where \(\hat y_0\) is the predicted class label that results from applying the classifier to the test observation with predictor \(x_0\).
Bayes Classifier
“Bayes classifier” is a general concept that refers to any classifier that makes predictions based on Bayes theorem
A Bayes classifier calculates the probability of a particular class given a set of features and then selects the class with the highest probability as the prediction.
It can be shown1 that the Bayes Classifier minimizes the testing error given on the previous page.
\(P(A|B)\) is the conditional probability of event A occurring given that event B has occurred.
\(P(B|A)\) is the conditional probability of event B occurring given that event A has occurred.
\(P(A)\) is the marginal probability of event A
\(P(B)\) is the marginal probability of event B
Definition
The Bayes classifier assigns each observation to the most likely class, given its predictor/input values (i.e. \(X\)s ).
That is, for some predictor vector \(x_0=(x_{01}, x_{02}, \ldots, x_{0p})\) we should assign the class \(j\) where the following conditional probability is maximized: \[P(Y=j \mid X=x_0)\]
Bayes Decision Boundary Definition
For the two class problem the Bayesian decision boundary is defined as the line where
\[P(Y=1 \mid X=x_0) = P(Y=2 \mid X=x_0)\]
This boundary separates the feature space into two decision regions:
Region 1 points for which \(P(Y = 1 \mid X = x_0) > 0.5\) and are assigned to class 1
Region 2 points for which \(P(Y = 1 \mid X = x_0) < 0.5\) and are assigned to class 2
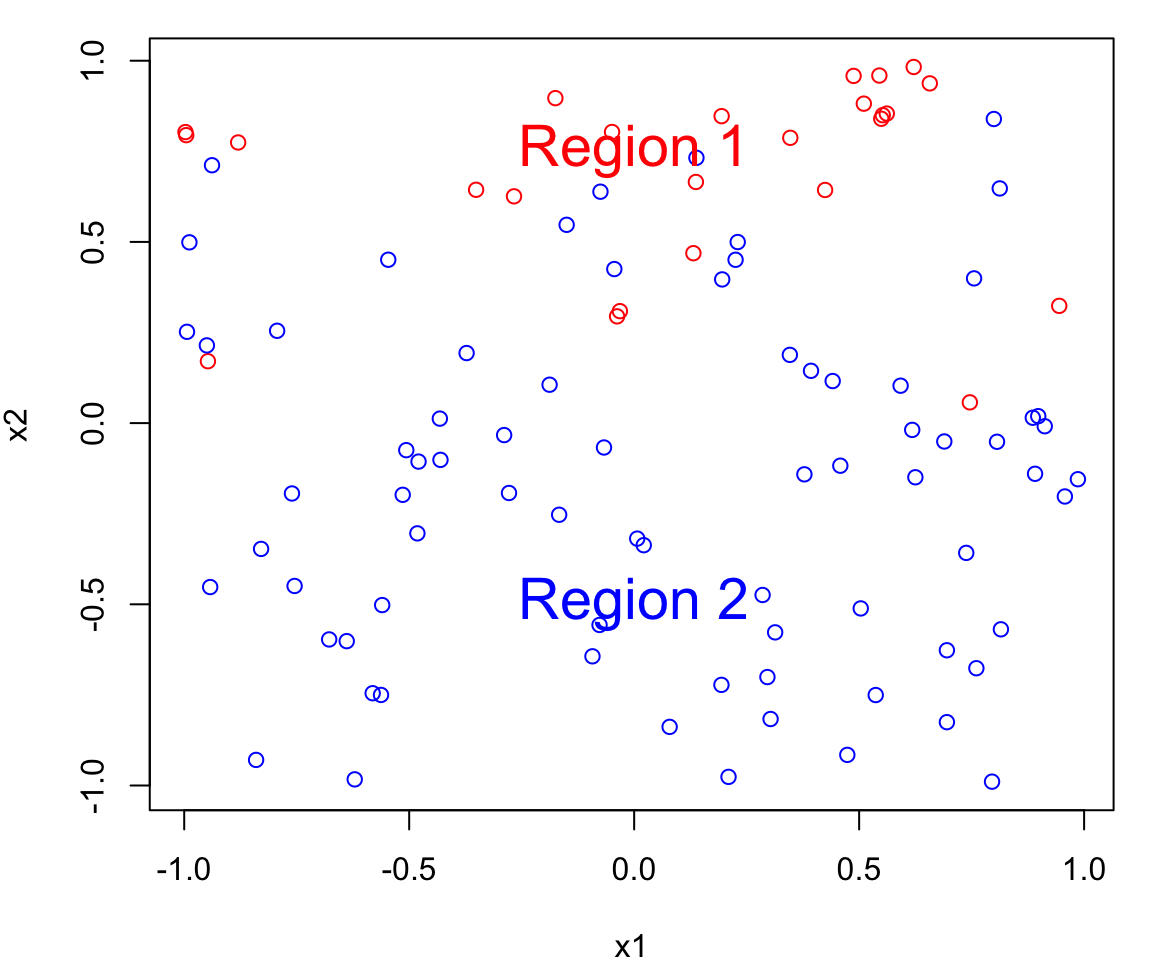
Bayes Classifier Example
Let’s simulate a data set with of two continuous predictors \(X_1\) and \(X_2\); both uniformly distributed from \([-1, 1]\).
We create two classes:
a red group (corresponding to \(Y=0\)) and
a blue group (corresponding to \(Y=1\))
To generate the class assignment we will only using \(X_2\).
That is \(X_1\) is represents a useless predictor.
Class generation
We will assign an observation to a class based on the following:
Notice that \(x_{1i}\) does not provide any information about the class.
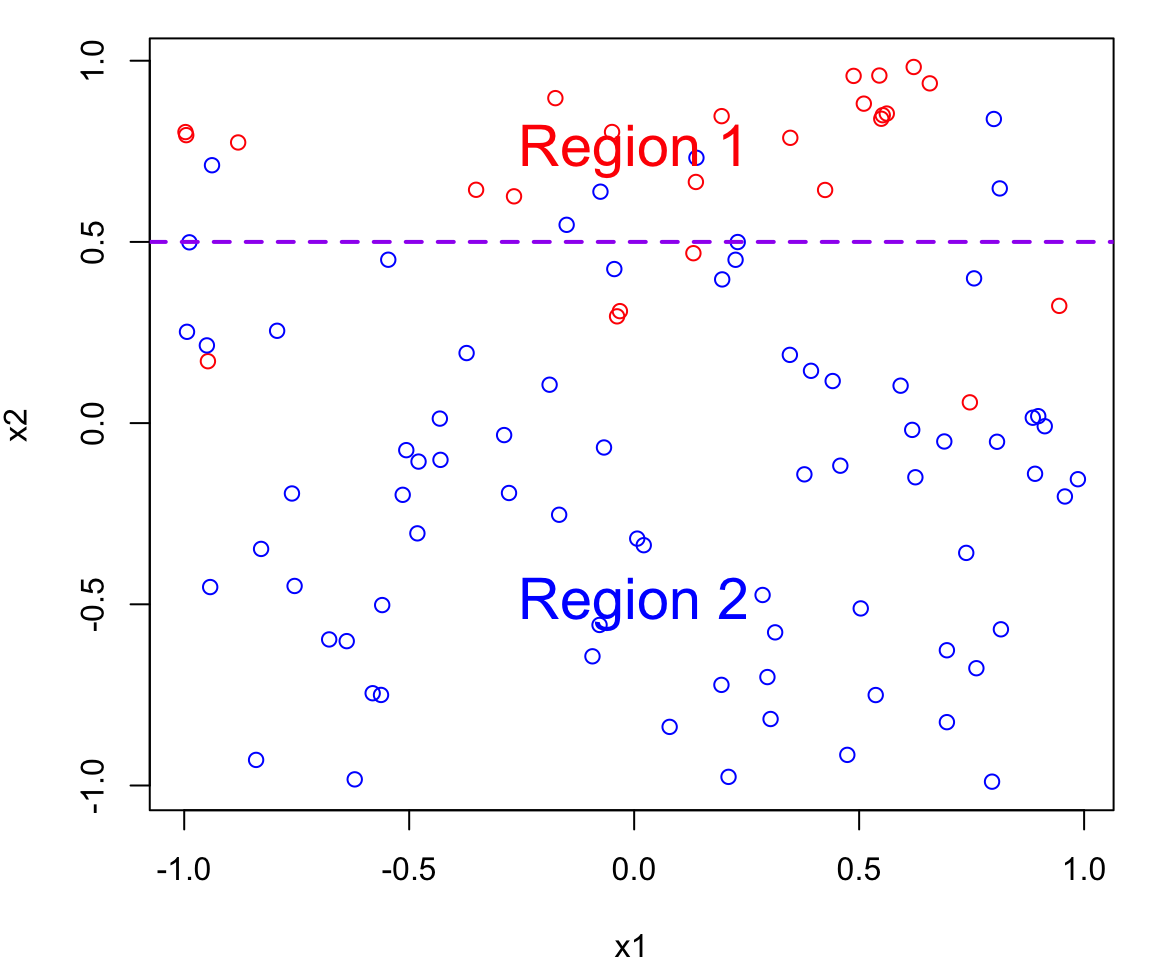
Bayes Decision Boundary
The Bayes decision boundary represents the dividing line in the feature space (i.e. in terms of \(X\)s) that determines how data points are classified into different classes.
