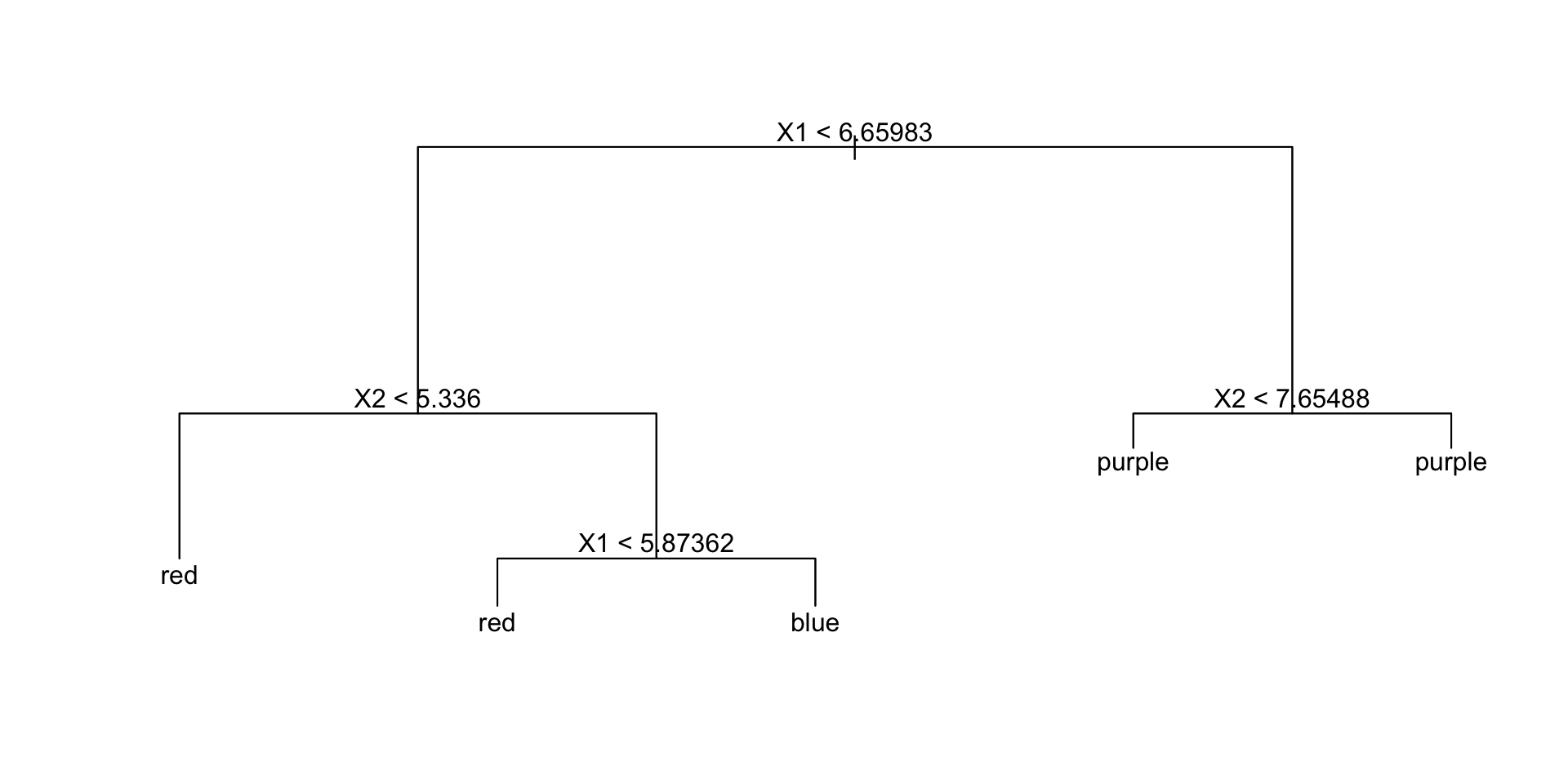
Rules
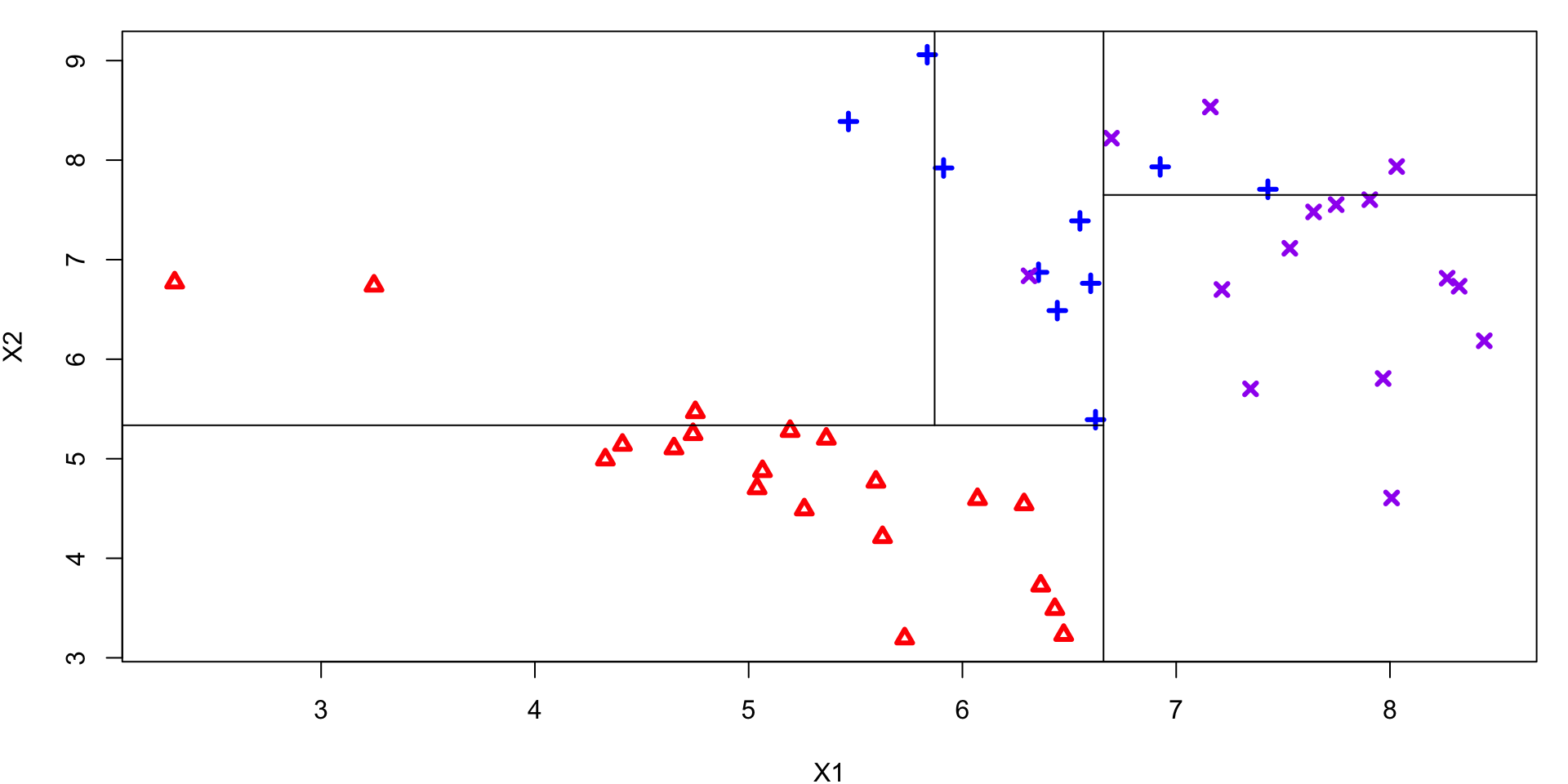
Plotted Tree
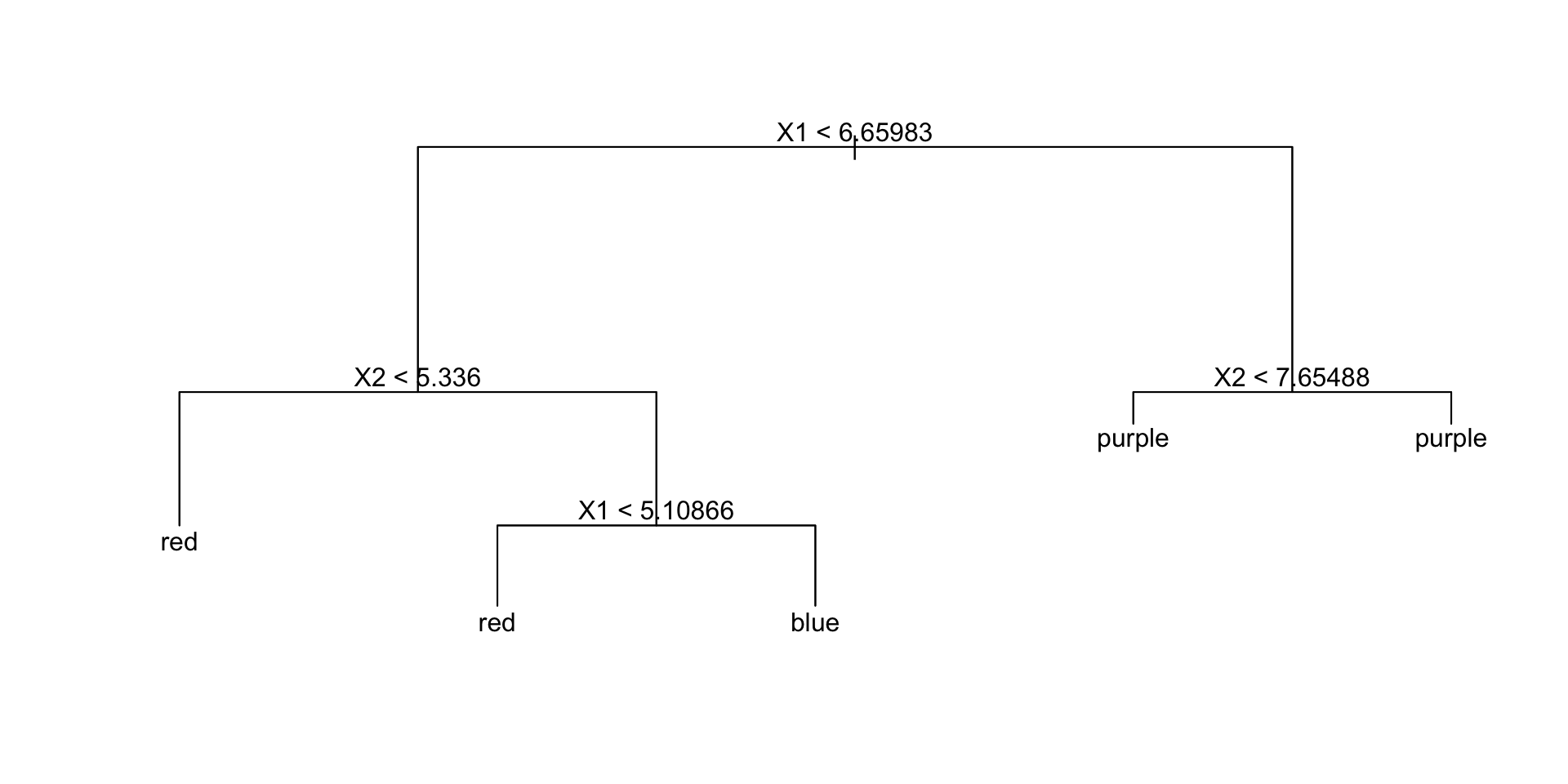
Updated Rules
Using mincut = 3 our partition of the predictor space becomes …

No further pruning needed
Change the error metric from deviance to misclassification:


ISLR Fig 8.7 (top). A 2D classification example in which the true decision boundary is linear, and is indicated by the shaded regions. A classical approach that assumes a linear boundary (left) will outperform a decision tree that performs splits parallel to the axes (right).

ISLR Fig 8.7 (bottom): Here the true decision boundary is non-linear. Here a linear model is unable to capture the true decision boundary (left), whereas a decision tree is successful (right).
Comments
We have assumed that the predictor variables take on continuous values. However, decision trees can be constructed even in the presence of qualitative predictor variables.
A split on a categorical variable amounts to assigning some of the qualitative values to one branch and assigning the remaining to the other branch.