So far we’ve assumed that our response variable was a quantitative value, i.e. the regression problem. In this lab we move to the classification setting wherein the response variable is categorical. While in lecture we usually referred to categories of \(y\) as groups, or classes, to keep consistent with R terminology we will also be referring to the categorical variable as a factor variable, and it’s classes/groups as levels.
Data
The body dataset contains 21 body dimension measurements as well as age, weight (in kg), height (in cm), and gender (binary) on 507 individuals. You can find this in the gclus library as body. As always, lets load our data set into our R session and make sure that it looks as we expect.1
As you will notice in the print out above, Gender is being treated as a numeric integer (as indicated by <int> under the column heading) rather than a factor. If ever you are unsure if you are unsure if your variable is being treated as an integer or a factor, you can check using class
class(Gender)
[1] "integer"
As in the linear regression setting where we had to use something like lm(y~ x1 + factor(x2)) to let R know that a predictor variable is a categorical, we need to convert the Gender to the factor class to ensure that these values are being treated as a categories (i.e. levels) rather than numbers. To accomplish this we could run:
body$Gender <-factor(body$Gender)
Alternatively if we want to convert the 1’s to male and 0 to female2 we could use something like:
Now we can see that Gender is being treated as a categorical variable (i.e. a factor variable in R).
class(Gender)
[1] "integer"
Ooops! What have we forgot to do here?
Code
## Answer: we neglected to reattach the data set!attach(body)
The following objects are masked from body (pos = 3):
AbdG, Age, AnkleD, AnkleG, Biacrom, BicepG, Biiliac, Bitro, CalfG,
ChestD, ChestDp, ChestG, ElbowD, ForearmG, Gender, Height, HipG,
KneeD, KneeG, ShoulderG, ThighG, WaistG, Weight, WristD, WristG
While the data frame has changed it’s respective Gender column to a factor variable class(body$Gender) returns factor the object called Gender needs to be updated. To reattach, simple rerun the attach function3
Don’t be alarmed by the warning that reattaching your data set produces. It simply tells us that it’s overwriting the variables that were attached in the first version of body. Now we can see that Gender is being treated as a factor:
class(Gender)
[1] "factor"
Training and Testing
Before fitting our model, let’s divide our data into training and testing. To make our results reproducible let’s also set a seed4.
Now lets suppose we want to use Gender as the response variable. In that case we move from a Regression problem (with numeric continuous response) to a Classification problem (with discrete categorical response). We talked about in lecture why a regualar linear model is not sufficient. A possible alternative is logistic regression which is modeled by: \[\log \left( \frac{P(Y=1 \mid X)}{1-P(Y=1 \mid X)} \right) = \beta_0 + \beta_1 X_1+ \cdots + \beta_p X_p\]
Logistic regression is a type of generalized linear models, hence we fit it using the glm function in R. In terms of inputs, it will feel very similar to using lm, i.e. its first input will be of the formula form Y~X. The family="binomial" indicates that R should fit logistic regression. Notice that since we already converted Gender to a factor we need not wrap the variable name in factor() in the lm function.
Call:
glm(formula = Gender ~ Height, family = "binomial", subset = train_ind)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 45.75626 5.13902 8.904 <2e-16 ***
Height -0.26691 0.02999 -8.899 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 421.10 on 303 degrees of freedom
Residual deviance: 240.86 on 302 degrees of freedom
AIC: 244.86
Number of Fisher Scoring iterations: 5
Notice that the subset argument above allows us to specify the index of training observations in our full data set (as opposed to feeding the data frame of training observations). In other words, simlog is the equivalent to:
# same assimlog2 <-glm(Gender ~ Height , family="binomial", data = body, subset = train_ind)simlog2
Call: glm(formula = Gender ~ Height, family = "binomial", data = body,
subset = train_ind)
Coefficients:
(Intercept) Height
45.7563 -0.2669
Degrees of Freedom: 303 Total (i.e. Null); 302 Residual
Null Deviance: 421.1
Residual Deviance: 240.9 AIC: 244.9
Something I unexpectedly discovered is that simlog and simlog2 is not the same as”
# not same assimlog3 <-glm(Gender ~ Height , family="binomial", data = train_data)simlog3
Call: glm(formula = Gender ~ Height, family = "binomial", data = train_data)
Coefficients:
(Intercept) Height
45.7563 -0.2669
Degrees of Freedom: 303 Total (i.e. Null); 302 Residual
Null Deviance: 421.1
Residual Deviance: 240.9 AIC: 244.9
Why is that?