In our case data points below the decision boundary (Region 1) are classified as red, while data points above the decision boundary (Region 2) are classified as blue
Note that errors are still going to be made using this classifier since the process is random (points near the boundary are sometimes going to red in Region 2 and sometimes blue in Region 1)
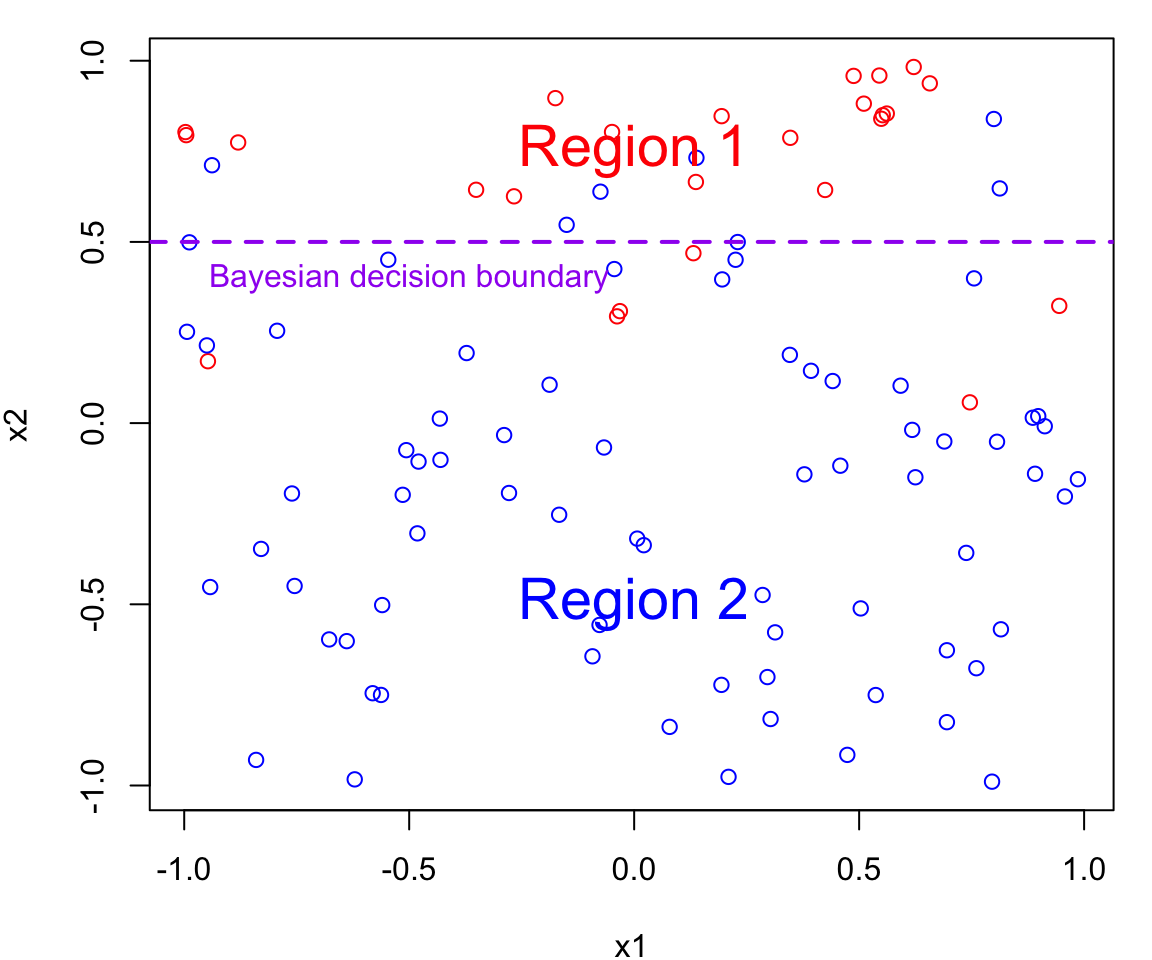
Optimal Boundary
The Bayes decision boundary represents the optimal decision boundary because it’s based on the true underlying probability distributions of the data.
In other words, the Bayes decision boundary is going to make fewer mistakes than any other classifier you will come up with.
Note
In practice, these distributions are often unknown and need to be estimated from data, which can introduce uncertainty.
Bayes Error Rate
On average, Bayes classifier will yield the lowest possible test error rate given by the following expectation (averages the probability over all possible values of \(X\)) \[1-E\left( \max_j P(Y=j \mid X) \right)\]
The above is called the Bayes error rate which represents the minimum possible error rate that any classifier can achieve for a given classification problem.
From simulations to real data
In theory we would always like to predict qualitative responses using the Bayes classifier.
But for real data, we do not know the conditional distribution of \(Y\) given \(X\), and so computing the Bayes classifier is impossible.
Therefore, the Bayes classifier serves as an unattainable gold standard against which to compare other methods.
