
Data 311: Machine Learning
Lecture 20 - Deep Learning
Dr. Irene Vrbik
University of British Columbia Okanagan
Background
Neural networks (NN) is a supervised machine learning algorithms that rose to fame in the late 1980s
Automatic methods like Support Vector Machines (SVM), boosting, and random forests caused NN, which required a lot of tinkering, to take a backseat.
Neural networks resurfaced after 2010 with the new name deep learning and by 2020 they are one of the most popular algorithms in machine learning.
The rising success of NN, in part, is due to the vast improvements in computer power, larger training sets, and software: Tensorflow and PyTorch
Preface
NN cover a broad range of concepts and techniques.
As with most of the subjects in this class, an entire course (grad school-level) could be given on this matter!
This lecture just skims the surface of this vast landscape
These methods are often used as a black box, but they are rooted in math and statistics.
The material in this unit is slightly more challenging than elsewhere in this book.
Neural Networks
- A neural network is a series of algorithms designed to recognize underlying relationships in a set of data through a process that mimics the way the human brain operates.
- These can be applied to variety of
predictorsinputs (e.g. video, images, speech, sounds, text, time series, etc.)
- NN require labeled training data to learn patterns and make predictions (the more diverse and representative, the better).
Structure of a NN
NN are often visualized as a Network Diagram with connections and nodes
These connections (denoted by arrows on the diagram) are each associated with a parameter (aka weight)
In a feedforward network, information always moves one direction; it never goes backwards.
Terminology
These models are likened to the human brain; some of the terminology closely mirrors the connection with biology.
Each NN is made of nodes (akin to neurons), and are connected (depicted by arrows and akin to synapses)
Some terms in this unit are simply different names for things we’ve learned about previously in the course.
I will draw those connections by calling them what we would have called it in statistics, striking it out, and rename it using the language adopted in the Deep Learning community.
Single Layer Neural Networks
In its simplest form, a single layer neural network has only three layers:
- input layer
- hidden layer
- output layer1
Let’s explore one for modeling a quantitative response using \(p = 4\) predictors.
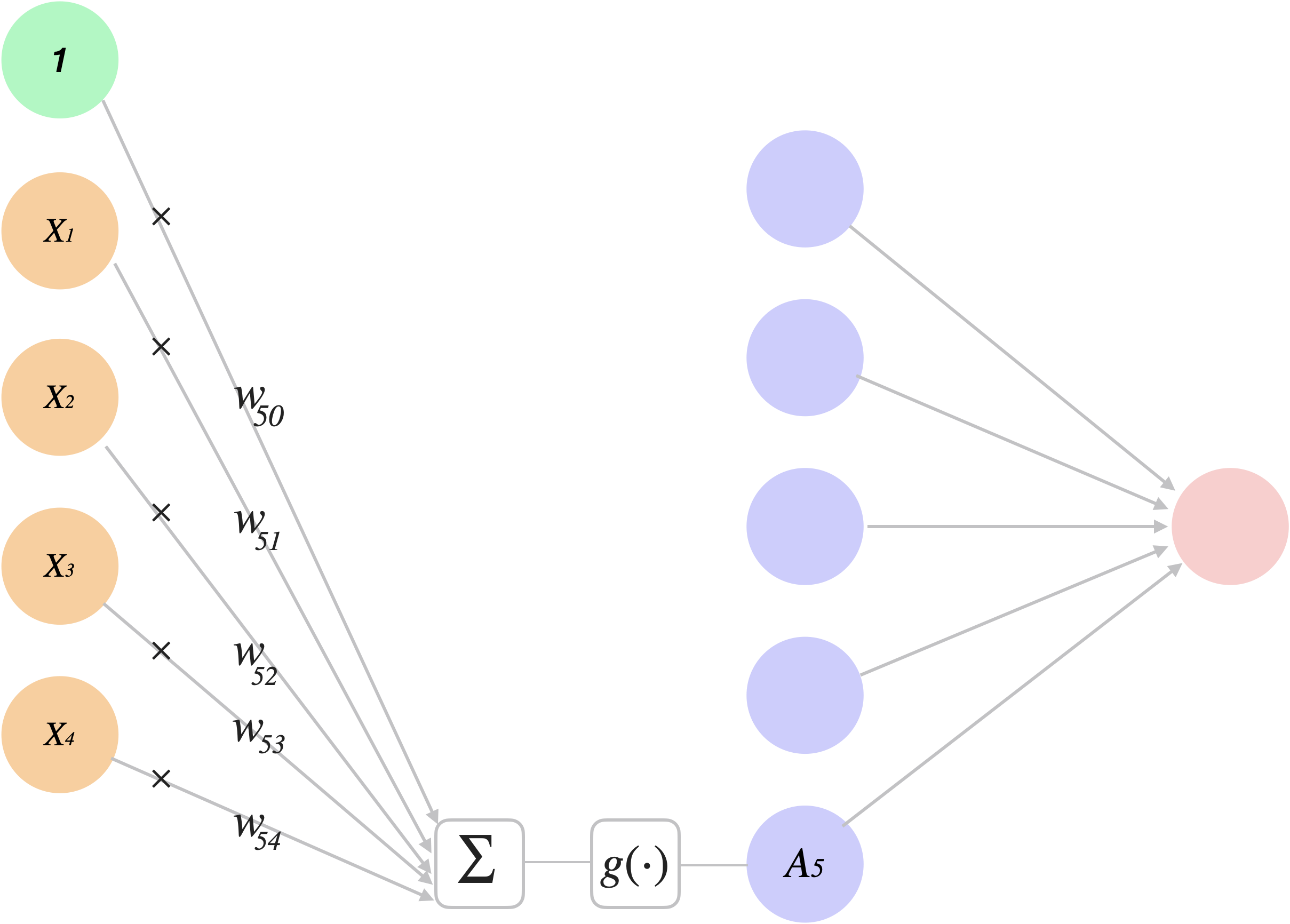
Network Diagram
This “shallow” feed-forward NN has: 4 input nodes, 1 hidden layer (with 5 neurons/nodes/units), and 1 output node.

