Data 311: Machine Learning
Linear Regression
Dr. Irene Vrbik
University of British Columbia Okanagan
Introduction
Today we introduce our first model for the supervised regression problem: linear regression.
Linear regression is a supervised machine learning algorithm used for modeling the relationship between a dependent variable and one or more independent variables by fitting a linear equation to observed data.
The objective of this model is to find the best-fitting line (or hyperplane) that represents the relationship between the dependent and independent variables.
Why Linear Regression
- Linear regression is one of the simplest machine learning algorithms to understand and implement.
- Linear regression serves as a baseline or benchmark model for many machine learning tasks.
- Learning linear regression establishes a common foundation for understanding machine learning concepts. E.g.
- loss functions
- assumptions and diagnostics checks
- regularization
Motivating Example in Advertising
The
Advertisingdata set (csv) consists of the sales of a certain product, along with advertising budgets for the product in: TV, radio, and newspaperIf we establish a link between advertising and sales, we can advise our client to modify their advertising budgets, consequently leading to an indirect increase in sales.
Our goal is to develop an accurate model that can be used to predict sales on the basis of the three media budgets.
Motivating Questions
- Is there an association between advertising and sales ?
- Which media contribute to sales?
- How large is the association between each medium and sales?
- Can we predict
Salesusing these three? - How accurately can we predict future sales?
- Is the relationship linear?
- Is there synergy among the advertising media?
Advertising Plots
Below plots the Sales vs TV, Radio and Newspaper, with a blue simple linear-regression line fit separately to each.

ISLR Fig 2.1
Simple linear regression
We assume that we can write the following model \[Y = \beta_0 + \beta_1 X + \epsilon\]
- \(Y\) is the quantitative response (aka dependent) variable
- \(X\) is the random predictor (aka independent) variable
- \(\beta_0\) is the intercept (unknown)
- \(\beta_1\) is the slope (unknown)
- \(\epsilon\) is the error
For simple linear regression (SLR) we only have a single \(X\).
Assumptions
- Linearity: The relationship between the independent and dependent variables is assumed to be linear.
- Independence of Errors: The errors (residuals) in the model should be independent of each other.
- Homoscedasticity1 : the variance of the residuals is constant across all levels of the predictors.
Notation
For example, \(X\) may represent TV advertising, and \(Y\) may represent sales. Mathematically, we can write this linear relationship as \[\texttt{sales} \approx \beta_0 + \beta_1 \texttt{TV}\]
Here we regress sales onto TV, or more generally, we describe this by saying that we are regressing \(Y\) on \(X\) (or \(Y\) onto \(X\)).
Multiple Linear Regression
We assume that we can write the following model \[\begin{equation} Y = \beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p + \epsilon \end{equation}\]
- \(Y\) is the random, quantitative response variable
- \(X_j\) is the \(j^{th}\) random predictor variable
- \(\beta_0\) is the intercept
- \(\beta_j\) from \(j = 1, \dots p\) are the regression coefficients
- \(\epsilon\) is the error term
For example \(X_1\) may represent TV advertising, \(X_2\) may represent Radio advertising, \(X_3\) may represent Newspaper advertising, and \(Y\) may represent sales. Mathematically, we can write this linear relationship as \[\texttt{sales} \approx \beta_0 + \beta_1 \texttt{TV} + \beta_1 \texttt{Radio} + \beta_e \texttt{Newspaper}\]
Here we regress sales onto the predictors TV, Radio, and Newspaper.
Our SL Model
In terms of our general SL, we have:
\[f(X) = \beta_0 + \beta_1X_1 + \beta_2X_2 + \ldots + \beta_pX_p\]
After a model has been selected, we need a procedure that uses the training data to fit or train the model.
To estimate \(f(X)\), one only needs to estimate the \(p+1\) coefficients \(\beta_0, \beta_1, \ldots, \beta_p\).
We denote the estimate of \(\beta_i\) by \(\hat \beta_i\).
Fitting the Model
The most common approach to fitting the linear regression model is referred to as (ordinary) least square, or OLS.
This least squares technique involves minimizing the sum of the squared vertical distance from each point to the line, or curve.
You can imagine this as wiggling the line about until the sum of the squared vertical distances is minimized.
This minimization can be achieved using some basic calculus.