Classification Algorithms
Many approaches attempt to estimate the conditional distribution of \(Y\) given \(X\), and then classify a given observation to the class with highest estimated probability.
For example, Logisitic Regression modeled
\[
\Pr(Y_i = 1 \mid X_i = x_i)
\tag{1}\]
and \(X_i\) is assigned class 1 if this probability is \(\geq 0.5\).
Another example is the \(K\)-nearest neighbors (KNN) \(\dots\)
KNN Classification
Given a positive integer \(K\) and a test observation \(x_0\), the KNN classifier first identifies the \(K\) points in the training data that are closest to \(x_0\), represented by \(\mathcal{N}_0\).
For each class \(j\), find \[\begin{equation}
P(Y=j \mid X=x_0) \approx \frac{1}{K} \sum_{i \in N_0} I(y_i = j)
\end{equation}\]
Assign observation \(x_0\) to the class (\(j\)) for which the above probability is largest; “ties” are typical broken at random (i.e. a coin toss)
in R
To demo knn classification we will be using the knn function from the class package performs (other alternatives exist)
library("class")knn(train, test, cl, k)
train matrix or data frame of training set cases.
test matrix or data frame of test set cases.
cl factor of true classifications of training set
k number of neighbours considered.
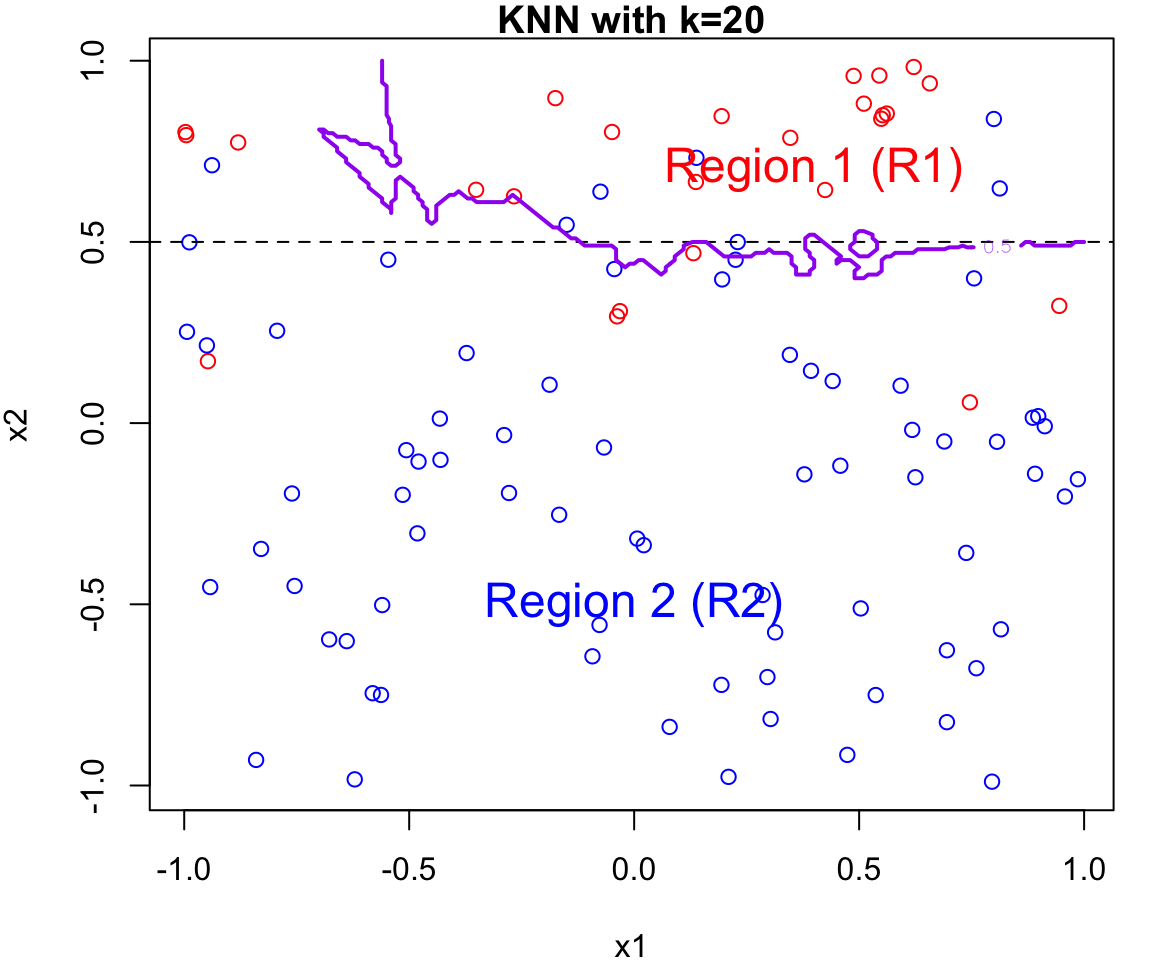
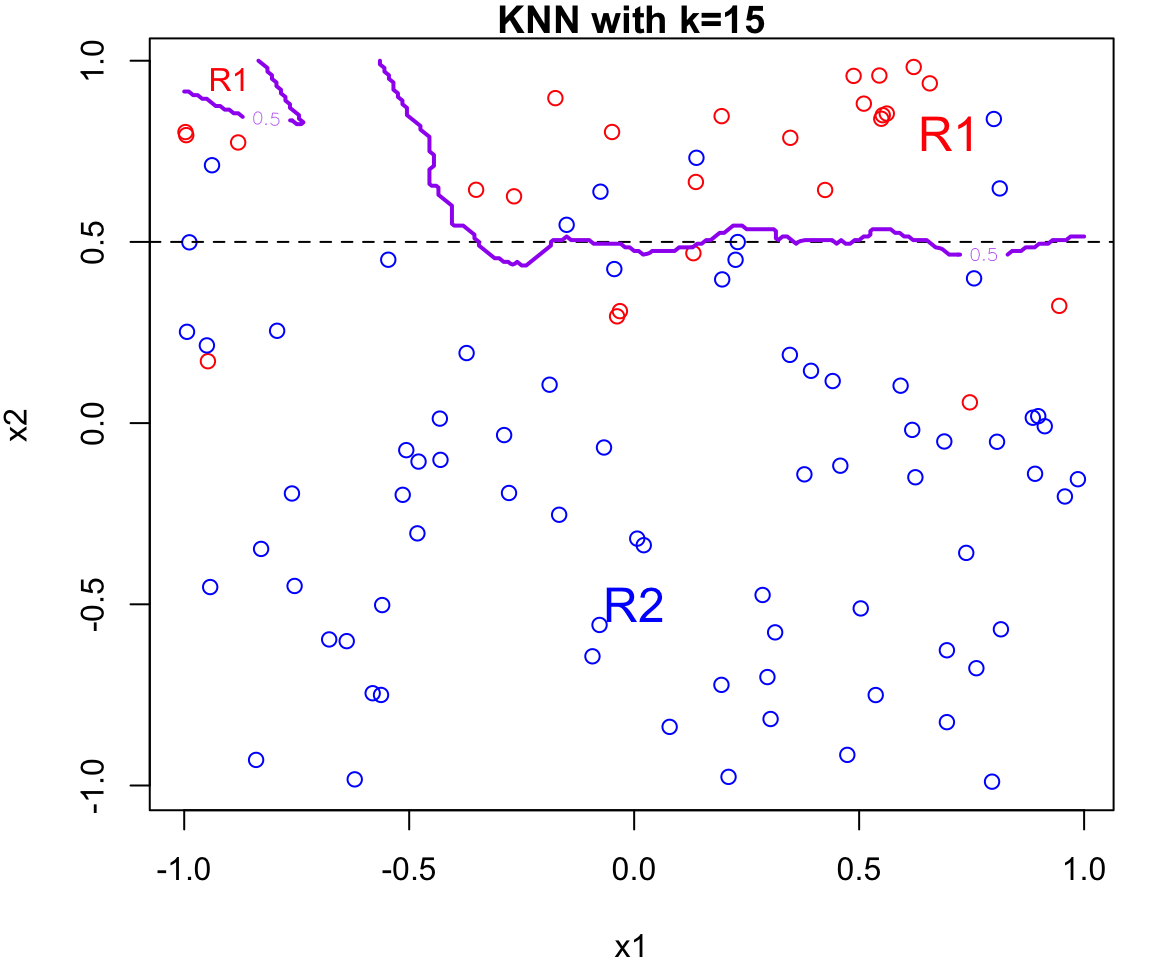
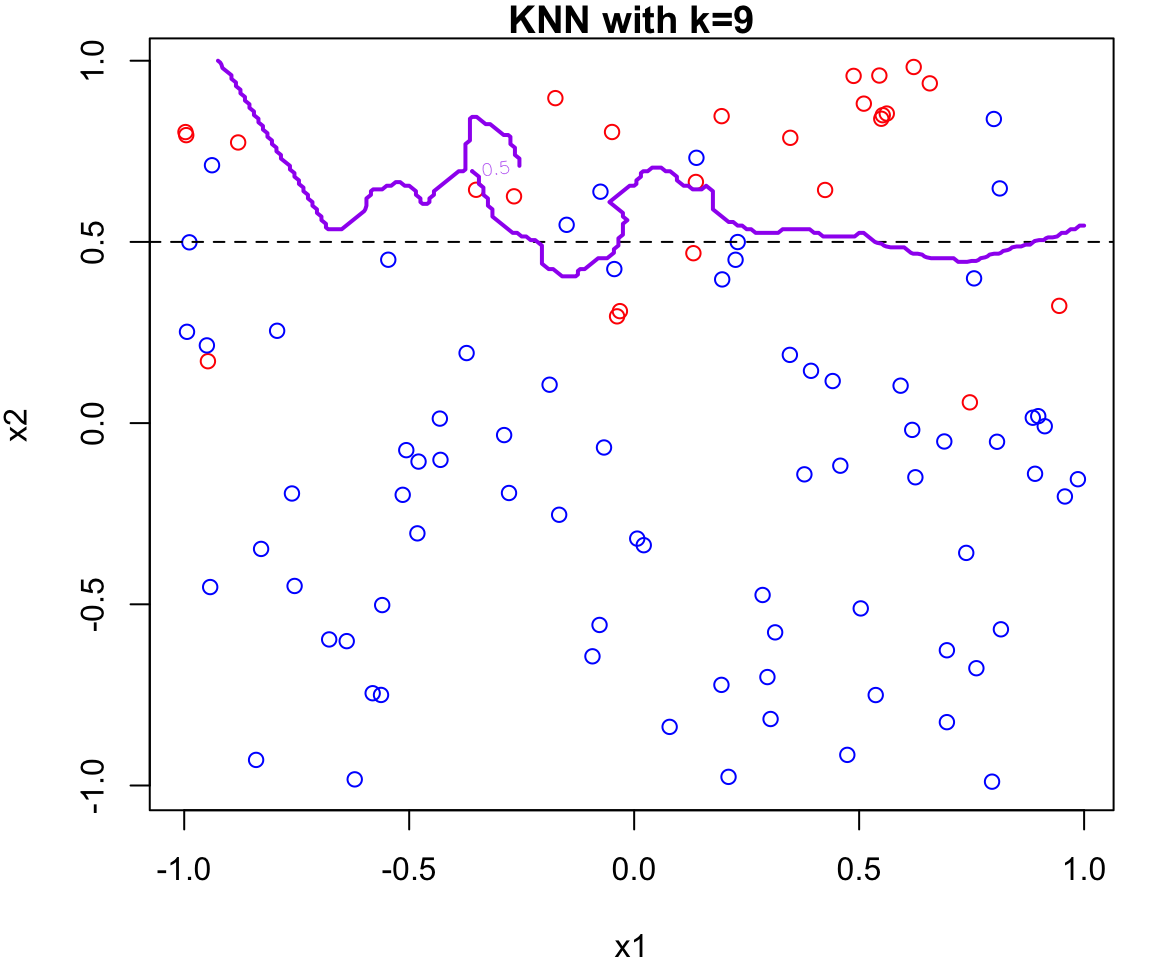
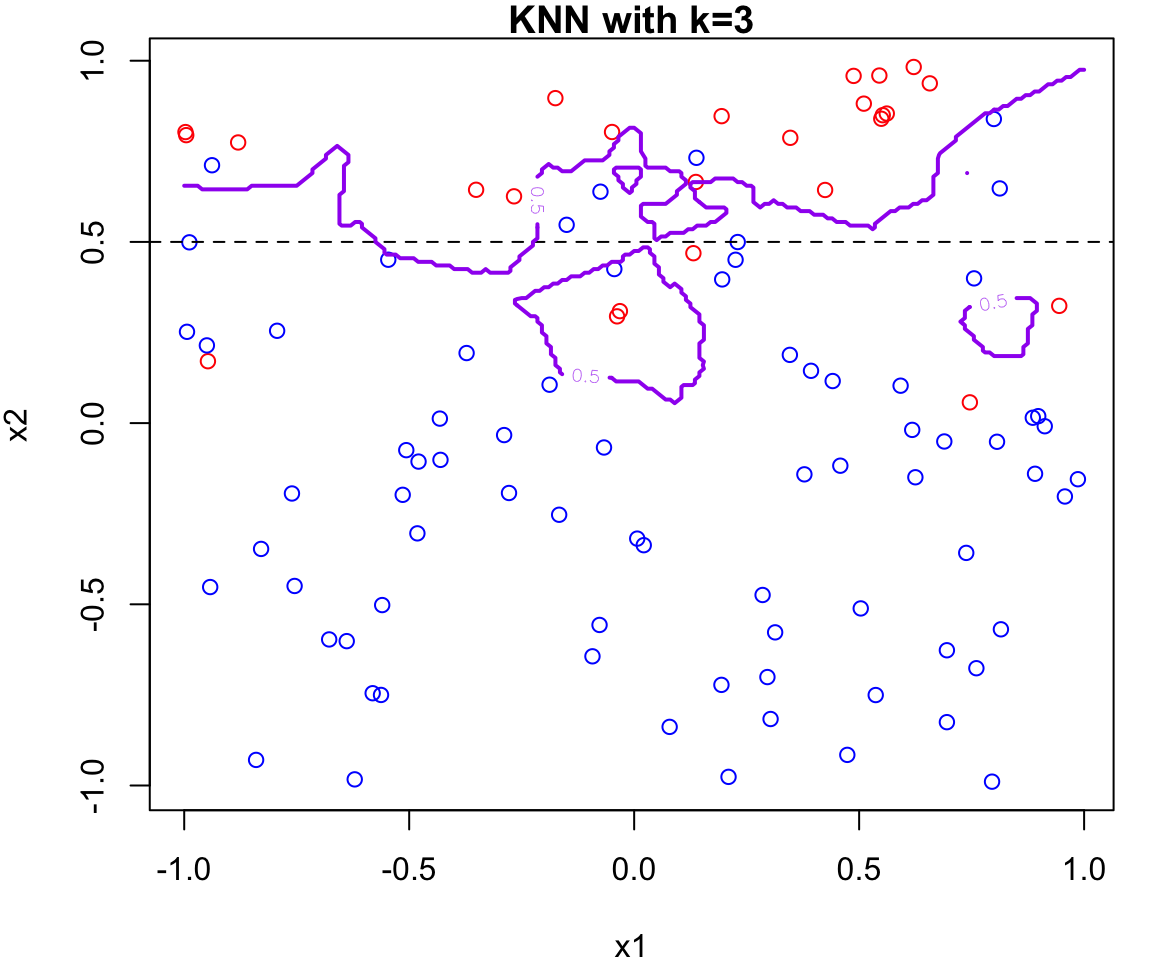
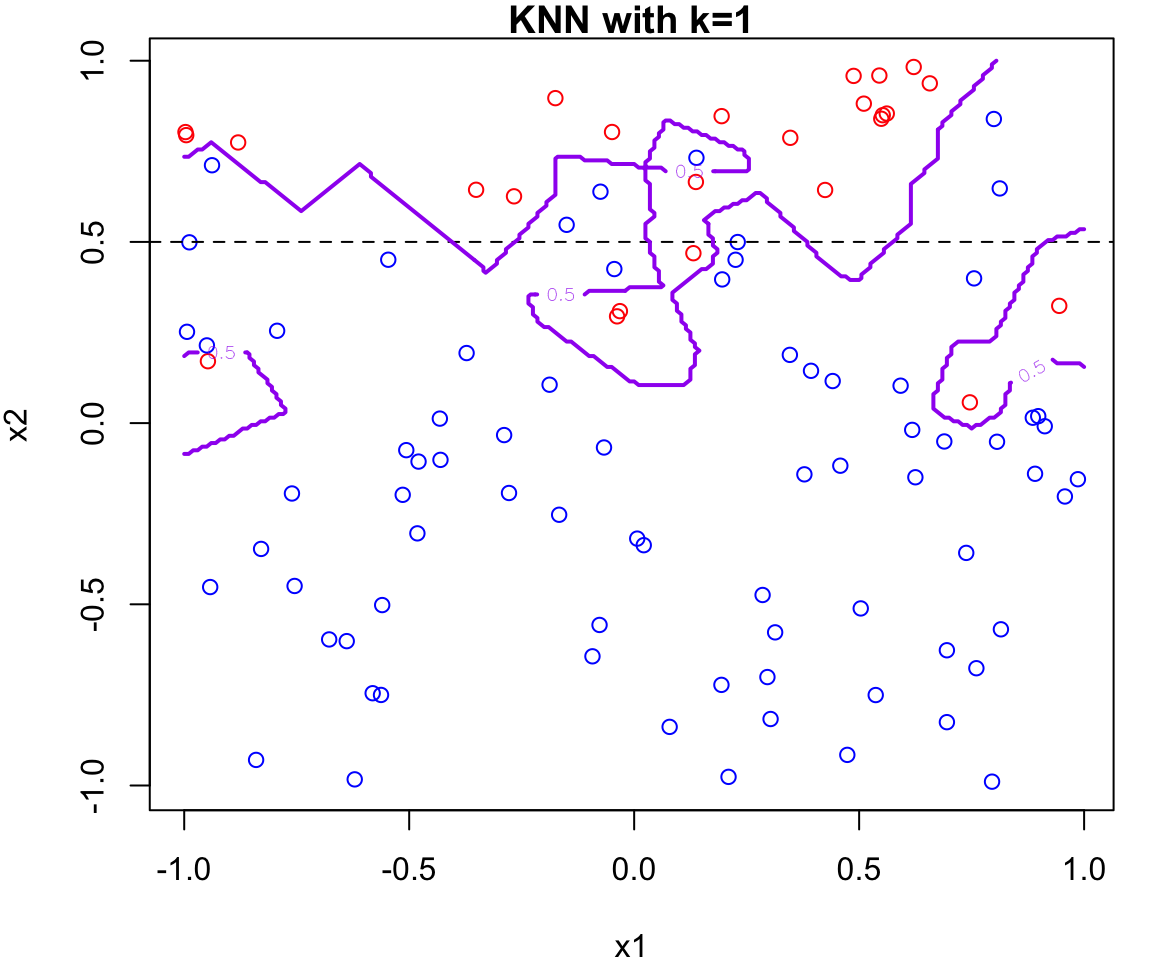
k Nearest Neighbours Example
Let’s apply this algorithm to the simulated data considered previously.
