Data 311: Machine Learning
Lecture 6: Logistic Regression
University of British Columbia Okanagan
Introduction
Lately we’ve been focused on the regression problem–that is, the supervised machine learning problem when our response variable is a continuous quantity.
Machine learning algorithms that aim at predicting a categorical (AKA qualitative) response are referred to as classification techniques.
In this section, rather than trying to predict a continuous responses, we will be trying to classify observations in to categories (AKA classes)
These the posts are the only ones that made sense to me:

Outline
Text Definition
Logistic Regression is a supervised statistical method used for binary1 classification problems.
- Examples: Spam detection, medical diagnosis, …
Note that the name is a bit of a misnomer; this is not a method for regression (predicting a continuous \(y\)), this is a classification technique (predicting categorical \(y\))
Mathematical Definition
As we will see, logistic regression outputs a probability like:
\[ p(Y=1 \mid X) = \frac{e^{\beta_0 + \beta_1 X_1 \dots + \beta_p X_p}}{1 + e^{\beta_0 + \beta_1 X_1 + \dots + \beta_p X_p}} \]
Under the hood we are modelling: \[ \text{log odds} = \beta_0 + \beta_1 X_1 \dots + \beta_p X_p \]
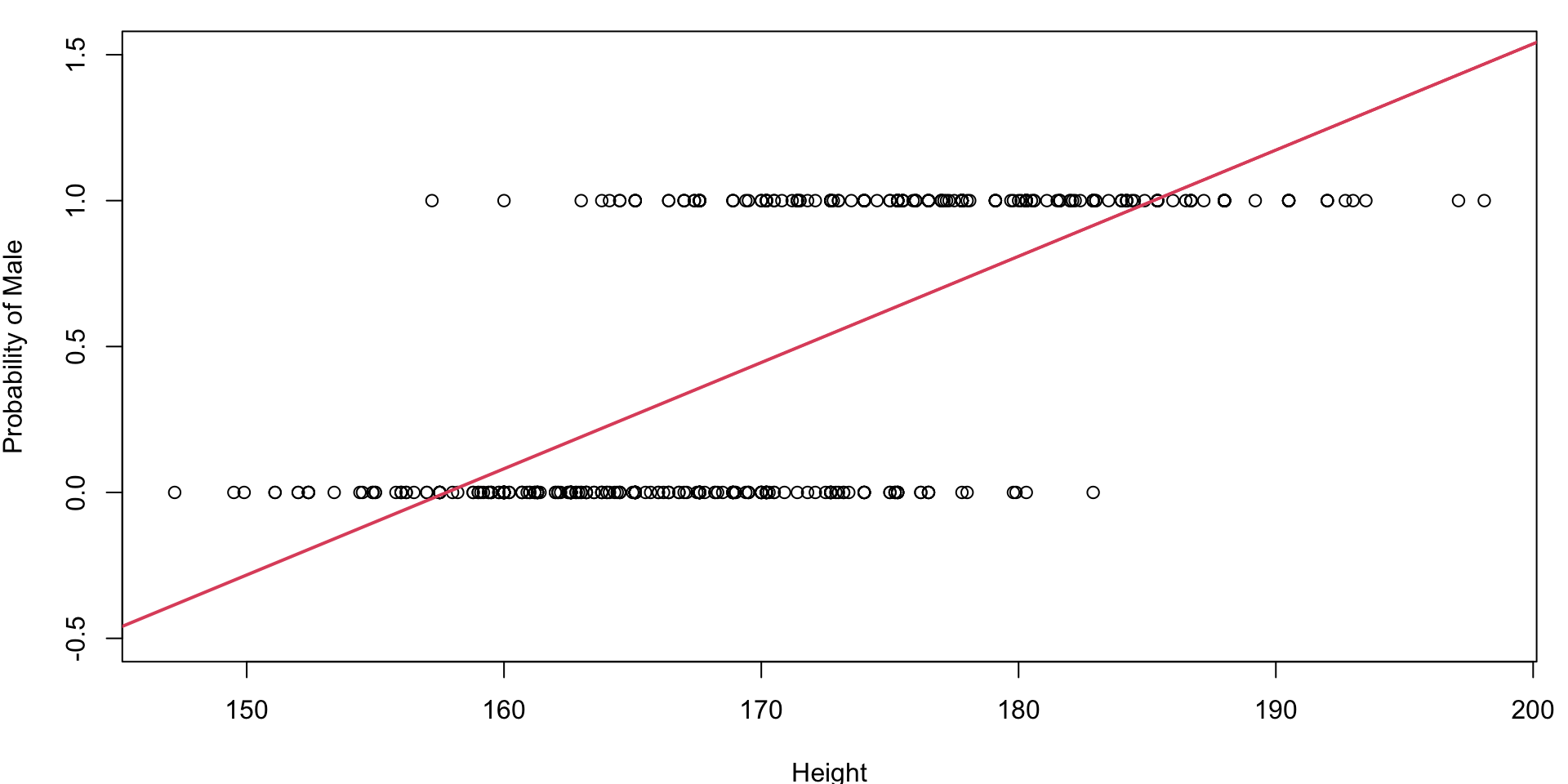
Why not Linear Regression?
Consider coding categories as numeric, say we had recorded eye colour:
\[ Y = \begin{cases} 1 & \text{Green}\\ 2 & \text{Blue} \\ 3 & \text{Brown} \end{cases} \]
Suppose we fed this into a linear model.
Question: What would a prediction of 1.5 signify?
Class levels
Numeric codings for a response fed into a continuous model assumes a natural order, or hierarchy.
For multi-class categorical data, this is simply inappropriate.
- But what about a binary classification problem?
\[ Y = \begin{cases} 1 & \text{Green}\\ 0 & \text{Not green} \\ \end{cases} \]
Can we use this in a linear model such that a predicted value of 0.5 suggests a 50-50 chance that a person’s eye colour is green?