ISLR Fig 10.1 Neural network with a single hidden layer.
Jump to: Single Hidden Layer Revisited
Single Layer NN
In the terminology of neural networks, the four features \(X_1, \dots ,X_4\) make up the “units” in the input layer
Each arrows feeds into each (\(k = 1, \dots K\)1) of the so-called activations of the hidden layer : \[ A_k = h_k(X) = g(w_{k0} + \sum_{j=1}^p w_{kj}X_j) \] These \(A_k\)s are not directly observed, hence “hidden”.
The Model
The resulting model is then a linear combination in the \(K = 5\) activations:
\[ \begin{align} f(X) &= \beta_0 + \beta_1 A_1 + \beta_2 A_2 + \dots + \beta_K A_K\\ &= \beta_0 + \sum_{k=1}^K \beta_k h_k(X)\\ &= \beta_0 + \sum_{k=1}^K \beta_k g(w_{k0} + \sum_{j=1}^p w_{kj}X_j) \\ \end{align} \]
\(g(z)\) is typically a non-linear function (see activation functions) of \(z\), a linear combination of the inputs.
Activation Functions
\(g(z)\) is called the activation function
Sigmoid
In the early instances of neural networks, the sigmoid activation function was favoured:
\[ g(z) = \frac{e^z}{1+e^z} \]
Recall:
- the sigmoid function forms an S-shaped graph
- this was used in logistic regression to convert values on the real line into probabilities between zero and one
Relu
The preferred1 choice in modern neural networks is the ReLU (rectified linear unit) activation function, which takes the form
\[ g(z) = \text{max}(0,z) = \begin{cases} 0 & \text{if }z<p\\ z & \text{otherwise} \end{cases} \]
Although it thresholds at zero, because we apply it to a linear function the constant term \(w_{k0}\) will shift this inflection point.
Common Activation Functions

Summary of Single Layer NN
In summary, we derive five new features by computing five different linear combinations of \(X\), and then plug each through an activation function \(g(·)\) to transform it. The final model is linear in these derived variables and has the following parameters …