Fitted SLR model
Given the parameter estimates \(\hat\beta_0\) and \(\hat\beta_1\) we can predict \(y\) using \[\hat y = \hat \beta_0 + \hat \beta_1 x\]
- \(\hat y\) is the estimate of the response variable
- \(x\) is a given predictor variable
- \(\hat \beta_0\) is the estimated intercept
- \(\hat \beta_1\) is the estimated slope
Some important questions
Is at least one of the predictors \(X_1, X_2, \dots, X_p\) useful in predicting the response?
Do all the predictors help to explain \(Y\), or is only a subset of the predictors useful?
How well does the model fit the data?
Given a set of predictor values, what response value should we predict, and how accurate is our prediction?
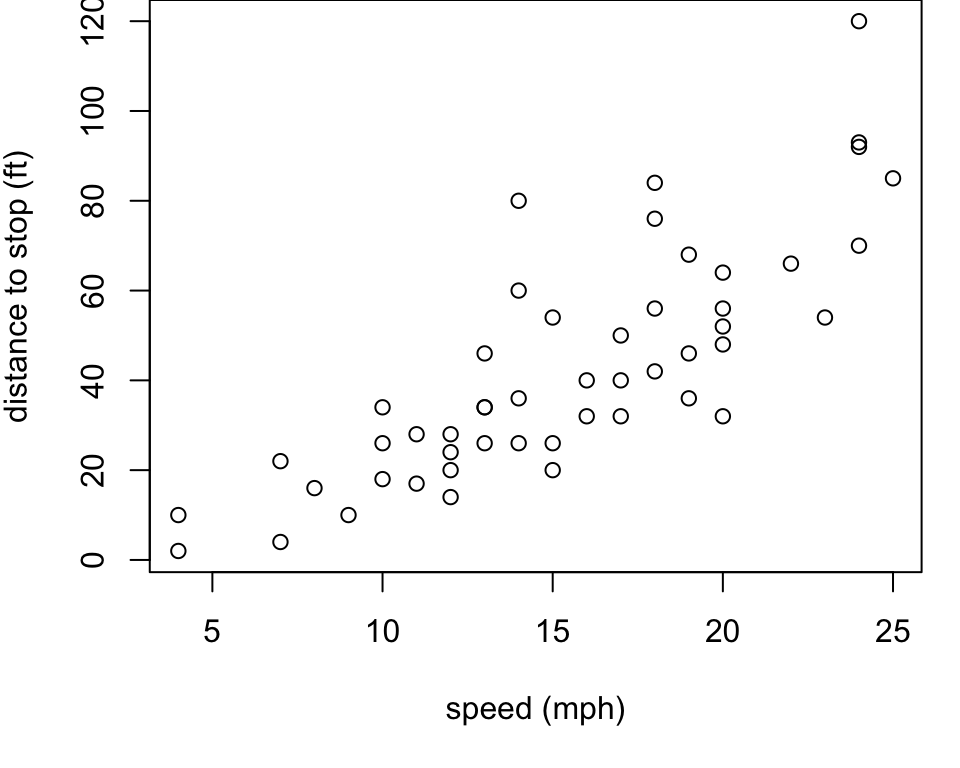
Cars example
Let’s consider the
carsexample from thedatasetspackages (loaded automatically every time you open R)It gives the speed of cars (
speedin mph) and the distances taken to stop (distin ft).As a first step, it is always a good idea to plot the data
Note that the data were recorded in the 1920s.
Cars Plot
General tred the faster the car is going, the longer (in ters of distance) it takes to stop
Goal find the “best” line to model this trend
Residuals
For any line, we can define the observed error as \[e_i = y_i - \hat y_i\] these are more often referred to as residuals.
To find the “best” line, we instead minimize the residual sum of squares RSS = \(\sum_{i=1}^n e_i^2\).
Estimators
Derivations for \(\hat \beta_0\) and \(\hat \beta_1\) are easy with some basic calculus (e.g., you can find the derivation for SLR here).
It turns out that the following equations minimize \(\sum e_i^2\):
Interpreting Parameter Estimates
The estimate of intercept ( \(\hat \beta_0\) ) tells us what value we would guess for \(y\) when \(x=0\).
It is often a large extrapolation1 (and therefore “meaningless”), so be careful with the interpretation.
The estimate for slope ( \(\hat \beta_1\) ) tells us that for each unit increase in the predictor ( \(x\) ) we expect the response ( \(y\) ) to change by the magnitude of slope.