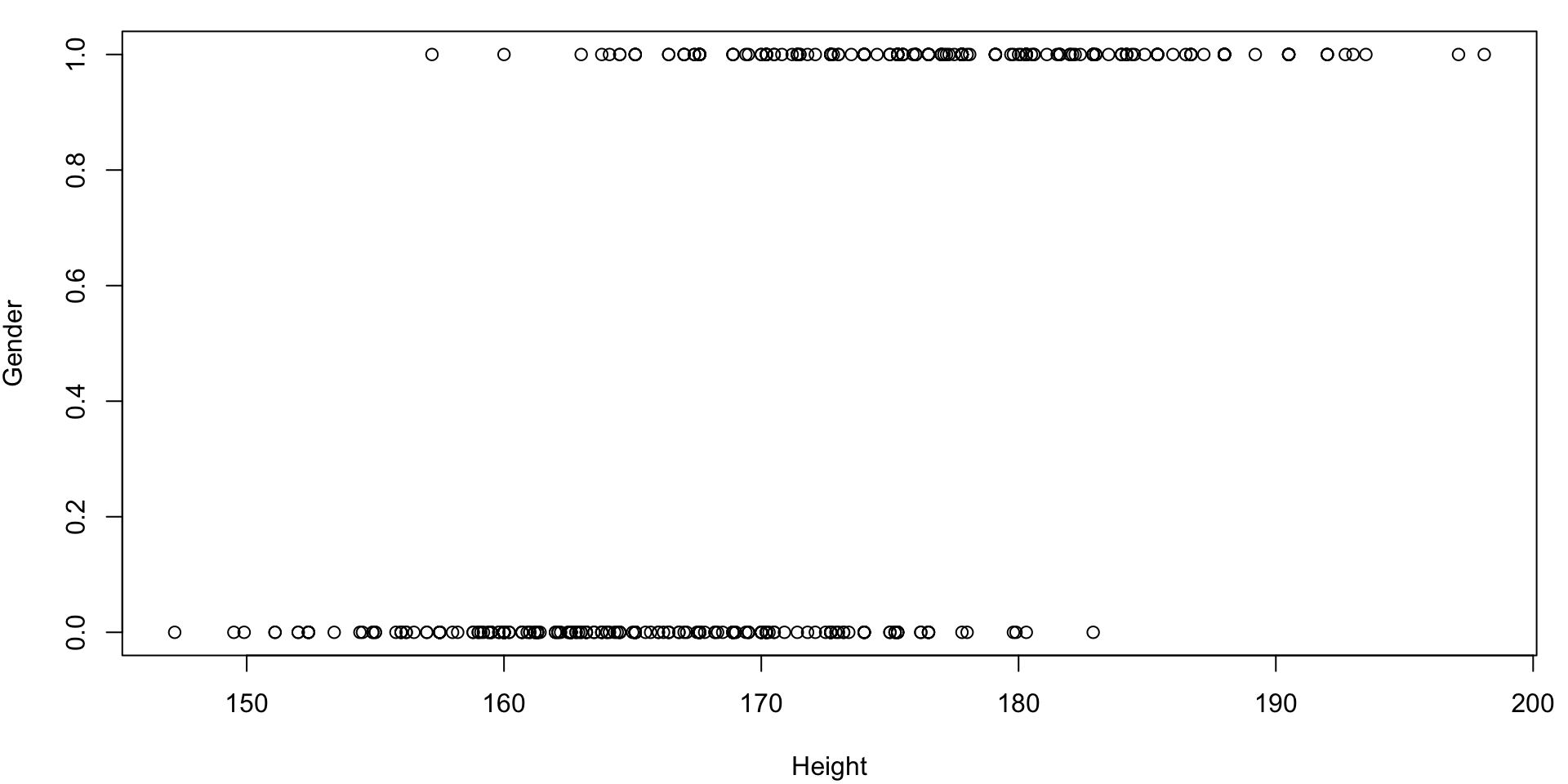
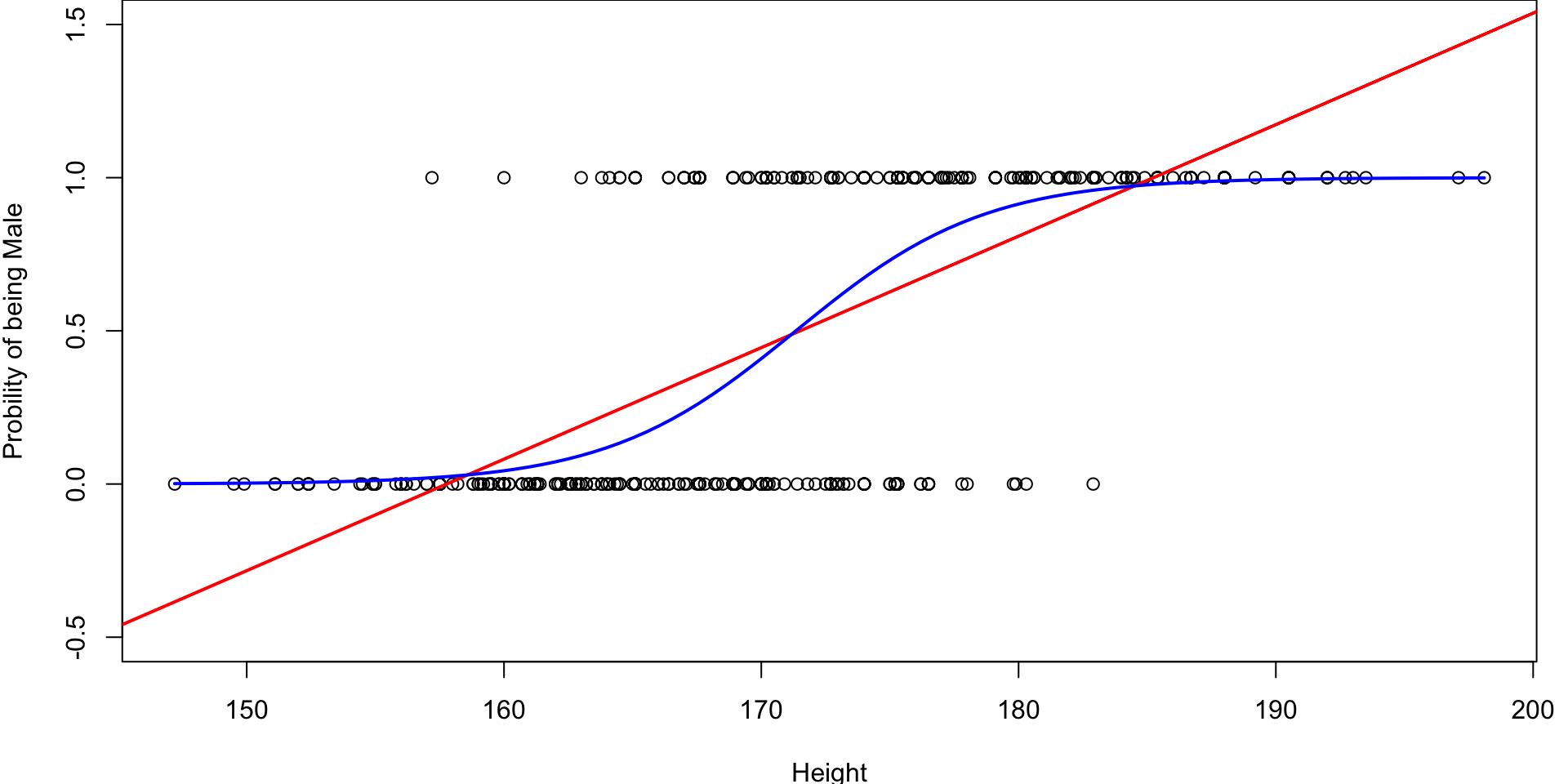
Example: body
Consider the
body(from the gclus package) data set from previous lecturesLet’s attempt to model the recorded
Genderas a linear function ofHeight.