Code
## Because of the ordering of observations? Come back to this!
Notice from the outputs that we no longer have things like \(r\)-squared values and \(F\) tests. We will be discussing other metrics in a section below.
Prediction
Like with lm, the output of glm provides the estimates of the parameters. The logistic regression coefficients give the change in the log odds of the given observation being female5 for every one unit increase in the predictor variable. For this model:
We could find this probability more readily using the predict() function. Please note that the predict function will NOT work until your data is stored in in a data frame having the column names as the variables used in training your logistic regression above; see ?predict.lm for details.
# WRONG ways to specify 'newdata'predict(simlog, newdata =174, type ="response") # will produce error# RIGHT way:predict(simlog, newdata =data.frame(Height =174), type ="response")
Since we will be reusing this data, let’s save it to an object:
newdata1 <-data.frame(Height =174)predict(simlog, newdata = newdata1, type ="response")
1
0.3347727
When we specify type = "response", the function returns the prediction as a probability = \(P(Y = 1 | X)\). By default, the predict function will return the lod-odds prediction:
# log odds are predicted by default(log.odds.x<-predict(simlog, newdata = newdata1))
1
-0.6866771
# to convert to odds(odds =exp(log.odds.x))
1
0.5032455
# to covert odds to probability ... (prob = odds/(1+ odds)) # same as above!
1
0.3347727
To convert the above probability into a classification, simply map observations to whichever class for which it has the highest probability of belonging. In our case \(\Pr(Y = \text{female} \mid X = 174) =\) 0.3347727 (which implies \(\Pr(Y = \text{male})) =\) 1 - 0.3347727 = 0.6652273), so the observation is predicted to be male. Since our response is binary (1 = female, 0 = male), any observations with resulting probabilities greater that 0.5 predicted as female.
For instance, lets see how this model would classify the objects in our test set:
# pred.gender <- predict(simlog, newdata = data.frame(body$Height), type = "response") > 0.5# predict gender for training set (same as above)pred.prob <-predict(simlog, newdata=test_data, type ="response") pred.gender <-factor(pred.prob>0.5, levels=c(FALSE, TRUE), labels=c("male", "female"))y = test_data$Gender# see the first 10:head(cbind(pred.gender, y))
Which factor level do the probabilities correspond to?
For the binomial families, the “\(1\)” in the \(\Pr(Y = 1 \mid X)\) corresponds to the second level of our factor. Notice the order of the levels in the following output:
levels(Gender)
[1] "male" "female"
In our case, since female is the second level, we will be predicting \(P(Y = \text{female} \mid X)\).
Sidenote: By default R will order levels alphabetically. Our levels are not in alphabetical order because we hard coded them in the Data section. You can read more here for a discussion on how do I know which factor level of my response is coded as 1 in logistic regression?
Classification Performance
As discussed in lecture and in previous labs, we can summarize and compare our predictions to the truth using a confusion matrix. It can be found quickly using the table() function:
tab <-table(test_data$Gender, pred.gender)tab
pred.gender
male female
male 82 18
female 16 87
with misclassification rate given by: \[\begin{equation}
\frac{\text{total misclassified}}{\text{total no. observations}}
=\frac{18+16}{203}
= 0.1674877
\end{equation}\]
Simulation setup
Let’s start off with a simulation that shows some insight beyond that discussed in lecture.