More specifically, we will fit knn for \(k = 20, 15, 9, 3\) and \(1\)
Fair warning that the decision boundary and decision regions will not be as clear cut as our previous example.
We will assess the error rate for each (code presented in lab)
Let’s discuss linear and quadratic discriminant analysis as alternative methods for approximating the conditional distribution of \(Y\) given \(X\)\(\dots\)
Bayes Theorem
\[
\Pr(Y = k \mid \boldsymbol x) = \frac{\Pr(\boldsymbol x \mid Y = k)\cdot \Pr(Y = j)}{\sum_{j} \Pr(\boldsymbol x \mid Y = k)\cdot \Pr(Y = k)}
\]
we can assume some model for \(\Pr(\boldsymbol x \mid Y = k) \sim f_k(\boldsymbol x)\) (e.g. Gaussian)
\(\Pr(Y=k)\) is the prior, denoted \(\pi_k\). It represents the prior probability of observation \(\boldsymbol x\) belonging to class \(k\)
Posterior Probabilities
Then Bayes’ theorem states that
\[\begin{equation}
\Pr(Y = k \mid X = x) = \frac{\pi_k f_k(x)}{\sum_{l=1}^{K} \pi_l f_l(x)}
\end{equation}\]
This represents the posterior probability that an observation \(X = x\) belongs to the \(k\)th class.
To estimate \(p_k(x)\), and thereby approximate the Bayes classifier, we can need to estimate the \(\pi_k\)s and \(f_k(x)\).
Discriminant Analysis
We assume a normal (Gaussian) distributions with mean vector \(\boldsymbol{\mu}_k\) and covariance matrix \(\boldsymbol{\Sigma}_k\) for each class
Depending on our assumptions on \(f_k(\boldsymbol x)\), this leads to linear discriminant analysis (LDA) or quadratic discriminant analysis (QDA).
Which class does the new point as indicated by the star belong to?
To answer this, it might be useful to talk about a decision boundary.
This will depend on our priors and parameters.
Generative Models for Classification
For simplicity, let’s suppose we have two classes, that is \(Y\) can take on two possible values \(K = 1\) or \(K = 2\)
Let \(f_k(X) \equiv \Pr(X\mid Y = k)\) denote the pdf of \(X\) for an observation that comes from the \(k\)th class.