Example: body
Multiple Linear Regression
Recall the linear regression model: \[\begin{equation} Y = \beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p + \epsilon \end{equation}\]
- \(Y\) is the random, quantitative response variable
- \(X_j\) is the \(j^{th}\) random predictor variable
- \(\beta_0\) is the intercept
- \(\beta_j\) from \(j = 1, \dots p\) are the regression coefficients
- \(\epsilon\) is the error term
Fitted line
Same Plot (zoomed out)
Generalized Linear Model
Rather than modeling continuous \(Y \in (-\infty, \infty)\) using: \[\begin{equation} Y = \underbrace{\beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p}_{\eta} \end{equation}\]
A GLM consists of three components:
- Systematic component: a linear combination of the predictors (\(\eta\))
- Random component: the probability distribution of \(Y\)
- Link function: Connects \(E[Y]\) to \(\eta\).
Systematic Component
The systematic component represents the linear combination of the independent variables.
It is typically expressed as \[\begin{equation} \eta = \beta_0 + \beta_1 X_1 + \dots \beta_p X_p \end{equation}\] where
\(\eta\) is the linear predictor,
\(\beta_0, \beta_1, \dots \beta_p\) are the coefficients. , and
\(X_1, X_2, \dots, X_p\) are the predictors.
Random Component
We assume that \(y_1, \dots, y_n\) are samples of independent random variables \(Y_1, \dots, Y_n\) respectively.
The random component specifies the probability distribution \(f(y_i; \theta_i)\) of the response variable.
For GLM’s the probability distributions are assumed to arise from the Exponential family.
Logistic regression is a type of GLM where the response variable is binary.
Exponential family
- The exponential family includes a large class of probability distributions e.g. normal, binomial, Poisson and gamma distributions, among others.
Classical regression assumes:
- \(Y_i \sim \text{Normal}(\mu_i, \sigma^2)\)
- \(E[Y_i] = \mu_i\)
Logistic regression assumes
- \(Y_i \sim \text{Bernoulli}(\pi_i)\)
- \(E[Y_i] = \pi_i\)
Link and Inverse Link Function
The mean of the distribution, \(\mu = {E}[Y_i]\) depends on the independent variables, \(X\), through the link function
\[\begin{align*} \eta &= g(\mu) \end{align*}\]
\[\begin{align*} g^{-1}(\eta) &= \mu \end{align*}\]
The inverse link function (aka activation function), \(g^{−1}\), transforms the linear predictor \(\eta = \beta_0 + \beta_1 X_1 + \dots \beta_p X_p\) back to the scale of the response variable.
Link function
The link function is a transformation that relates the mean of the response variable to the linear predictor.
\[\begin{equation} \eta = g(\mu) \end{equation}\]
where \(\mu = {E}[Y_i]\)
Link function Linear Regression
The link function is a transformation that relates the mean of the response variable to the linear predictor.
\[\begin{equation} \eta = g(\mu) \end{equation}\]
In classical linear regression, we use the identity link:
\[\begin{align} \eta &= 1(\mu) \\ \beta_0 + \beta_1 X_1 + \dots \beta_p X_p&= \mu \phantom{\beta_0 + \beta_1 x_1 } \end{align}\]
where \(\mu = E[Y_i]\) where \(Y_i \sim N(\mu_i, \sigma^2)\)
Logit Link
In logistic regression, we use the logit link, i.e.