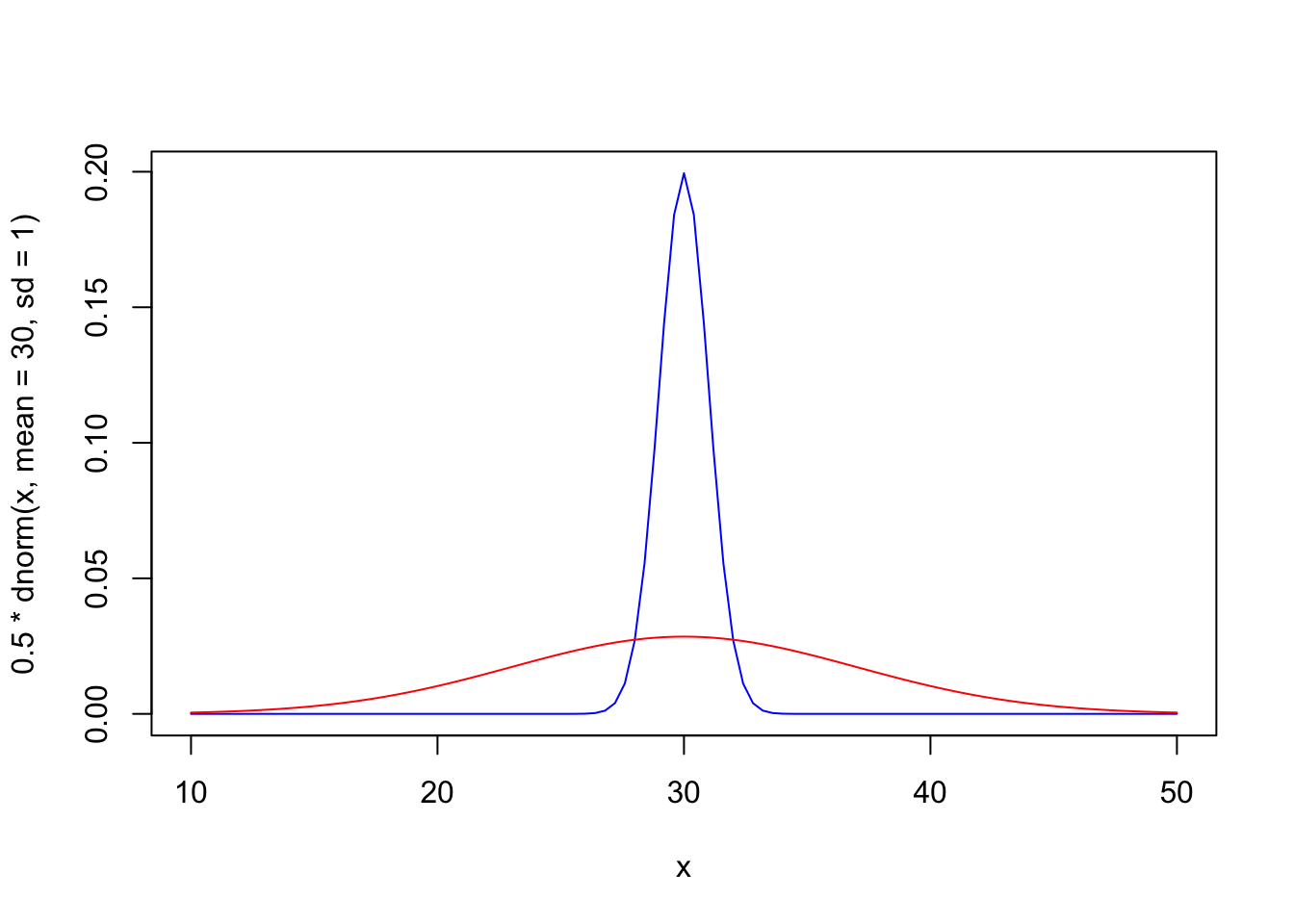
Suppose we have two groups, both normally distributed, with the same mean but different variance.
set.seed(3141)g1 <-rnorm(200, mean=30, sd=7)g2 <-rnorm(200, mean=30, sd=1)#combine into one data setsimdata <-c(g1, g2)#add group informationclas <-c(rep("G1", 200), rep("G2", 200))
This is a difficult classification problem, as the groups are essentially nested. Here’s the true generative distributions
Call:
glm(formula = factor(clas) ~ simdata, family = "binomial")
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.52661 0.64329 0.819 0.413
simdata -0.01749 0.02110 -0.829 0.407
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 554.52 on 399 degrees of freedom
Residual deviance: 553.83 on 398 degrees of freedom
AIC: 557.83