Interpretation for MLR
In MLR we have p predictors; \(X_j\), for \(j = 1, \dots p\)
\(\beta_j\) quantifies the association between the \(j^{th}\) predictor variable and the response.
\(\beta_j\) is the average effect on \(Y\) of a one unit increase in \(X_j\), holding all other predictors fixed
- This interpretation is not very useful in practice as predictors will often change together!
lm() function
We fit a linear model in R using the lm function.
Notice that I
attachthe data set so that the columns in the data frame can be called by name in the lm function.You’ll want to save the output to an object in R to perform the
summary()call and obtain more useful information later.
summary(lm)
Call:
lm(formula = dist ~ speed)
Residuals:
Min 1Q Median 3Q Max
-29.069 -9.525 -2.272 9.215 43.201
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -17.5791 6.7584 -2.601 0.0123 *
speed 3.9324 0.4155 9.464 1.49e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 15.38 on 48 degrees of freedom
Multiple R-squared: 0.6511, Adjusted R-squared: 0.6438
F-statistic: 89.57 on 1 and 48 DF, p-value: 1.49e-12Plot OLS line

Advertising (SLR)

ISLR Fig 3.1: The least squares fit for the regression of sales onto TV. In this case, a linear fit captures the essence of the relationship, although it is somewhat deficient in the left of the plot
3D Visualization

ISLR Fig 3.4: In a three-dimensional setting, with two predictors and one response, the least squares regression line becomes a plane. The plane is chosen to minimize the sum of the squared vertical distances between each observation (shown in red) and the plane.
Assessing the Accuracy of the Coefficient Estimates
The standard error of an estimator reflects how it varies under repeated sampling. We have \[\begin{align*} SE(\hat{\beta}_1)^2 &= \frac{\sigma^2}{\sum_{i=1}^{n}(x_i - \bar{x})^2},\\ SE(\hat{\beta}_0)^2 &= \sigma^2 \left(\frac{1}{n} + \frac{\bar{x}^2}{\sum_{i=1}^{n}(x_i - \bar{x})^2}\right), \end{align*}\] where \(\sigma^2 = \text{Var}(\epsilon)\).
sigma
The \(\sigma\) used in the standard error formula represents the standard deviation of the error terms, ie. \(\sigma^2 = \text{Var}(\epsilon_i)\)
Since \(\sigma\) is generally unknown and is estimated with \[\begin{equation} RSE=\sqrt{\frac{RSS}{n-2}} = \sqrt{\frac{\sum (Y_i-\hat{Y}_i)^2}{n-2}} \end{equation}\]
- This estimate stands for the residual standard error and serves as a measure of the amount of training error in the model (we’ll come back to this later)
Confidence Intervals
- These standard errors can be used to compute confidence intervals.
- A 95% confidence interval is defined as a range of values such that with 95% probability, the range will contain the true unknown value of the parameter.
- It has the form
\[\hat{\beta}_1 \pm 2 \cdot SE(\hat{\beta}_1)\]
Confidence intervals (continued)
That is, there is approximately a 95% chance that the interval
\[[\hat{\beta}_1 - 2 \cdot SE(\hat{\beta}_1), \hat{\beta}_1 + 2 \cdot SE(\hat{\beta}_1)]\]
will contain the true value of \(\beta_1\) (under a scenario where we get repeated samples like the present sample). For the advertising data, the 95% confidence interval for \(\beta_1\) is \[[0.042, 0.053]\]
Confidence interval in R
Advertising <- read.csv("https://www.statlearning.com/s/Advertising.csv")
adlm <- lm(sales~TV, data = Advertising)
sumlm <- summary(adlm)
# Confidence interval for the coefficient of TV
beta_tv <- sumlm$coefficients["TV", c("Estimate", "Std. Error")]
# Calculate the critical value (two-tailed)
alpha <- 0.05
n <- nrow(Advertising)
critical_value <- qt(1 - alpha / 2, df = n - length(adlm$coefficients))
# Calculate the lower and upper bound of the CI
lower_bound <- beta_tv["Estimate"] - critical_value * beta_tv["Std. Error"]
upper_bound <- beta_tv["Estimate"] + critical_value * beta_tv["Std. Error"]
print(c(lower_bound, upper_bound)) Estimate Estimate
0.04223072 0.05284256 Hypothesis Testing
- Standard errors can also be used to perform hypothesis tests on the coefficients.