\[\begin{align} \eta = g(\mu) = \text{logit}(\mu) &= \ln \left( \frac{\mu}{1-\mu} \right) \\ \beta_0 + \beta_1 X_1 + \dots \beta_p X_p &= \ln \left( \frac{\pi_i}{1-\pi_i} \right)\\ \end{align}\]
where \(\mu = E[Y_i] = \pi_i = P(Y_i = 1)\) when \(Y_i \sim \text{Bernoulli}(\pi_i)\)
Logit Function
More generally if \(p\) is a probability, then
Plotted log-odds
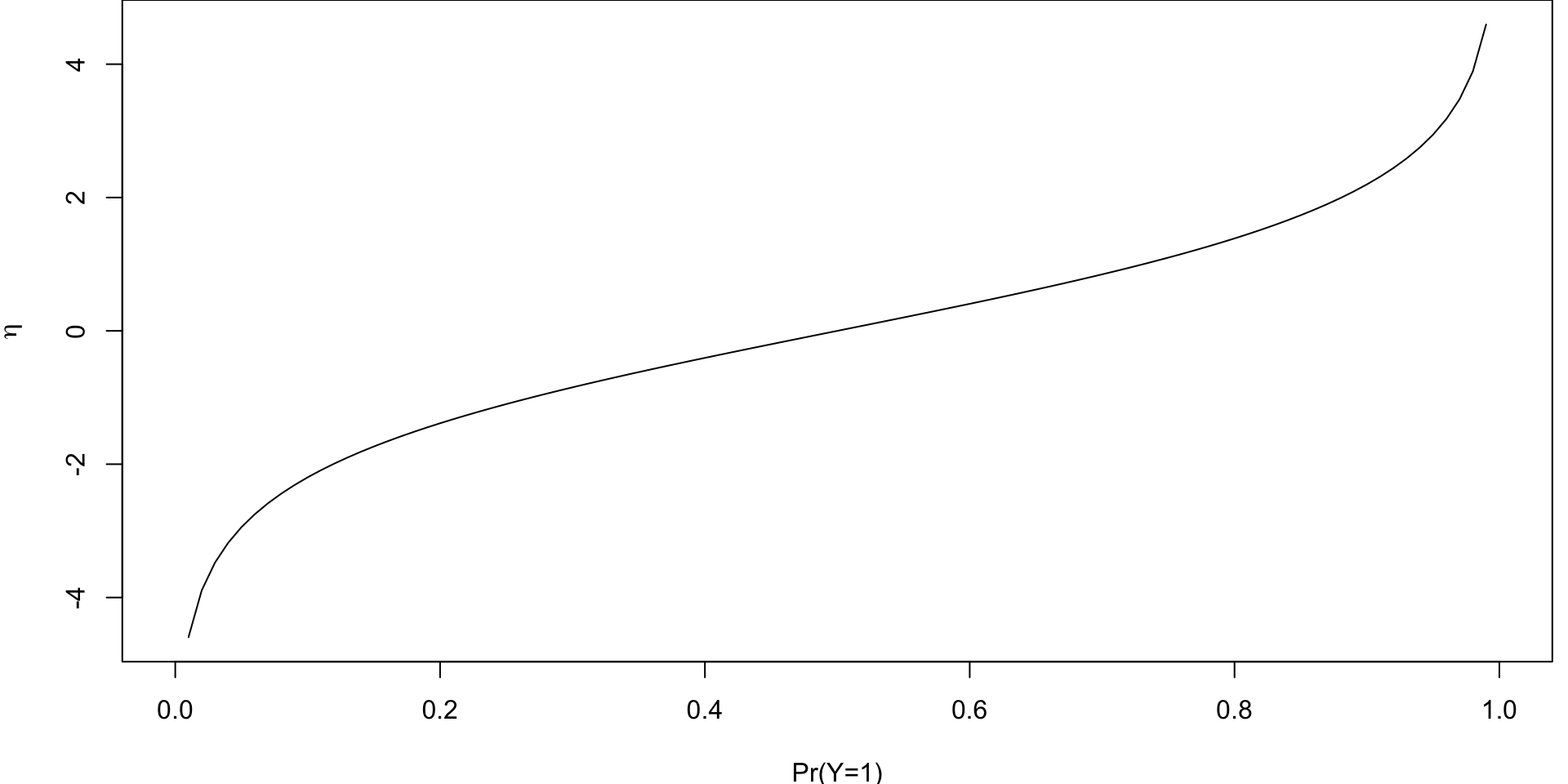
If \(p = 0.5 \implies\) the odds \(\left(\frac{p}{1-p}\right)\) are even and the log-odds is zero.
Negative (resp. positive) logits represent probabilities below (resp. above) one half.
Logistic Function
\[\begin{align} \text{logit } (\pi_i) &= \eta\\ \pi_i &= \text{logit}^{-1}(\eta) \end{align}\]
\[\begin{align} \text{Recall: } g(\mu) &= \eta\\ \mu &= g^{-1}(\eta) \end{align}\]
The inverse of the logit function, i.e. the activation/inverse link function \(g^{-1}\), is the standard logisitic function1
\[\begin{align} \pi_i = \text{Sigmoid}(\eta) &= \dfrac{1}{1 + e^{-\eta}} = \dfrac{1}{1+ e^{-(\beta_0 + \beta_1 X_1 + \cdots \beta_p X_p)}} \end{align}\]
\[\begin{align} P(Y_i = 1 \mid X) &= \dfrac{e^{(\beta_0 + \beta_1 X_1 + \cdots \beta_p X_p)}}{e^{(\beta_0 + \beta_1 X_1 + \cdots \beta_p X_p)}+ 1} \end{align}\]
Plotted Logistic Function
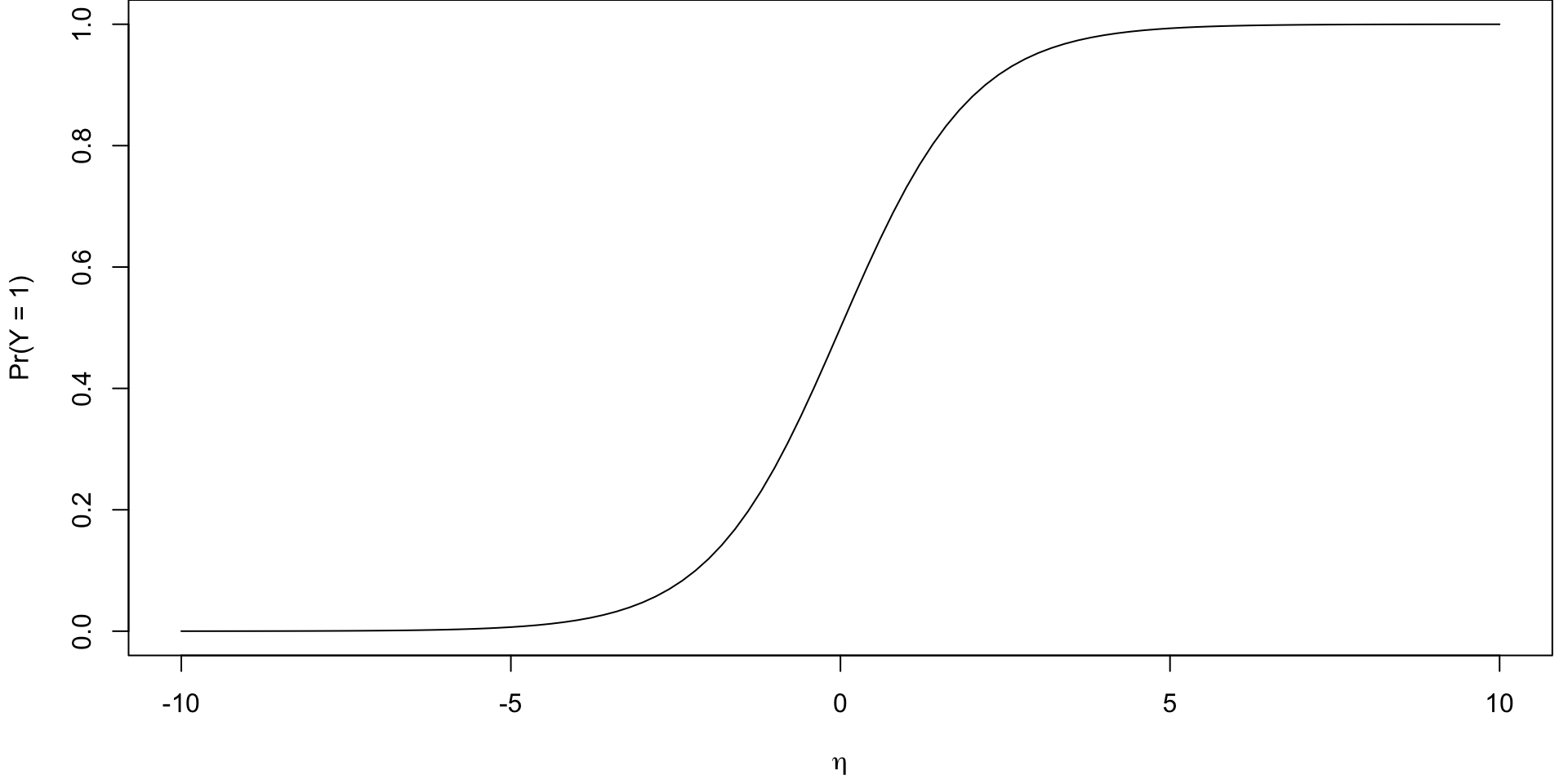
It is a S-shaped curve (sigmoid curve) that allows us to go back from logits to probabilities.