Comment
All hidden layers typically use the same activation function.
The output layer will typically use a different activation function from the hidden layers.
The \(w_{kj}\)s are the
coefficientsweights and \(w_{k0}\)s are theinterceptsbiases1This is a “feed-forward neural network” - there are more complicated types of NN (e.g. backwards arrows, loops, no arrows)
Output Layer
Common choices for activations functions for the output layer:
- Linear (aka “identity”)
- multiplication by 1, i.e. no activation.
- Sigmoid (aka “logistic”)
-
Softmax (for multi-class)
- normalized exponential function which converts a vector of \(K\) real numbers into a probability distribution of \(K\) possible outcomes
Loss Function
In the regression1 setting, for example, the model is fit by minimizing the familiar residual sum of squares:
\[ \mathcal{L} = \sum_{i=1}^n (y_i - f(x_i))^2 \]
This is commonly referred to as a loss function (or cost function, or objective function).2
Why Non-linear Activation Functions?
The nonlinearity in the activation function \(g(·)\) is essential
Without it the model \(f(X)\) would collapse into a simple linear model in \(X_1,...,X_p\).
Moreover, having a nonlinear activation function allows us to capture complex nonlinearities and interaction effects.
Let’s look at an example where the sum of two nonlinear transformations of linear functions can give us an interaction …
Example: Single Layer NN
Suppose we have two input variables \(X = (X_1, X_2)\), i.e. \(p=2\). In our hidden layer suppose we have two hidden units (i.e \(K=2\)) with activation function equal to \(g(z) = z^2\)
Suppose we have parameters: \[\begin{align*} \beta_0 &= 0, & \beta_1 &= \frac{1}{4} & \beta_2 &= - \frac{1}{4}\\ w_{10} &= 0, & w_{11} &=1 & w_{12} &= 1, \\ w_{20} &= 0, & w_{21} &=1 & w_{22} &= -1, \\ \end{align*}\]
Example (activations)
The two activations in the hidden layer and then computed \[\begin{align*} A_k = h_k(X) &= g (w_{k0} + \sum_{j=1}^p w_{kj}X_j)\\ \end{align*}\]
\[ \begin{align*} A_1 &= h_1(X) \\ &= g (w_{10} + w_{11}X_1 + w_{12}X_2)\\ &= g (0 + 1\cdot X_1 + 1 \cdot X_2)\\ &= (X_1 + X_2)^2 \end{align*} \]
\[ \begin{align*} A_2 &= h_2(X)\\ &= g (w_{20} + w_{21}X_1 + w_{22}X_2)\\ &= g(0 + 1 \cdot X_1 + (-1) \cdot X_2)\\ &= (X_1 - X_2)^2 \end{align*} \]
Example (model)
Plugging \(h_1(X) = (X_1 + X_2)^2\) and \(h_2(X) =(X_1 - X_2)^2\) into the neural network model:
\[\begin{align*}
f(X)
&= \beta_0 + \sum_{k=1}^K \beta_k h_k(X) = \beta_0 + \beta_1 h_1(X) + \beta_2 h_2(X)\\
&= 0 + \frac{1}{4}(X_1 + X_2)^2 - \frac{1}{4} (X_1 - X_2)^2\\
&= \frac{1}{4}\left[ X_1^2 + 2\cdot X_1 X_2 + X_2^2 - (X_1^2 - 2 \cdot X_1 X_2 + X_2^2)\right] \\
&= X_1X_2
\end{align*}\]
Multilayer Neural Networks
In theory1 a single hidden layer with a large number of units has the ability to approximate most functions.
However, the learning task of discovering a good solution is made much easier with multiple layers each of modest size.
The weights \(w\) are parameters that require estimation. The quantity of these gets out of hand quickly.
The adjective “deep” in deep learning refers to the use of multiple layers in the network.
Digit Recognition Example
Digit recognition problems were the catalyst that accelerated the development of neural network technology in the late 1980s at AT&T Bell Laboratories and elsewhere
Turns out that these pattern recognition (that are relatively simple for humans) are not so simple for machines.
It has taken more than 30 years to refine the neural-network architectures to match human performance.
Digit Dataset
The textbook goes through the process of setting up a large dense network on the famous and publicly available
MNISThandwritten digit dataset (60K training, 10K testing)The idea is to build a model to classify the images into their correct digit class 0–9.
Every image has \(p = 28 × 28 = 784\) pixels, each of which is an eight-bit grayscale value between 0 and 255 representing the brightness of a pixel (0 = black, 255 = white):
![]()
Example images