Let \(\pi_k\) represent the overall or prior probability that a randomly chosen observation comes from the \(k\)th class.
LDA for one predictor
For simplicity let’s assume \(x\) is univariate so that \(f_k(x)\) be the is univariate Normal distribution with mean \(\mu_k\) and \(\sigma_k^2\) for an observation from the \(k\)th class.
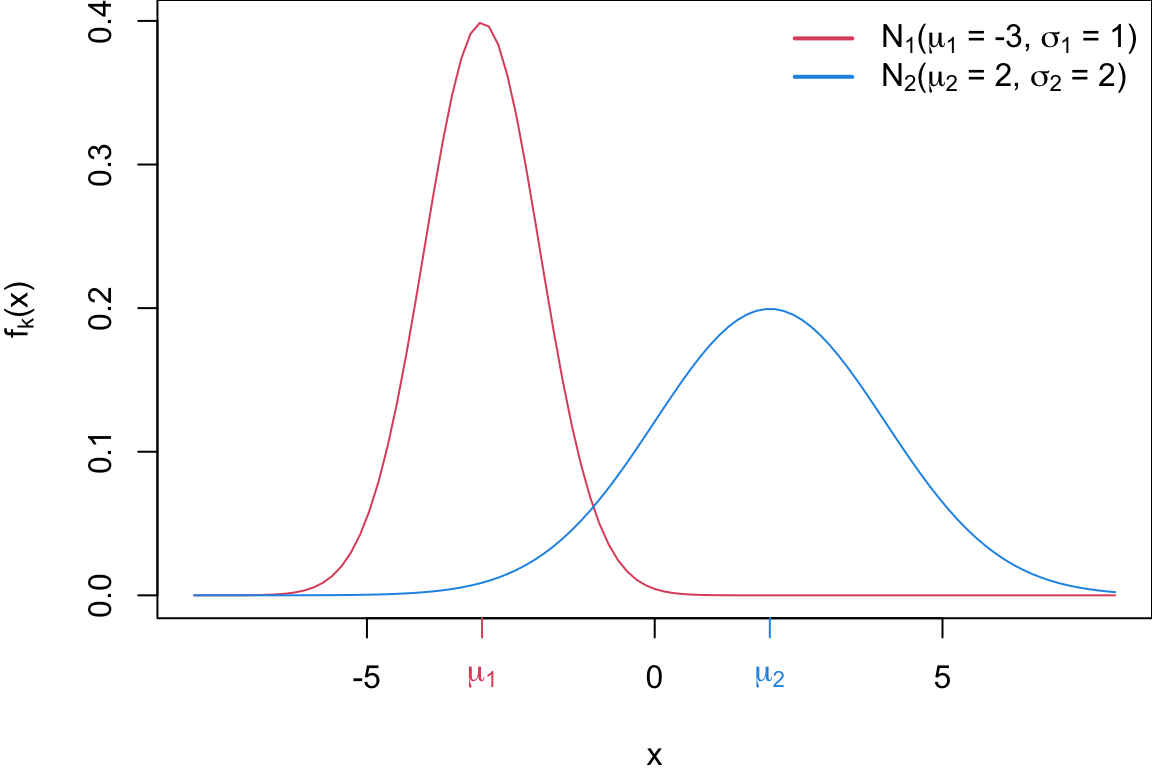
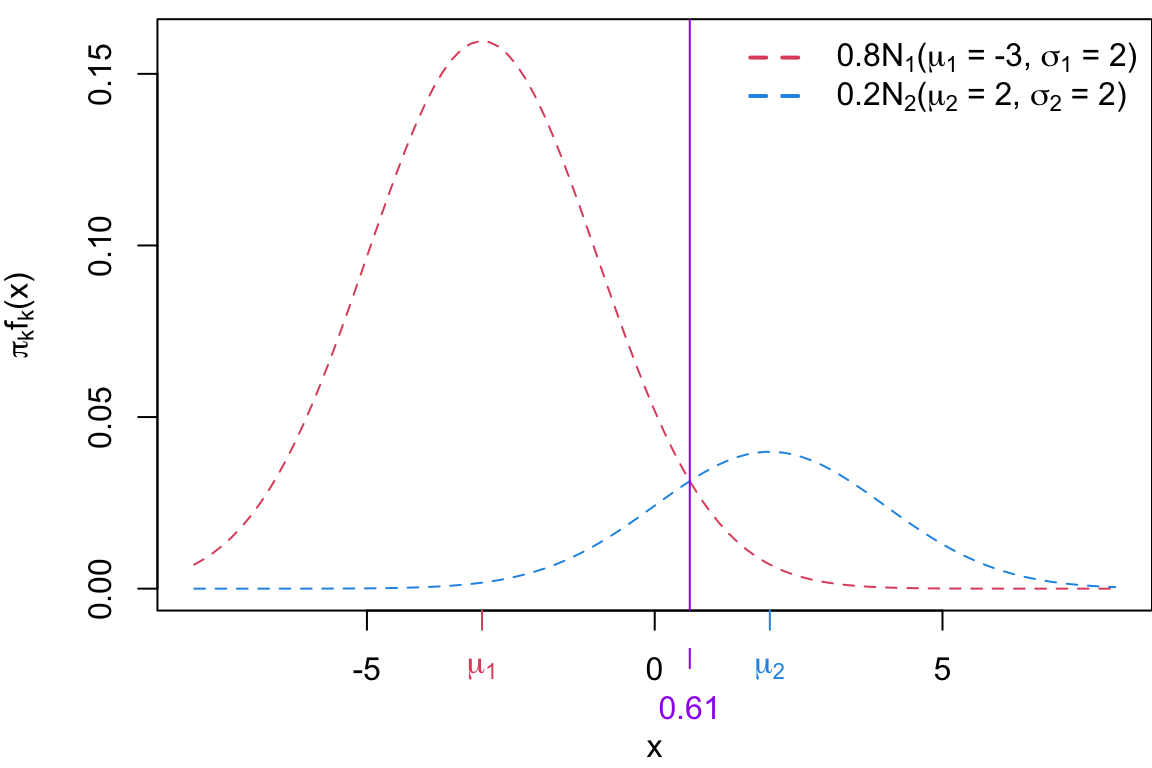
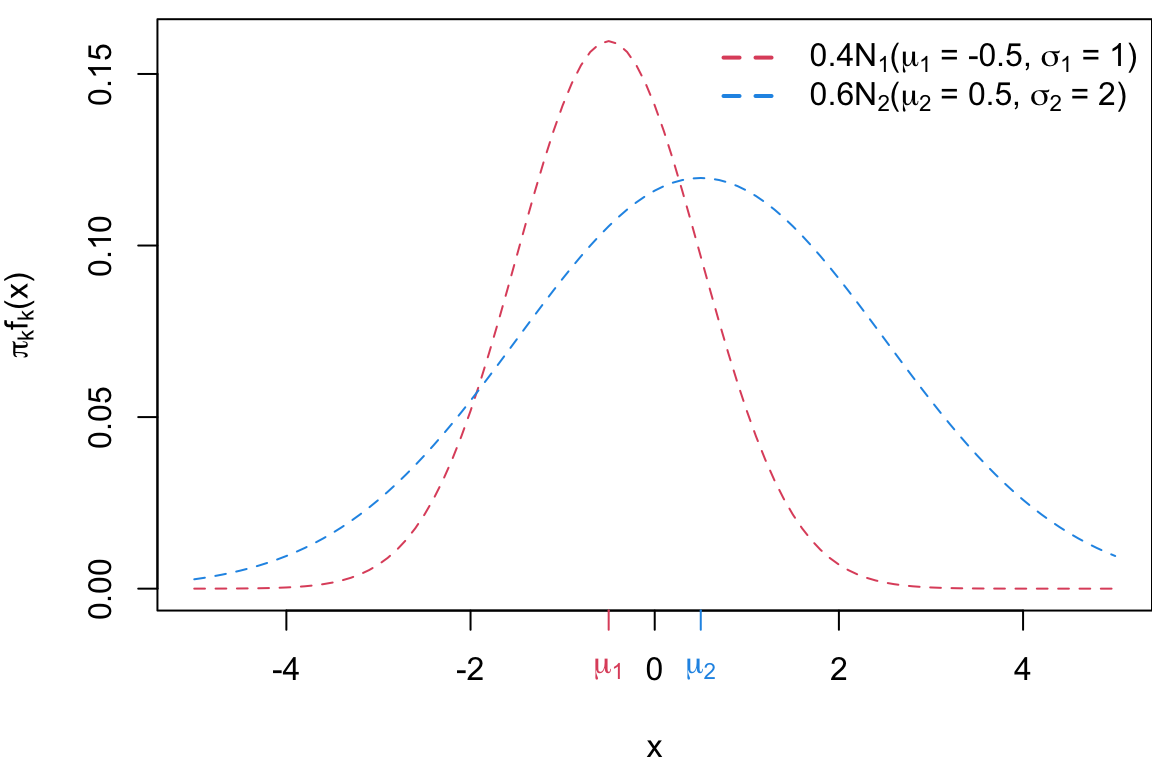
The red curve represents \(f_1 = N(\mu_1 = -3, \sigma_1 = 1)\), and the blue curve represents \(f_2 = N(\mu_2 = 2, \sigma_2 = 2)\).
Code
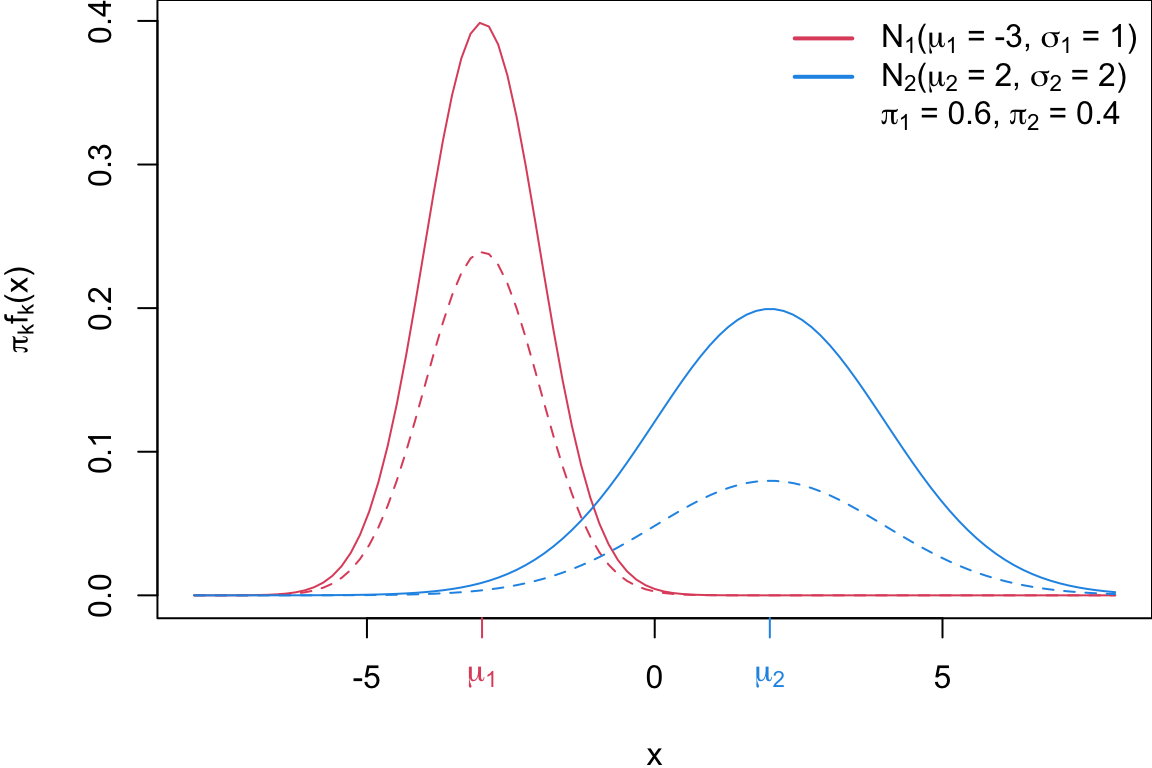
par(mar =c(3.9,4.1,0,0))pi1 =0.6pi2 =1- pi1curve(dnorm(x, mean = mean1, sd = sd1), col =2, from =-8, 8, ylab =expression(paste(pi[k]*f[k]*"("* x *")")), lty =1)curve(dnorm(x, mean = mean2 , sd = sd2), col =4, add =TRUE, lty =1)gmm <-function(x, pis, mus, sigs){ pis[1]*dnorm(x, mean = mus[1], sd = sigs[1]) + pis[2]*dnorm(x, mean = mus[2], sd = sigs[2]) } # curve(gmm(x, c(pi1, pi2), c(mean1, mean2), c(sd1, sd2)), col = 3, add = TRUE)curve(pi1*dnorm(x, mean = mean1, sd = sd1), col =2, from =-8, 8, ylab =expression(paste(pi[k]*f[k]*"("* x *")")), lty =2, add =TRUE)curve(pi2*dnorm(x, mean = mean2 , sd = sd2), col =4, add =TRUE, lty =2)axis(1, at=mean1, labels =expression(mu[1]), col=2, col.axis=2)axis(1, at=mean2, labels =expression(mu[2]), col=4, col.axis=4) ltext <-c(bquote(N[1]*"("*mu[1] *" = "* .(mean1)*", "*sigma[1] *" = "* .(sd1) *")"),bquote(N[2]*"("*mu[2] *" = "* .(mean2)*", "*sigma[2] *" = "* .(sd2)*")"),bquote(pi[1] *" = "* .(pi1)*", "*pi[2] *" = "* .(pi2)))legend("topright", lwd=2, col =c(2,4,NA), legend = ltext, bty ="n")
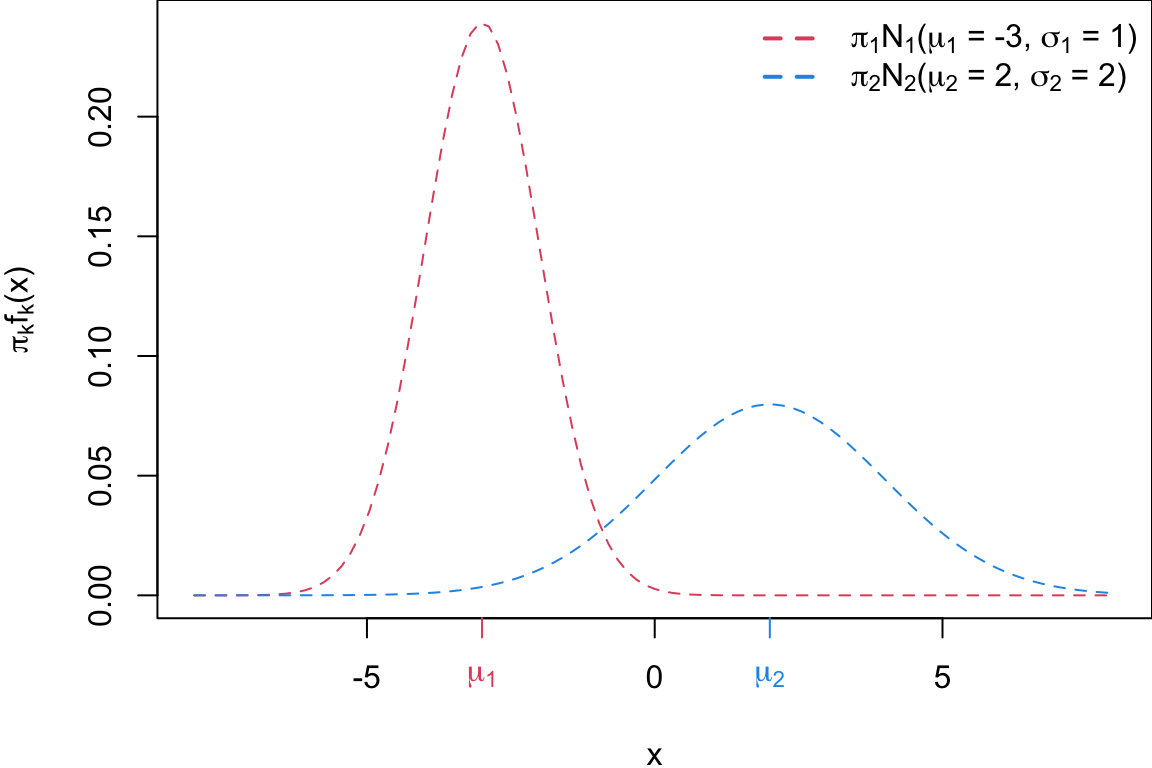
The solid lines denote \(f_k\), the dashed lines show \(\pi_k * f_k\), i.e. the distributions weighted by their class probabilities \(\pi_1 = 0.6\) and \(\pi_2 = 0.4\).