From Line to S-curve
Instead of trying to fit a line to this data, let’s try to fit something more like this S-curve so that \(0 \leq \pi_i \leq 1\)
Logistic Regression
Link Function \[ \begin{align} g(\mu) &= \eta\\ \text{log odds} = \ln\left(\frac{\mu}{1-\mu}\right) &= \beta_0 + \beta_1 X_1 + \dots + \beta_p X_p \end{align} \]
Inverse Link Function
\[ \begin{align} g^{-1}( \eta) &= \dfrac{e^{\sum_{j=1}^p\beta_j X_j}}{1+ e^{\sum_{i=1}^p\beta_i X_i}} = \dfrac{1}{1+e^{-\sum_{j=1}^p\beta_j X_j}} = \Pr(Y = 1)\\ \end{align} \]
Assumptions of Logistic Regression
- Binary dependent variable: The response variable \(Y\) must be binary (i.e., it takes on only two possible outcomes, such as 0 and 1, yes or no, success or failure).
- Independence of observations1
- Linearity of the Logit: There should be a linear relationship between the logit of the outcome (log-odds) and each continuous predictor variable.
- No multicollinearity.
iClicker
logit function
In the context of logistic regression, what does the logit function represent?
- The probability of success in a binary outcome.
- The natural logarithm of the odds of success.
- The inverse of the probability of failure.
- The square root of the expected value of the response variable.
Correct answer: B
iClicker
logit function
In a logistic regression model, what is the range of values that \(Y\) can take?
- Any real number
- Any integer
- 0 or 1
- 0 to infinity
Correct answer: C
Interpretation of Coefficients
Since probability \(\pi_i\) is non-linear as \(X\) varies1, we cannot interpret the coefficients as we did in regular regression.
The best we can do is talk about the direction:
Holding all other variables constant, if \(\beta_j\) is positive, then an increase in \(X_j\) is associated with an increase in \(\pi_i\)
Holding all other variables constant, if \(\beta_j\) is negative, then an increase in \(X_j\) is associated with a decrease in \(\pi_i\).