Two-Layer Feed-forward NN

ISLR Fig 10.4. Neural network diagram suitable for the MNIST handwritten-digit problem. The input layer has \(p\) = 784 units, the two hidden layers having \(K_1 = 256\) and \(K_2 = 128\) units respectively, and 10 output layer units. Along with intercepts (AKA biases) this network has 235,146 parameters (aka weights).
First Hidden Layer
The first hidden layer takes a linear combination 784 inputs stored in \(X\) as inputs for the activation function. For \(k = 1, \dots, K_1 = 256\) we have: \[\begin{align*} &A_k^{(1)} = h^{(1)}_k(X) = g (w^{(1)}_{k0} + \sum_{j=1}^{p = 784} w^{(1)}_{kj}X_j) \end{align*}\]
- \(W_1\) is the 785 \(\times\) 256 matrix of weights that feed from the input layer to hidden layer one (L1),
- i.e. \(W_1 = \{w_{kj}^{(1)}\}\), \(j =\) 0, 1, \(\dots p\), and \(k=1, \dots, K_1\)
Second Hidden Layer
The second hidden layer takes a linear combination of the activations \(A_k^{(1)}\) from the first hidden layer as inputs for the activation function. For \(\ell = 1, \dots, K_2= 128\) we have: \[\begin{align*} &A^{(2)}_\ell= h^{(2)}_\ell(A_k^{(1)})= g (w^{(2)}_{\ell 0} + \sum_{k=1}^{K_1=256} w^{(2)}_{ \ell k}A_k^{(1)}) \end{align*}\]
- \(W_2\) is the \(25\textbf{7}\times 128\) matrix of weights that feed from the first hidden layer (L1) to the second hidden layer (L2),
- i.e. \(W_2 = \{w_{\ell k}^{(2)}\}\), with \(k=\textbf{0}, \dots, K_1\) and \(\ell = 1,\dots K_2\)
Output Layer
The output layer takes a linear combination of these activations \(A_\ell^{(2)}\) from the second hidden layer as inputs and for output activation function. For \(m = 0, \dots, 9\): \[\begin{align*} f_m(A_\ell^{(2)}) &= f_m \left( \beta_{m0} + \sum_{\ell=1}^{K_2 = 128} \beta_{m\ell} A_\ell^{(2)} \right) \end{align*}\]
\(B\) is the \(12\textbf{9} \times 10\) matrix of weights that feed from the second hidden layer (L2) to output layer,
i.e. \(B = \{ \beta_{m \ell} \}\) with \(\ell = \textbf{0},\dots K_2\), and \(m=0, \dots, 9\)
Softmax
As stated previously, the output layer typically use a different activation function from the hidden layers
The output activation function used here is the softmax function which returns probabilities i.e. \(\sum_{m=0}^9 f_m(X) = 1\): \[\begin{equation} f_m(X) = \text{P}(Y=m \mid X) = \frac{e^{Z_m}}{\sum_{\ell=0}^9 e^{Z_{\ell}}} \end{equation}\] where \(Z_m = \beta_{m0} + \sum_{\ell=1}^{K_2} \beta_{m\ell}A_\ell^{(2)}\). We assign the image to the class with the highest probability.
Cross-entropy
We fit the model by minimizing the negative multinomial log-likelihood, or cross-entropy1:
\[ \mathcal{C} = \begin{equation} - \sum_{i=1}^n \sum_{m=0}^9 y_{im} \log (f_m(x_i)) \end{equation} \]
where \(y_{im}\) is 1 if the true class for observation \(i\) is \(m\), else 0. These classes are said to be one-hot encoded2
Dummy variables One-hot encoding
Like the regression model, NN will require that our categorical data be converted to numeric form.
When no ordinal relationship exists we use one-hot encoding which encodes \(N\) categories using binary (aka dummy) variables
| Original | red.dummy | green.dummy | blue.dummy |
|---|---|---|---|
| red | 1 | 0 | 0 |
| green | 0 | 1 | 0 |
| blue | 0 | 0 | 1 |
Number of Parameters Weights
- This model has 235,146 parameters (referred to as weights):
- \(W_1\) has \(785×256 = 200,960\) weights1
- \(W_2\) has \(257 × 128 = 32,896\) weights\(^1\)
- \(B\) has \(129×10 = 1290\) weights\(^1\).
Note that we have close to 4 times as many parameters as we do training observations (60k).
What should we be concerned about?
Overfitting
One of the most important aspects when training neural networks is avoiding overfitting.
To avoid overfitting, some regularization is needed.
As in our regression unit, regularization will be achieved by adding a
penalty termregularization term to our loss function in order to penalize complexity.This will effectively shrink (or remove) certain weights thereby making some hidden neurons negligible and reducing the overall complexity of the NN.
Regularization
Two popular regularization techniques are:
- L1 regularization (aka LASSO regularization)
- L2 regularization (aka Ridge regularization)
As you may be able to guess, L1 regularization forces the weights to become (exactly) zero and L2 regularization forces the weights towards (but never exactly) zero.
L1/L2 Regularization
L2/Ridge regularization uses the L2 norm \(|| W ||_2^2\) in it’s regularization term1 and adds it to the loss function: \[ \mathcal{L} + \frac{\alpha}{2}|| W ||_2^2 \]
L1/LASSO regularization uses the L1 norm \(|| W ||_1\) in it’s regularization term\(^1\) and adds it to the loss function: \[ \mathcal{L} + \alpha|| W ||_1 \]
Dropout
Another powerful option is dropout regularization.