Building a classifier
We classify new points according to whichever numerator \((\pi_k f_k(x))\) is the highest.
Question: where would that decision boundary be on this picture?
Case 1
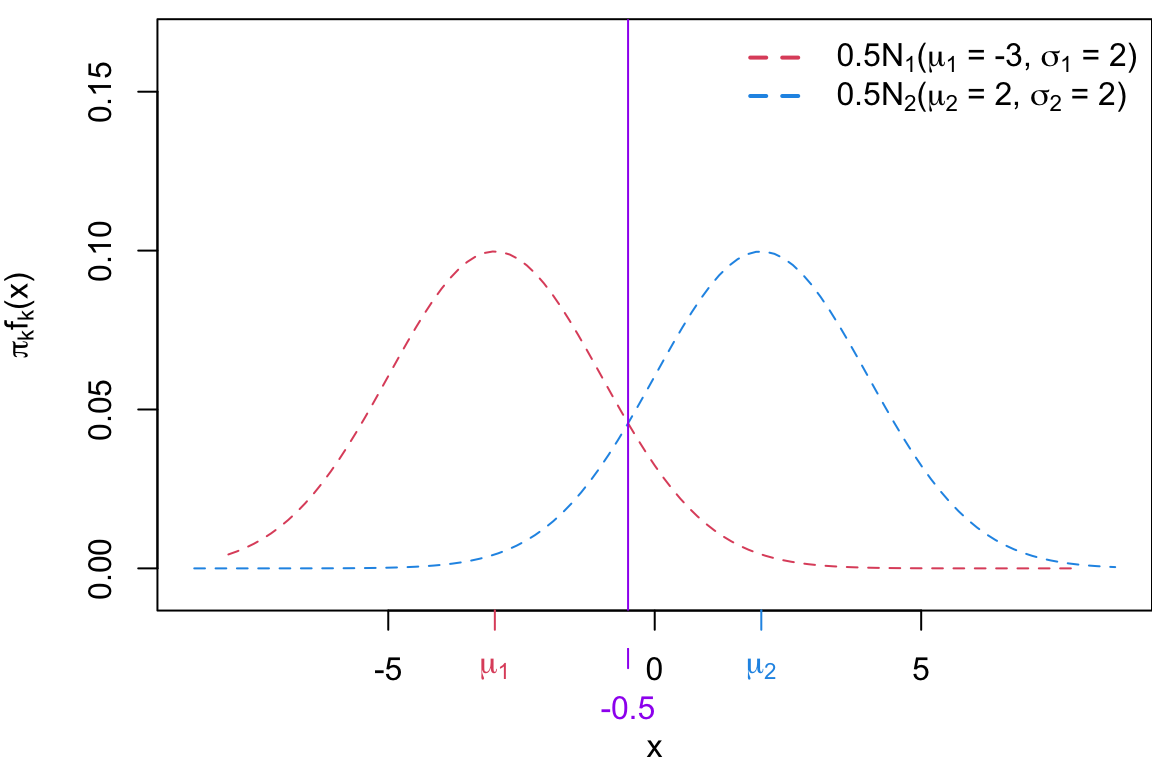
Case 1: \(\sigma_1 = \sigma_2\) and \(\pi_1 = \pi_2\) If the class variances and priors are equal, we have a linear decision boundary which is simply the average of the means: \(x = \frac{\mu_1 + \mu_2}{2}\)
Case 2
Case 2: \(\sigma_1 = \sigma_2\) and \(\pi_1 \neq \pi_2\) If the class variances are samle and the priors are different, the decision boundary is still linear but shifted toward the class with the lower prior probability (the less likely class), i.e. \(x = \frac{\mu_1 + \mu_2}{2} + \frac{\sigma^2}{\mu_1 - \mu_2} \log \left( \frac{\pi_1}{\pi_2} \right)\)
Case 3
Case 3: \(\sigma_1 \neq \sigma_2\) and \(\pi_1 \neq \pi_2\) If the class variances are samle and the priors are different, the decision boundary is non-linear (quadratic).
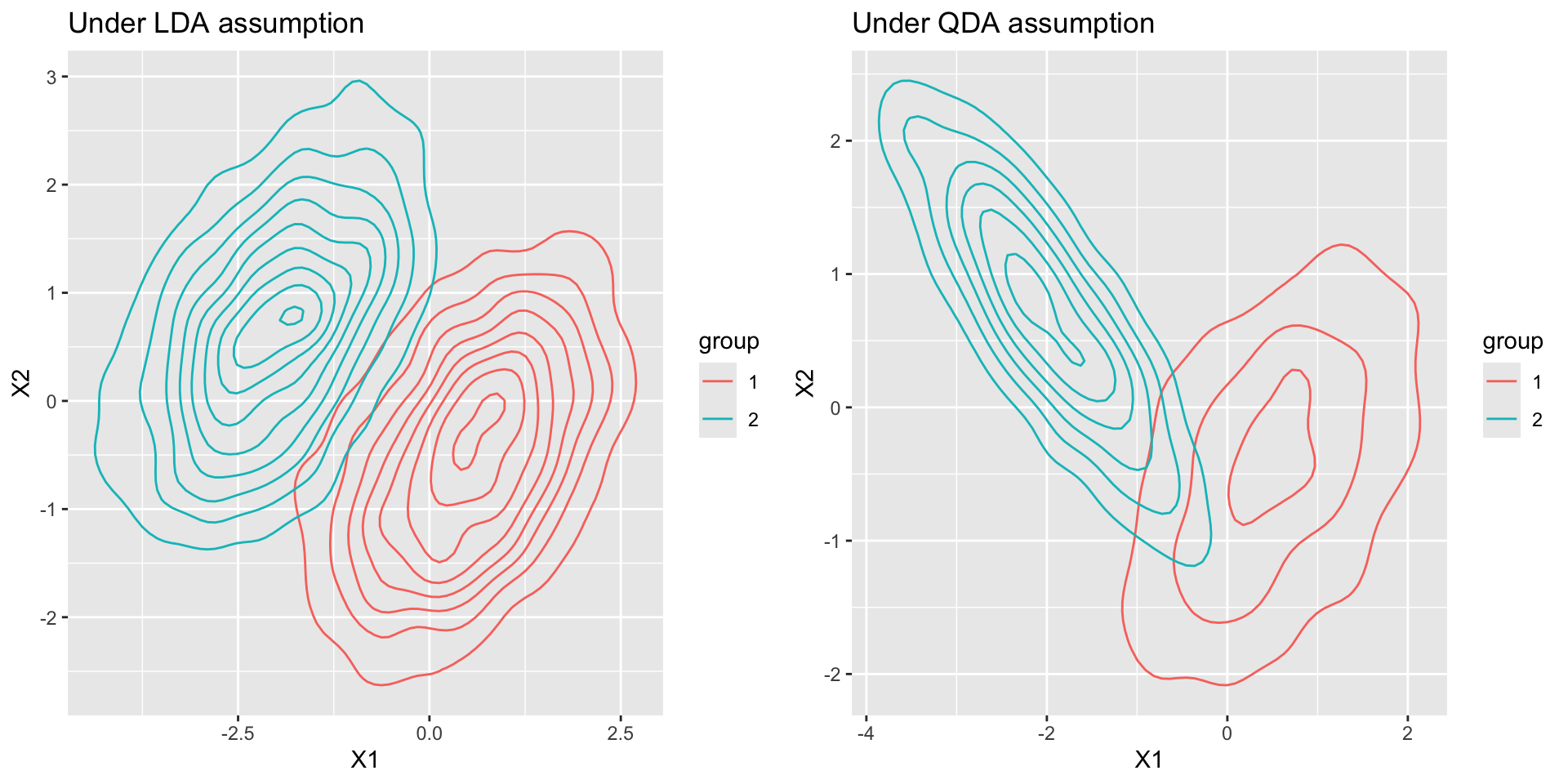
LDA vs QDA Assumptions
Linear Discriminant Analysis (LDA) assumes that the variances of all classes are equal, i.e., \(\sigma_1 = \sigma_2 = \sigma\), where \(\sigma\) represents the common variance.
When we relax this assumption and allow for different variances between the groups, we get Quadratic Discriminant Analysis (QDA). In QDA, we have \(\sigma_1 \neq \sigma_2\), meaning the variances differ across the classes.
LDA decision boundary
Since we’re dealing with two classes, we can set the decision boundary where \(p_1(x) = p_2(x)\)
Assumption\(\sigma_1 = \sigma_2\) (but the \(\pi_k\)s will vary)
If the left-hand side (LHS) is greater than the right-hand side (RHS), the observation is classified as \(y = 1\). If LHS \(<\) RHS, the observation is classified as \(y = 2\).