Number of Fisher Scoring iterations: 3
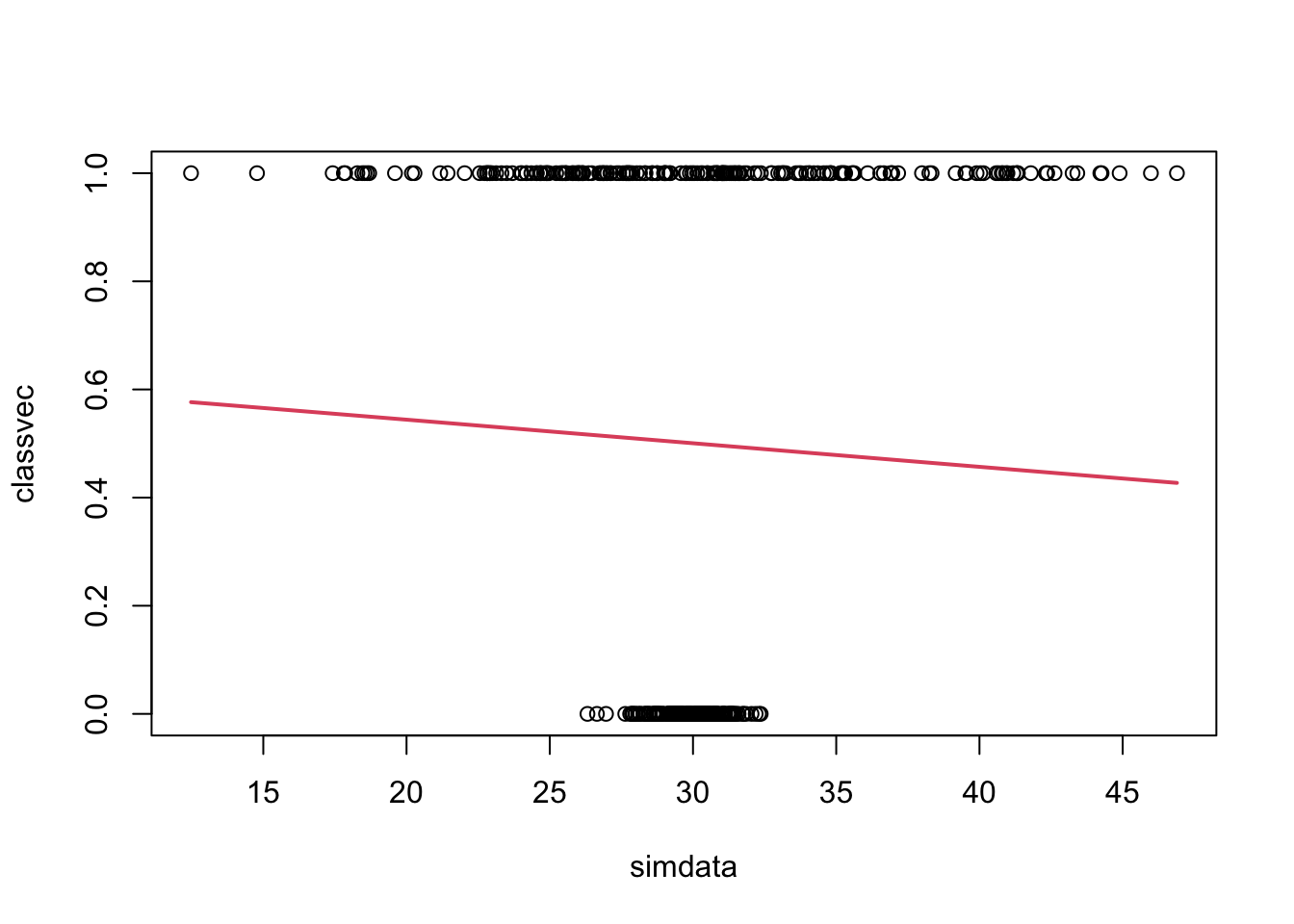
classvec <- clas =="G1"# 1 if group G1 0 o.wplot(classvec ~ simdata)betas <-coef(simlog);curve((exp(betas[1] + betas[2]*x))/(1+exp(betas[1] + betas[2]*x)), add=TRUE, lwd=2, col=2)
n =sum(lr.tab)misclass = n -sum(diag(lr.tab))err.rate = misclass/n
Terrible. A classification error rate of \(\frac{196}{400}\) = 0.49. If we think about how we’re classifying, this result makes sense. Logistic regression assumes a single boundary, which isn’t appropriate in this context. Quadratic discriminant analysis is the correct model…
Quadratic Discriminant Analysis
To fit Quadratic Discriminant Analysis (QDA) we use the qda function from the MASS library.
Much better. Misclassification rate of 62/400 = 0.155.