Estimation
Let \(G_1\) be the set of observations where \(Y=1\), let \(G_0\) be the set of observations where \(Y=0\), and let \(\boldsymbol{\beta}\) be the set of coefficients. The likelihood is given by:
\[ l(\boldsymbol{\beta}) = \prod_{i \in G_1 }P(y_i=1\mid x_i)^{y_i}\prod_{h \in G_0 }(1-P(y_i=1\mid x_h))^{1-y_i} \]
To fit the parameters of these models, we use maximum likelihood 1 estimation.
From lm() to glm()
You can fit a logistic regression using the glm() function.
| Arguments | Description |
|---|---|
formula |
a symbolic description of the model to be fitted, eg Y~ X1 + X2
|
family |
a description of the error distribution and link function to be used in the model ?family
|
data |
data frame (usually your training set) |
glm families
To perform logistic regression with a binary outcome we need to set
family = "binomial"1.-
Other options (not be covered in this course) include:
family = "gaussian"same aslm()family = "poisson"for predicting countsfamily = multinomialfor \(>2\) classesfamily = binomial('probit')probit regression (a common alternative to logistic regression)
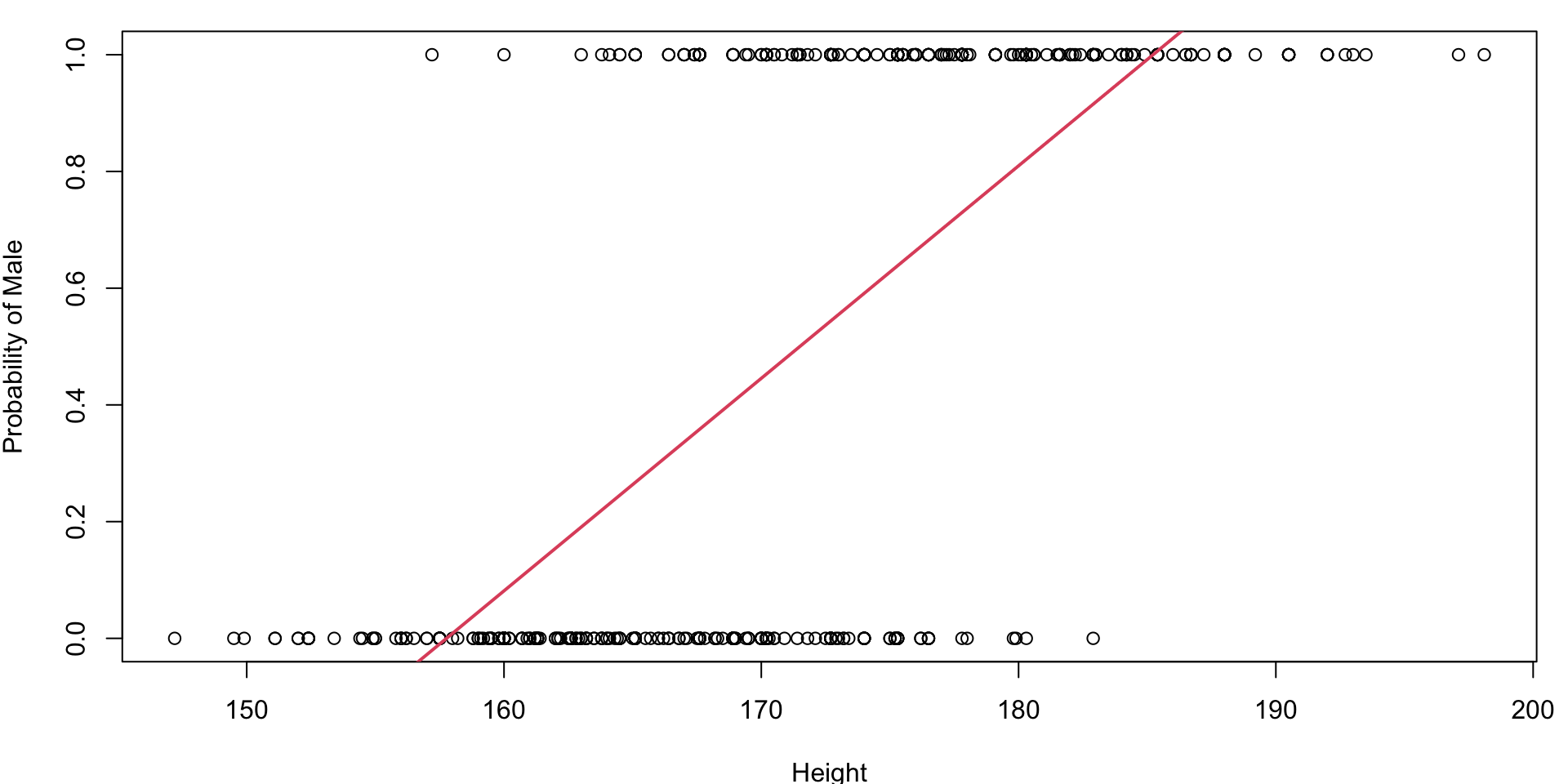
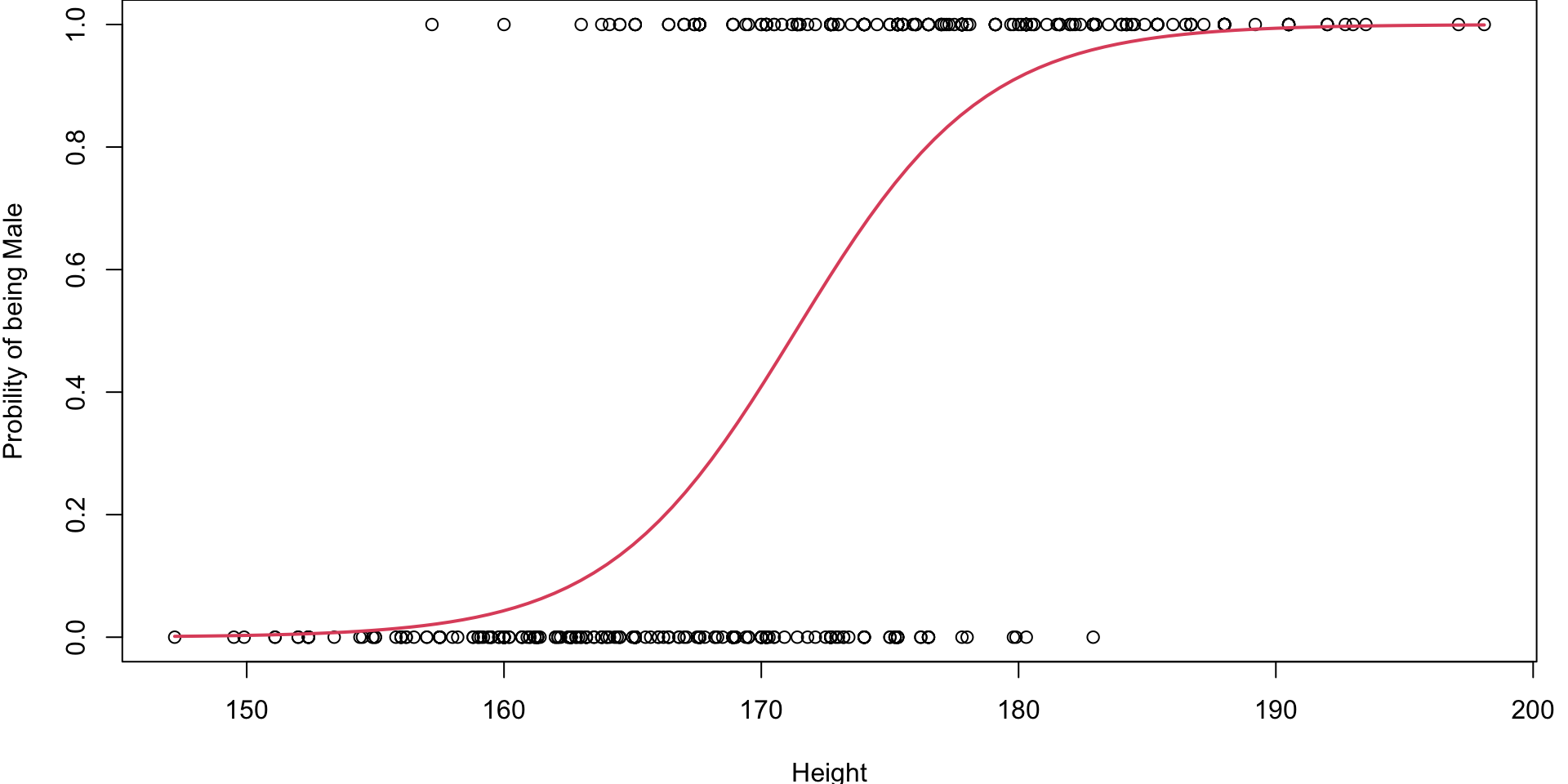
Fitted Logistics Regression Plot
We are using the Logistic Function with the fitted \(\hat \beta\) values to plot the fitted S-curve
# Fit the logistic regression model
simlog <- glm(factor(Gender) ~ Height , family="binomial")
# store the beta hats for easy referencing
betas <- coef(simlog)
# plot the data (renaming the y-axis)
plot(Gender~Height, ylab="Probility of being Male")
# plot the fitted curve p(x) = e^(b0+b2x)/(1 + e^(b0+b2x))
curve(
(exp(betas[1] + betas[2]*x))/(1+exp(betas[1] + betas[2]*x)),
add=TRUE, # superimposes onto scatterplot (otherwise new plot)
lwd=2, # line width (make the line a bit thicker)
col=2) # 2 = red Fitted Logistics Regression Plot
Summary Output
...