We can simplify the expression for each class \(k\) as:
This is boils down to to assigning the observation to the class for which discriminant score\(\delta_k(x)\) is the largest: \[\begin{equation}
\delta_k(x) = x \cdot \frac{\mu_k}{\sigma^2} - \frac{\mu_{k}^2}{\sigma^2} + \log(\pi_k)
\end{equation}\]
Notice the discriminant score is a linear function of \(\boldsymbol x\).
Linear Decision boundary
Case 1: Equal variance \(\sigma_1 = \sigma_2\) (equal priors)
Since we are assuming (\(\pi_1 = \pi_2\)), the prior terms \(\log(\pi_1)\) and \(\log(\pi_2)\) cancel out. Thus, the decision boundary is found by setting the two discriminant scores equal:
\[
\delta_1(x) = \delta_2(x)
\]
Substitute the discriminant score equations for \(\delta_1(x)\) and \(\delta_2(x)\):
\[
x \frac{\mu_1}{\sigma^2} - \frac{\mu_1^2}{2 \sigma^2} = x \frac{\mu_2}{\sigma^2} - \frac{\mu_2^2}{2 \sigma^2}
\]
ILSR2 Figure 4.4:Left: Two one-dimensional normal density functions are shown. The dashed vertical line represents the Bayes decision boundary. Right: 20 observations were drawn from each of the two classes, and are shown as histograms. The Bayes decision boundary is again shown as a dashed vertical line. The solid vertical line represents the LDA decision boundary estimated from the training data.
where \(n\) is the total number of training observations, \(n_k\) is the number of observations in class \(k\), and \(\mu_k\) and \(\hat{\sigma}^2_k\) are the MLE estimates for mean and (pooled) variance in the \(k\)th class.
Classifier
When we do not have equal variance (i.e \(\sigma_1 \neq \sigma_2\)) our classifier predicts \(x_0\) to group 1 if
ESL Figure 4.4: Left: shows some data from three classes, with linear decision boundaries found by LDA. Right: shows quadratic decision boundaries found using QDA.
LDA vs Logistic
Pros of LDA
If \(n\) is small and the distribution of the predictors \(X\) is approximately normal in each class, the linear discriminant model is more stable than the logistic regression model.
LDA is popular when we have more than two response classes
Cons of LDA
Assumes normality, i.e. that the features are normally distributed (which is not always appropriate).
Assumes homoscedasticity, meaning the classes share the same covariance matrix (strong assumption)
Multivariate Normal Distribution
For Discriminant analysis when \(p>1\) we use the Multivariate Normal Distribution (MVN).
A MVN random vector \(\mathbf X\), has probability distribution given by \[f(\mathbf x) = \frac{1}{(2\pi)^{p/2}|\boldsymbol{\Sigma}|^{1/2}} e^{-\frac{1}{2}(\mathbf{x}-\boldsymbol{\mu})^T\boldsymbol{\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu})}\] with mean vector \(\boldsymbol{\mu}\) and covariance matrix \(\boldsymbol{\Sigma}\).
The covariance matrix is symmetric a square matrix where each entry \(\Sigma_{ij}\) represents the covariance between variables \(X_i\) and \(X_j\)
The diagonal elements (\(\sigma_{i}\)) represent the variances of individual variables, and the off-diagonal elements (\(\sigma_{ij}\) for \(i\neq j\)) represent the covariances between pairs of variables. \[\begin{equation}
\boldsymbol \Sigma =
\begin{bmatrix}
\sigma_{1}^2 & \sigma_{12} & \ldots & \sigma_{1p} \\
\sigma_{12} & \sigma_{2}^2 & \ldots & \sigma_{2p} \\
\vdots & \vdots & \ddots & \vdots \\
\sigma_{1p} & \sigma_{2p} & \ldots & \sigma_{p}^2
\end{bmatrix}
\quad \text{ where }\sigma_{ij} = \sigma_{ji} = \text{Cov}(X_i, X_j)
\end{equation}\]
Uncorrelated
Code
# Install and load the required librarieslibrary(plotly)library(mvtnorm)# Parameters for the multivariate normal distributionmean_vec <-c(0, 0) # Mean vectorcov_mat <-matrix(c(1, 0, 0, 1), nrow =2) # Covariance matrix# Generate data gridx <-seq(-3, 3, length.out =100)y <-seq(-3, 3, length.out =100)grid <-expand.grid(x, y)# Calculate the multivariate normal density for each point in the gridz <-dmvnorm(grid, mean = mean_vec, sigma = cov_mat)# Reshape the z values to match the grid dimensionsz_matrix <-matrix(z, nrow =length(x), ncol =length(y))# Create an interactive 3D surface plot using plotlyplot_ly(z =~z_matrix, x =~x, y =~y, type ="surface") %>%layout(scene =list(xaxis =list(title ="X-axis"),yaxis =list(title ="Y-axis"),zaxis =list(title ="Density") ))
Code
# Install and load the required librarieslibrary(plotly)library(mvtnorm)# Parameters for the multivariate normal distributionmean_vec <-c(0, 0) # Mean vectorcov_mat <-matrix(c(1, 0.5, 0.5, 1), nrow =2) # Covariance matrix# Generate data gridx <-seq(-3, 3, length.out =100)y <-seq(-3, 3, length.out =100)grid <-expand.grid(x, y)# Calculate the multivariate normal density for each point in the gridz <-dmvnorm(grid, mean = mean_vec, sigma = cov_mat)# Reshape the z values to match the grid dimensionsz_matrix <-matrix(z, nrow =length(x), ncol =length(y))# Create an interactive 3D surface plot using plotlyplot_ly(z =~z_matrix, x =~x, y =~y, type ="surface") %>%layout(scene =list(xaxis =list(title ="X-axis"),yaxis =list(title ="Y-axis"),zaxis =list(title ="Density") ))
LDA when \(p>1\)
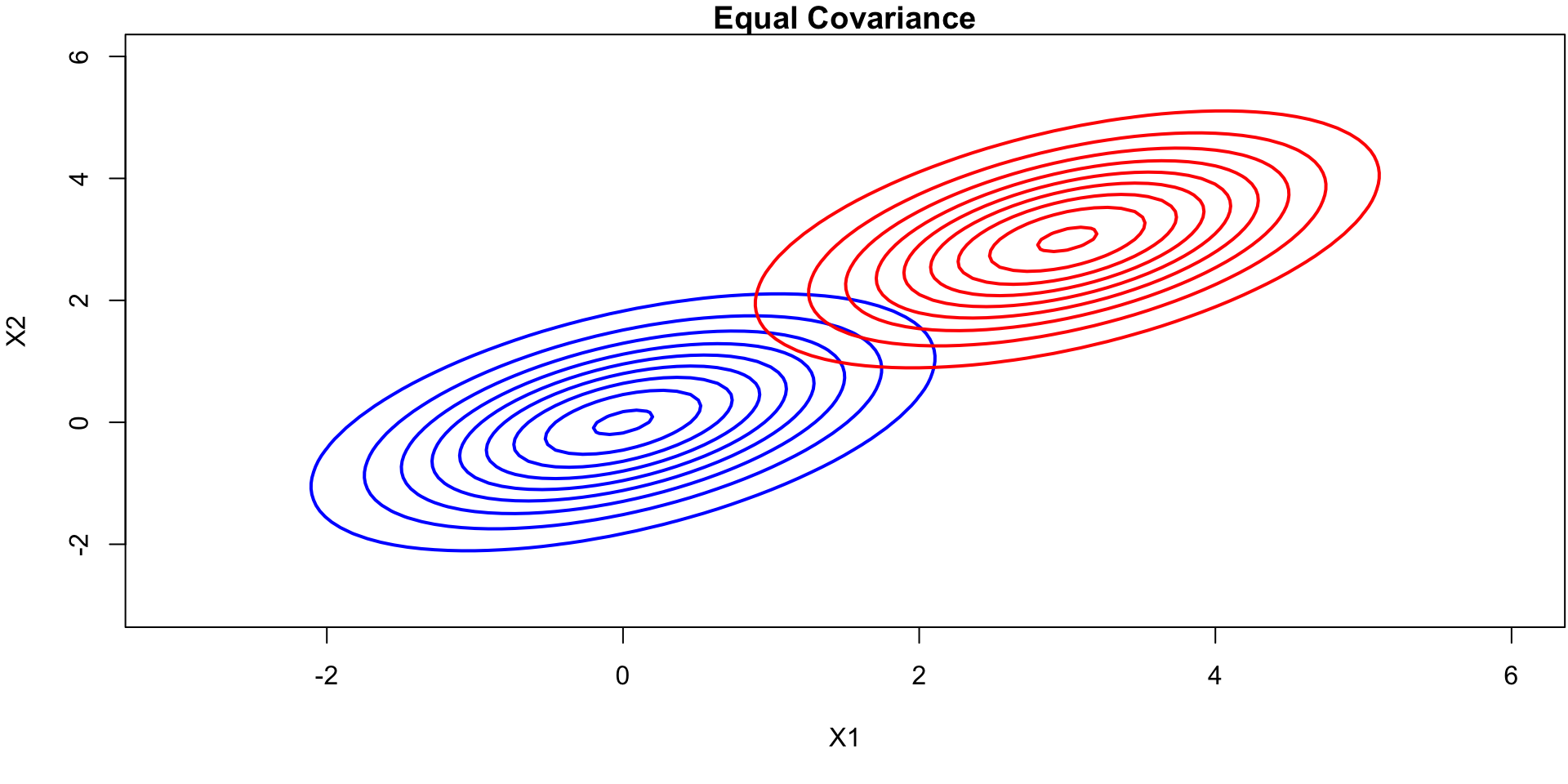
In the case of \(p > 1\) predictors, the LDA classifier assumes that the observations in the \(k\)th class are drawn from a multivariate Gaussian distribution \(\mathcal{N}(\boldsymbol\mu_k, \boldsymbol\Sigma)\), where \(\boldsymbol\mu_k\) is a class-specific mean vector, and \(\boldsymbol\Sigma\) is a covariance matrix that is common to all \(K\) classes.