Figure source: DeepLearning.AI YouTube video
Simply put, we created a smaller network by removing nodes according to some probability (in this case \(p =0.5\)).
Results
| Method | Test Error |
|---|---|
| Neural Network + Ridge Regularization | 2.3% |
| Neural Network + Dropout Regularization | 1.8% |
| Multinomial Logistic Regression | 7.2% |
| Linear Discriminant Analysis | 12.7% |
This is a historic example that marks one of the early “wins” for neural networks in the 1990s.
Training NN
Once the structure is determined, we’re left with a non-linear optimization problem.
Typically, NNs are trained using the stochastic gradient descent and weights are updated using the backpropagation.
We will give a brief overview using the loss function for regression but these ideas can be extended to classification and to when Regularization penalties are applied.
Single Hidden Layer Revisited
Lets return to the Single Hidden Layer example used in our first network diagram.
In this model the parameters are \(\beta = (\beta_0, \beta_1. \beta_K)\), as well as each of the \(w_k = (w_{k0}, w_{k1,}...,w_{kp})\), for \(k = 1, . . . , K\).
Given observations \((x_i, y_i)\), for \(i = 1, \dots, n\) we could fit the model by minmizing the loss function with respect to the parameters, \(\beta\), and \(W\).
Why we need Gradient Decent
While this might look like the minimization problem we had in linear regression, the following is not straightforward to minimize. \[ \mathcal{L}(\beta, W) = \sum_{i=1}^n (y_i - f(x_i))^2 \]
Furthermore, this problem is nonconvex in the parameters, and hence there are multiple solutions.

Gradient Descent
At the basic level, we adjust the weights so that error is reduced for the next iteration.
More technically, the optimization algorithm is navigating down the gradient (or slope) of error and seeks to change each weight proportionally to its effect on the RSS: \[\begin{equation} \Delta w_{\cdots} = - \alpha \frac{ d RSS}{d w_{ \cdots}} \end{equation}\] where \(\alpha\) is a learning rate.
Gradient Descent Algorithm
- Take the derivative of the loss function for each parameter (i.e. find the gradient for the loss function)
- Pick random values for parameters
- Plug in the parameters values into the derivatives (i.e. gradient)
- Calculate \(\text{Step Size} = - \alpha \frac{ d RSS}{d w_{ \cdots}}\)1
- Update: New Parameters = New Parameters + Step Size
Non-convexity