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -46.76328 4.00571 -11.67 <2e-16 ***
Height 0.27292 0.02339 11.67 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 702.52 on 506 degrees of freedom
Residual deviance: 389.59 on 505 degrees of freedom
AIC: 393.59
Number of Fisher Scoring iterations: 5
...iClicker
Interpretation of coefficients
In a logistic regression model, the coefficient \(\beta_1\) associated with a predictor variable \(X_1\) is interpreted as:
- The change in the predicted probability of the outcome for a one-unit increase in \(X_1\), holding all other variables constant.
- The change in the odds of the outcome for a one-unit increase in \(X_1\), holding all other variables constant.
- The change in the log-odds of the outcome for a one-unit increase in \(X_1\), holding all other variables constant.
- The change in the outcome value for a one-unit increase in \(X_1\), holding all other variables constant.
Correct answer: C
iClicker
Parameter estimation
Which method is used to estimate the coefficients (parameters) in a logistic regression model?
- Ordinary Least Squares (OLS)
- Maximum Likelihood Estimation (MLE)
- Method of Moments
- Bayesian Estimation
Correct answer: B
Multiple Logistic Regression
As with linear regression we could just as easily add predictors.
# Fit the logistic regression model
mult_log_reg <- glm(factor(Gender) ~ Height + WaistG + BicepG, family="binomial")
summary(mult_log_reg)...
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -55.32670 5.51960 -10.024 < 2e-16 ***
Height 0.21534 0.02864 7.520 5.50e-14 ***
WaistG 0.05167 0.02891 1.787 0.0739 .
BicepG 0.46541 0.08265 5.631 1.79e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 702.52 on 506 degrees of freedom
Residual deviance: 232.90 on 503 degrees of freedom
AIC: 240.9
Number of Fisher Scoring iterations: 6
...Model fit
- Deviance is a lack of fit measure (the smaller the better) that plays the role of RSS for a broader class of models.
- Null Deviance is the deviance of a model with no predictors (only an intercept). It serves as a baseline.
- The residual deviance measures the deviance that remains unexplained after fitting the logistic regression model.
- The Akaike Information Criterion (AIC) is a goodness of fit measure that penalizing for the number of parameters.
Metrics for Classification
We can evaluate the model by making predictions on new unseen data and assessing its performance; see Lecture 3
- error/misclassification rate
- accuracy
- precision
- recall
- specificity
- F1-score
These can all be computed from a so-called classification table (aka confusion matrix)
Validation of Predicted Values
With a fitted logistic regression model the predict() function (see ?predict.glm) we can either predict the categorical response or output a probability.

From Probability to Classification
-
Logistic Regression produces a probabilistic classifier1.
\[ \begin{cases} 1 & \text{ if } \Pr(Y=1 \mid x) \geq 0.5\\ 0 & \text{ otherwise} \end{cases} \]
Since we are considering only binary outpus, \(P(Y=1 \mid x)=0.5\) defines a decision boundary.
Where is this boundary for the body example in terms of \(X\)?
Plot of Probability Boundary
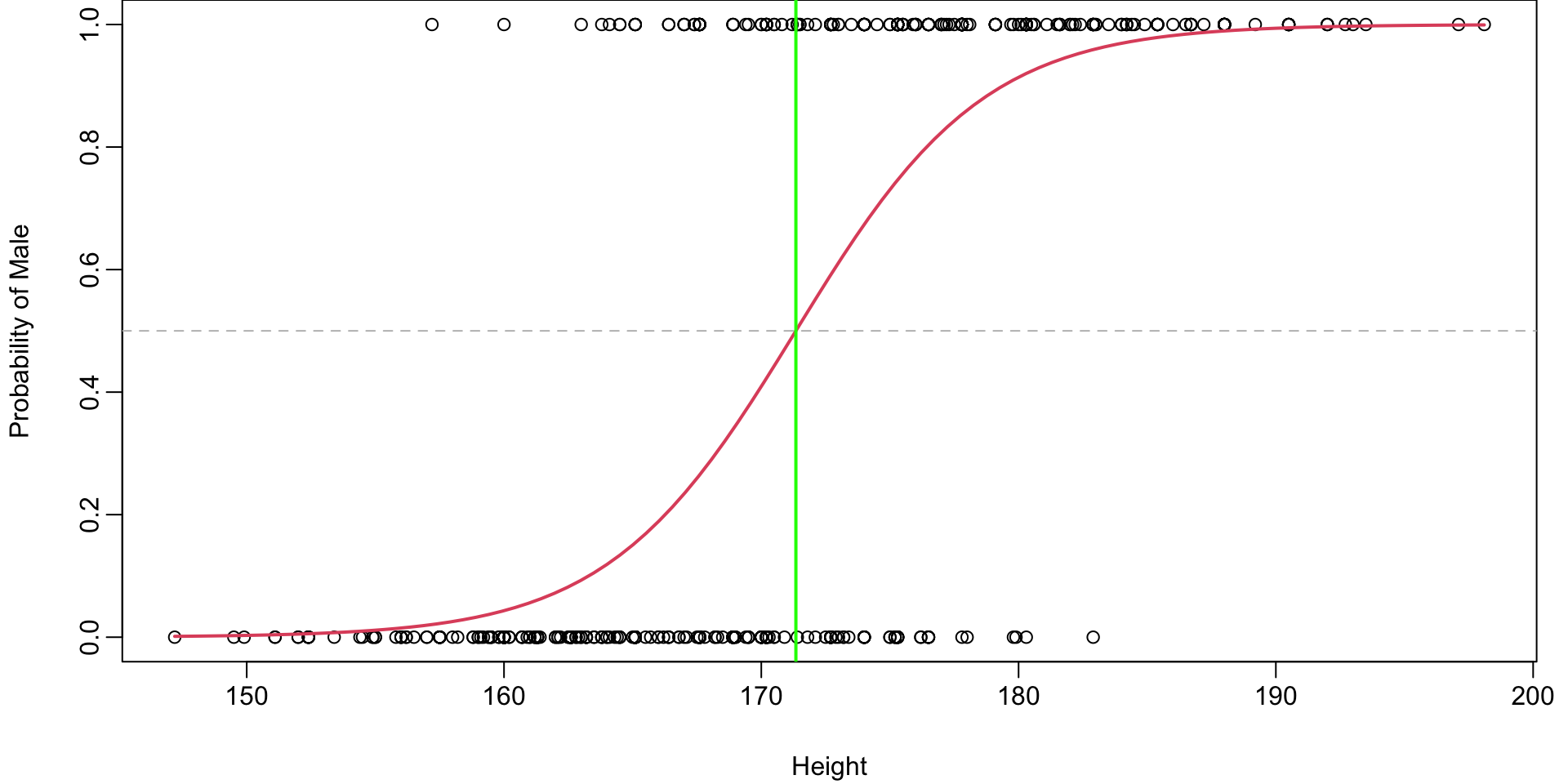
Height boundary
\[ \log \left(\frac{0.5}{0.5-0}\right) = {\hat\beta_0 + \hat\beta_1 X} \]
\[ \begin{align} \implies && \log \left(1\right) &= {\hat\beta_0 + \hat\beta_1 X} \\ \implies && X &= -\frac{\hat\beta_0}{\hat\beta_1} \end{align} \]
If Height \(> -\dfrac{ -46.76}{0.27} = 171.34\) we would predict Male.