Algebra reveals that the Bayes classifier assigns an observation \(X = x\) to the class for which \[\begin{equation}
\delta_k(x) = x^T \boldsymbol\Sigma^{-1} \boldsymbol\mu_k - \frac{1}{2} \boldsymbol\mu_k^T \boldsymbol\Sigma^{-1} \boldsymbol\mu_k + \log(\pi_k)
\end{equation}\]
par(mar=c(5,4,1.1,0.1))# Define the means and shared covariance matrix for the two classesmean1 <-c(0, 0)mean2 <-c(3, 3)cov_matrix <-matrix(c(1, 0.5, 0.5, 1), ncol=2) # Same covariance matrix for both classes# Create a grid of pointsx <-seq(-3, 6, length=100)y <-seq(-3, 6, length=100)grid <-expand.grid(X1 = x, X2 = y)# Calculate the multivariate normal densities for each classz1 <-apply(grid, 1, function(x) dmvnorm(x, mean=mean1, sigma=cov_matrix))z2 <-apply(grid, 1, function(x) dmvnorm(x, mean=mean2, sigma=cov_matrix))# Reshape for contour plottingz1_matrix <-matrix(z1, nrow=length(x), ncol=length(y))z2_matrix <-matrix(z2, nrow=length(x), ncol=length(y))# Plot the contour plots for the two classescontour(x, y, z1_matrix, drawlabels=FALSE, col="blue", lwd=2, main="Equal Covariance", xlab="X1", ylab="X2")contour(x, y, z2_matrix, drawlabels=FALSE, col="red", lwd=2, add=TRUE)
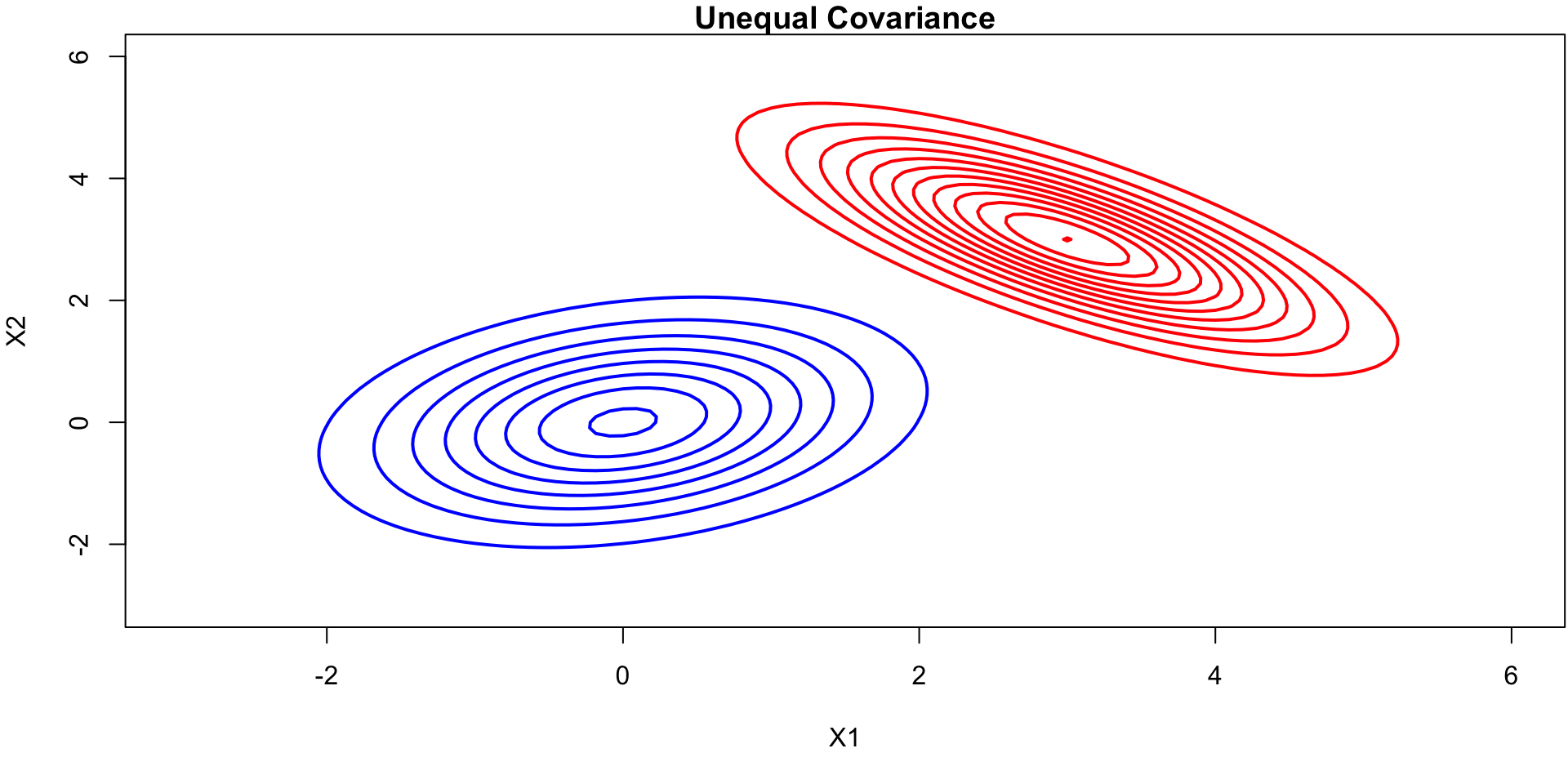
Contour Plots (unequal covariance)
Code
# Load necessary librarieslibrary(mvtnorm)par(mar=c(5,4,1.1,0.1))# Define the means and covariance matrices for the two classesmean1 <-c(0, 0)cov1 <-matrix(c(1, 0.25, 0.25, 1), ncol=2)mean2 <-c(3, 3)cov2 <-matrix(c(1, -0.75, -0.75, 1), ncol=2)# Create a grid of pointsx <-seq(-3, 6, length=100)y <-seq(-3, 6, length=100)grid <-expand.grid(X1 = x, X2 = y)# Calculate the multivariate normal densities for each classz1 <-apply(grid, 1, function(x) dmvnorm(x, mean=mean1, sigma=cov1))z2 <-apply(grid, 1, function(x) dmvnorm(x, mean=mean2, sigma=cov2))# Reshape for contour plottingz1_matrix <-matrix(z1, nrow=length(x), ncol=length(y))z2_matrix <-matrix(z2, nrow=length(x), ncol=length(y))# Plot the contour plots for the two classescontour(x, y, z1_matrix, drawlabels=FALSE, col="blue", lwd=2, main="Unequal Covariance", xlab="X1", ylab="X2")contour(x, y, z2_matrix, drawlabels=FALSE, col="red", lwd=2, add=TRUE)
LDA QDA in 2D
Code
## | cache: true# Load necessary librarieslibrary(MASS)par(mar=c(5,4,1.1,0.1))# Define the means and shared covariance matrix for the two classesmean1 <-c(0, 0)mean2 <-c(3, 3)cov_matrix <-matrix(c(1, 0.5, 0.5, 1), ncol=2) # Same covariance matrix for both classes# Create a grid of pointsx <-seq(-3, 6, length=100)y <-seq(-3, 6, length=100)grid <-expand.grid(X1 = x, X2 = y)# Calculate the multivariate normal densities for each classz1 <-apply(grid, 1, function(x) dmvnorm(x, mean=mean1, sigma=cov_matrix))z2 <-apply(grid, 1, function(x) dmvnorm(x, mean=mean2, sigma=cov_matrix))# Reshape for contour plottingz1_matrix <-matrix(z1, nrow=length(x), ncol=length(y))z2_matrix <-matrix(z2, nrow=length(x), ncol=length(y))# Plot the contour plots for the two classescontour(x, y, z1_matrix, drawlabels=FALSE, col="blue", lwd=2, main="LDA Decision Boundary", xlab="X1", ylab="X2")contour(x, y, z2_matrix, drawlabels=FALSE, col="red", lwd=2, add=TRUE)# Plot the LDA decision boundary (it will be linear)contour(x, y, z1_matrix - z2_matrix, levels=0, drawlabels=FALSE, col="green", lwd=2, lty=2, add=TRUE)# Add a title and labelstitle(main="LDA Decision Boundary")
Code
##| cache: true# Load necessary librarieslibrary(mvtnorm)par(mar=c(5,4,1.1,0.1))# Define the means and covariance matrices for the two classesmean1 <-c(0, 0)cov1 <-matrix(c(1, 0.5, 0.5, 1), ncol=2)mean2 <-c(3, 3)cov2 <-matrix(c(1, -0.5, -0.5, 1), ncol=2)# Create a grid of pointsx <-seq(-3, 6, length=100)y <-seq(-3, 6, length=100)grid <-expand.grid(X1 = x, X2 = y)# Calculate the multivariate normal densities for each classz1 <-apply(grid, 1, function(x) dmvnorm(x, mean=mean1, sigma=cov1))z2 <-apply(grid, 1, function(x) dmvnorm(x, mean=mean2, sigma=cov2))# Reshape for contour plottingz1_matrix <-matrix(z1, nrow=length(x), ncol=length(y))z2_matrix <-matrix(z2, nrow=length(x), ncol=length(y))# Plot the contour plots for the two classescontour(x, y, z1_matrix, drawlabels=FALSE, col="blue", lwd=2, main="QDA Decision Boundary", xlab="X1", ylab="X2")contour(x, y, z2_matrix, drawlabels=FALSE, col="red", lwd=2, add=TRUE)# Plot the QDA decision boundary where the two densities are equalcontour(x, y, z1_matrix - z2_matrix, levels=0, drawlabels=FALSE, col="green", lwd=2, lty=2, add=TRUE)
Illustration \(p = 2\) and \(K=3\)
ILSR Fig 4.6: Here \(\pi_1 = \pi_2 = \pi_3\)Left: Ellipses that contain 95 % of the probability for each of the three classes are shown. The dashed lines are the Bayes decision boundaries. Right: 20 observations were generated from each class, and the corresponding LDA decision boundaries are indicated using solid black lines. The Bayes decision boundaries are shown as dashed lines.
LDA to QDA
When \(f_k(x)\) are Gaussian densities, with the same covariance matrix \(\boldsymbol\Sigma\) in each class, this leads to linear discriminant analysis.
With Gaussians but different \(\boldsymbol \Sigma_k\) in each class, we get quadratic discriminant analysis.
Because the \(\boldsymbol\Sigma_k\) are different, we don’t loose the quadratic terms so we get discriminant function is now