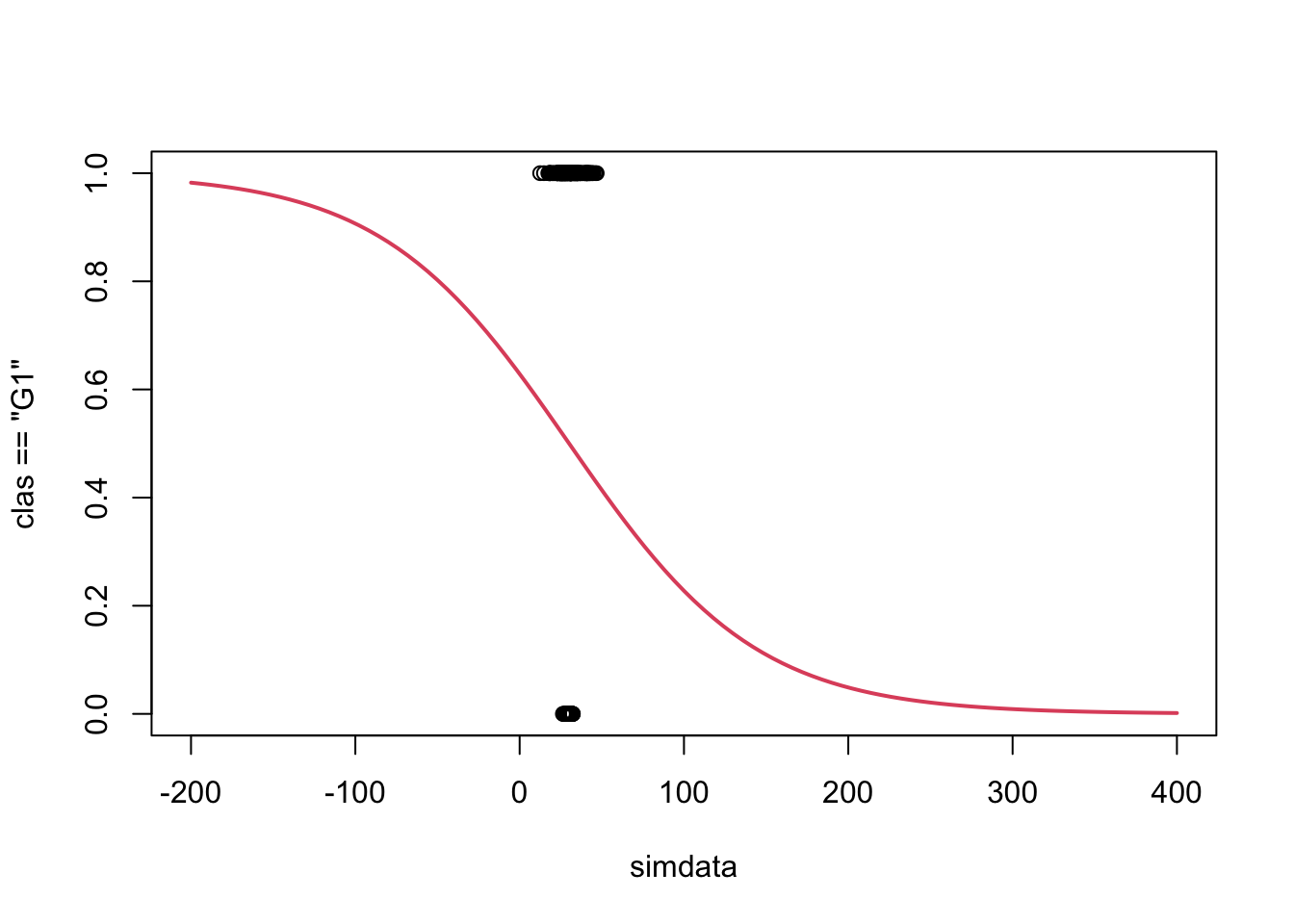
But what if one of the groups has fewer observed values? Let’s copy and paste some earlier commands and make adjustments. Make sample sizes of G1 380 and G2 20.
So we technically have a ‘misclassification rate’ of 20/400 = 0.05…but in reality, this ‘low’ rate is equivalent to saying “I guess group 1, no matter what the data says”! In fact, we are misclassifying 100% of the G2 (blue) group. Hence, why we have discussed performance metrics in more detail.