ISLR Fig 10.7: Illustration of gradient descent for one-dimensional \(\theta\). The objective function \(R(\theta)\) is not convex, and has two minima, one at \(\theta = -0.46\) (local), the other at \(\theta = 1.02\) (global). Starting at some value \(\theta_0\) (typically randomly chosen), each step in θ moves downhill — against the gradient — until it cannot go down any further. Here gradient descent reached the global minimum in 7 steps.
Learning Rate
The learning rate is akin to that which we saw in Boosting.
Essentially it is included so that the alorithm “learns slow” and avoids overfitting.
Typically this value is very small (say ~0.1)
The algorithm will be highly dependent on this value and often it’s set to “schedule” that starts off large and gets smaller and smaller.
Backpropagation
Geoffrey Hinton, David Rumelhart and Ronald J. Williams pioneered the back-propagation algorithm in a pair of landmark papers published in 1986.
As a very briefoverview, we work out way through the NN backwards (hence the name), and computes the gradient
stochastic gradient descent, is then used to perform learning using this gradient.
Visualization of Backpropigation

Epoch in NN
An epoch is completed each time the algorithm sees the all the samples in the dataset in a cycle (i.e. a forward pass and a backward pass).
An epoch is made up of one or more batches (or mini-batches), where we use a part of the dataset to train the neural network.
An iteration is completed each time a batch of data passed through the algorithm (i.e. a forward pass and backward pass).
Batches in NN
For each epoch, the required number of iterations times the batch size gives the number of data points.

Network Tuning
Fitting NN requires a number of choices that all have an effect on the performance:
The number of hidden layers, and the number of units (or nodes) per layer.
Regularization technique/ tuning parameters
Details of stochastic gradient descent
choice of activation functions
These choices can make a big difference. The tinkering process can be tedious, and can result in overfitting if done carelessly.
TensorFlow Playground
- You can play around with this in the TensorFlow Playground
NN in R
- One popular way of fitting Neural Networks in R is to use the keras package1
![]()
It can be a bit finicky to install our your computer but you follow this instructions from the textbooks website here
This package interfaces to the tensorflow package which in turn links to efficient python code.
For this course, we’ll just stick to the neuralnet and NeuralNetTools packages for our simple demonstrations.
Example: Body NN
- We fit a neural network with one hidden layer, four hidden layer nodes (or neurons/units) to predict recorded Gender.
We call to another package to produce a plot for it …
Plotting the NN

Properties of the Network Digaram
For NeuralNetTools package, positive weights show up as black, negative as grey.
Also the biases are shown as a separate node (B1 and B2) on the graph; for simpler NN, the weights would be shown on the lines connecting the nodes.
In this case, the magnitude of the weight shows up as the thickness of the line.
There are 25 (24 predictors + 1 bias term) x 4 (hidden layer units) + 5 (hidden layer units + 1 bias term) x 1 (output layer unit) = 105 weights
Example: Body NN
- How does it perform??
- 0 misclassifications!
But of course, this is on the training set, so let’s do a training/testing set to approximate the long-run error.
Validation Approach with Body NN
- Set up a quick training and testing set. Sample approx half the data for a 50-50 training/testing scenario, refit 4 hidden variable NN to the training set, and predict on the test set…
6 misclassifications and misclassification rate of 0.023622
Example: Body NN
How does that compare to some of our other methods?
RF on same train/test? Misclassify 21. Rate closer to 8%. NN wins that battle.
LDA on same train/test? Misclassify 6. Rate closer to 2%. And it’s a much simpler model for interpretation.
So, be careful. Trendy, flexible models are not a cure-all. They need to be carefully tuned and tested.
Taking it further
Different types of data call for different variations. For example
- ISLR2 Ch 10.3 - CNN (Convolutional Nueral Networks) are a special family of NN for classifying images and video (see ISLR2 Ch 10.3)
- ISLR2 Ch 10.4 - the bag-of-words model can be used for predicting attributes of documents
- ISLR2 Ch 10.5 - RNN (Recurrent Neural Networks) are used when data are sequential in nature (e.g. time series, documents)
CNN

Summary
Pros
- Powerful predictive tools
- Parellization
- Easily extended to multiple response models
- Can use pre-trained NN
Cons
- Black box (lack of interpretibility)
- Lots of tuning to consider
- High danger of overfitting
- Requires very large training set