Classification Table
For classification, we often summarize performance in a classification table (aka confusion matrix).
Note
Typically the off-diagonals are errors and diagonal are correctly classified observations
Classification Table
| predicted male | predicted female | |
|---|---|---|
| 1 - male | 216 | 44 |
| 0 - female | 45 | 202 |
Gender. It shows the counts of correctly and incorrectly classified instances for both males and females. The rows represent the actual gender, while the columns represent the predicted gender.
Confusion Matrix
| predicted male | predicted female | |
|---|---|---|
| 1 - male | 216 | 44 |
| 0 - female | 45 | 202 |
True Positives (TP): Correctly predicted males (216)
False Positives (FP): Females incorrectly predicted as males (45)
True Negatives (TN): Correctly predicted females (202)
False Negatives (FN): Males incorrectly predicted as females (44)
Error Rate
In words, the error rate (aka misclassification rate) calculates the proportion of misclassifications that are made by \(\hat f\):
\[\begin{align} \frac{1}{n} \sum_{i=1}^n I(y_i \neq \hat y_i) = \frac{\text{total misclassified}}{\text{total no. observations}} \end{align}\]
and \(\hat y_i\) is the predicted class label for the \(i\)th observation \(x_i\) using \(\hat f\) and \[\begin{equation} I(y_i \neq \hat y_i)= \begin{cases} 1, y_i \neq \hat y_i\\ 0, \text{otherwise} \end{cases} \end{equation}\]
The error rate for this classification table is \[\begin{align} \dfrac{44+45}{216+44+45+202} = \dfrac{89}{507} = 0.1755424 \approx 17.6% \end{align}\]
Accuracy
\[ \text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} \]
\[\begin{align} &=\frac{TP + TN}{n} = \frac{216 + 202}{507} = \frac{418}{507} \\ &= \frac{\text{correct predictions}}{\text{total predictions}} = 0.8244576 \end{align}\]
Precision
\[\begin{align} \text{Precision} &= \frac{TP}{TP + FP}\\ &=\frac{216}{216 + 45} = \frac{216}{261} \\ &= 0.8275862 \end{align}\]
Recall
Recall (Sensitivity or True Positive Rate)
\[\begin{align} \text{Recall} &= \frac{TP}{TP + FN}\\ &=\frac{216}{216 + 44} = \frac{216}{260} \\ &= 0.8275862 \end{align}\]
Specificity (TN rate)
| Pred male | Pred female | |
|---|---|---|
| Actual male | 216 | 44 |
| Actual female | 45 | 202 |
\[\begin{align} \text{Specificity} &= \frac{TN}{TN + FP} \\ &= \frac{202}{202 + 45} = \frac{202}{247} = 0.8178138 \\ &= \frac{\text{true negatives}}{\text{actual negatives}} \end{align}\]
F1-score
\[ \begin{align} \text{F1} &= \dfrac{2 \times \text{Precision} \times \text{Recall}} {\text{Precision} + \text{Recall}}\\ &= \dfrac{2 \times 0.8275862 \times 0.8307692} {0.8275862+ 0.8307692}\\ &= 0.8291747 \end{align} \]
Note
F1-score is particularly useful when there is an uneven class distribution (i.e. “unbalanced” classes).
Summary of Metrics
Accuracy: 82.45%
Precision: 82.76%
Recall: 83.08%
Specificity: 81.78%
F1-Score: 82.92%
Accuracy measures overall correctness.
Precision measures the accuracy of the positive predictions.
Recall measures how well the model identifies true positives.
Specificity measures how well the model identifies true negatives.
F1-Score balances precision and recall
Which metric to use?
- Accuracy: When the dataset is balanced (i.e., both classes are equally represented)
- Precision: use when the cost of false positives is high, e.g. spam
- Recall: use when the cost of false negatives is high, e.g. disease screening
- Specificity: use when its important to correctly identify negative cases, e.g. fraud detection
- F1-score: When there is an imbalance1 between precision and recall, and you want a single metric that accounts for both. Useful in imbalanced datasets.
Testing vs Training error rate
Akin to our earlier discussions with MSE for regression, we are generally interested with the error rate from the testing set rather than the training set.
That is, for a set of new observations \((x_0, y_0)\), a good classifier achieves the smallest test error on average: \[\begin{equation} E[I(y_0 \neq \hat y_0))], \end{equation}\] where \(\hat y_0\) is the predicted class label for \(x_0\) that uses \(\hat f\).
Comments
Your guess is as good as mine…(no more residuals to check)
No problem, bit of a change in notation and mathematics, but R can handle it just fine.
family = "multinomial"✏️ Next class we’ll move on to another (more natural) model for classification (Bring some paper and a pen!)