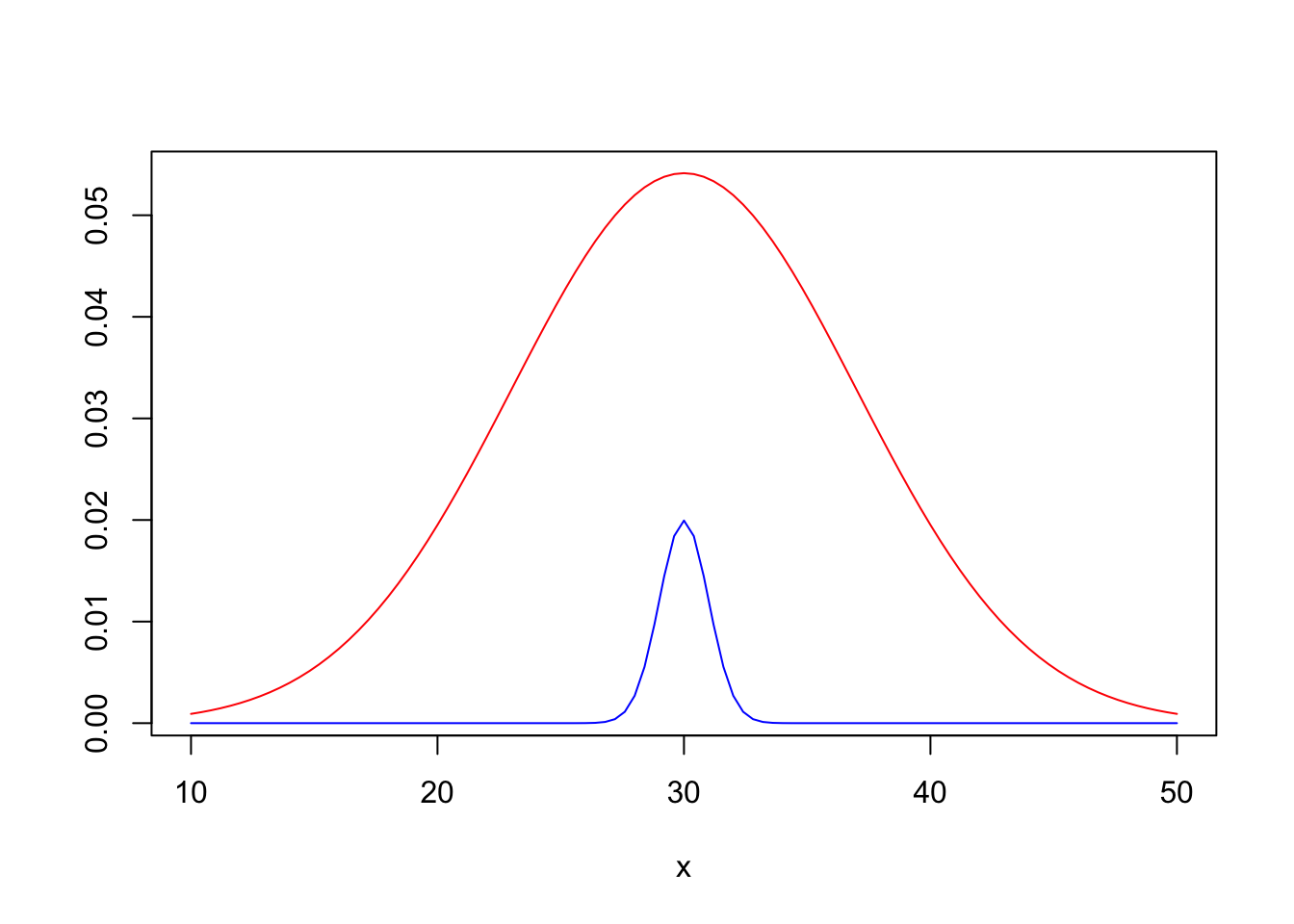
But why is this case so much harder? Consider the proportions associated with each group (those \(\pi_g\) discussed in lecture). In that case we have…
So no intersections! With the data we have, we will never be able to perform classification. That’s because the Bayes Classifier would even claim that everything is in the red group!
Comparing Classification Methods
Footnotes
For example, you can call View(...) or head(...) or srt(...) on your data set to accomplish this.↩︎
the information regarded this encoding can be found in the help file for the body data set which can be accessed using ?body↩︎
Ideally, you should do any adjustments to your data frame before you attach your data set.↩︎
In case you were wondering how a generate this seed, I used as.integer(Sys.time()). I like to do this to avoid using similar seeds over and over again, e.g. set.seed(<year>).↩︎
see this section for explanation of how we know which factor level is coded as 1↩︎