- The most common hypothesis test involves testing
\[\begin{align}
H_0: & \text{ There is no relationship between $X$ and $Y$ vs. }\\
H_A: & \text{ There is some relationship between $X$ and $Y$}.
\end{align}\]
- Mathematically, this corresponds to testing \(H_0: \beta_1 = 0\) versus \(H_A: \beta_1 \neq 0\), since if \(\beta_1 = 0\), then the model reduces to \(Y = \beta_0\), and \(X\) is not associated with \(Y\).
Hypothesis testing for multiple linear regression
In the multiple regression setting with \(p\) predictors, we need to ask whether all of the regression coefficients are zero, i.e., whether \[\beta_1 = \beta_2 = \ldots = \beta_p = 0.\]
To answer this question we test the null hypothesis, \[\begin{align*} H_0:& \beta_1 = \beta_2 = \ldots = \beta_p = 0 \\ H_a:& \text{at least one } \beta_j \text{ is non-zero} \end{align*}\]
F-test
This hypothesis test is performed by computing the F-statistic where \(F\) follows an \(F\)-distribution with degrees of freedom \(\nu_1 = p\) and \(\nu_2 = n-p-1\)
\[\begin{equation} F = \frac{\text{TSS - RSS}/p}{\text{RSS}/(n - p - 1)} \end{equation}\]If there is no relationship between the response and predictors, the F-statistic will be close to 1. Larger values produce smaller p-values and a higher chance of rejecting \(H_0\).
Measuring Fit
Once we have determined that it is likely that there is a significant relationship between \(X\) and \(Y\), we can ask: how well does the linear model fit the data?
-
You may remember assessing the quality of a linear regression fit using the following methods
- the coefficient of determination, or \(R^2\) statistic (and adjusted \(R^2\) for multiple linear regression)
- the residual standard error (RSE)
R-squared
\[\begin{equation} R^2 = \frac{\text{TSS-RSS}}{\text{TSS}} = 1-\frac{\text{RSS}}{\text{TSS}} = 1- \frac{\sum (y_i - \hat y_i)^2}{\sum (y_i - \bar y)}. \end{equation}\]The coefficient of determination \(R^2\) is the proportion of the total variation that is explained by the regression line.
It measures how close the fitted line is to the observed data.
It is easily to interpret as it always lies between 0 and 1
Adjusted \(R^2\)
Adjusted \(R^2\) is produced in R output and calculated by:
\[ R^2 = 1 - \dfrac{\dfrac{RSS}{n-p-1}}{\dfrac{TSS}{n-1}} \]
- This metric penalizes for over-parameterization1
- Goodness of fit measure (bigger = better)
RSE
RSE is calculated as follows:
\[\begin{equation} RSE = \sqrt{\frac{1}{n - p - 1} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2}\end{equation}\]where \(n\) is the number of data points, \(p\) is the number of predictors (features), \(y_i\) is the observed value, and \(\hat y_i\) is the predicted value for the \(i^{th}\) data point.
RSE (continued)
RSE is primarily used in the context of linear regression.
It quantifies the typical or average magnitude of the residuals (the differences between observed and predicted values) in the model.
RSE is essentially the standard deviation of the residuals \(\left(\sqrt{\text{Var}(e_i)}\right)\).
RSE is used to estimate \(\sigma\) the standard error of errors \(\left(\sqrt{\text{Var}(\epsilon)}\right)\)
RSE vs. MSE
Recall our Mean Squared Error (MSE) formula from last lecture:
\[ MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 \]
MSE is a more general metric used in various machine learning and statistical modeling contexts
RSE is essentially a scaled version of MSE.
RSE is a specific metric used in linear regression that adjusts for the number of predictors, whereas MSE is a more general metric used in various predictive modeling tasks.
Example: Life Expectancy (SLR)
Lets consider a data set containing the life expectancy and illiteracy rates (among other measurements) for all 50 states from the 1970’s.
This dataset is available in R as
state.x77in thedatasetspackage (which gets loaded automatically with each new R session), see?state.x77We’ll fit a simple linear regression with life expectancy
Life.Exp1 as the response variable.
Example: Life Expectancy (MLR)
Our response variable is Life.Exp the life expectancy in years (1969–71). Lets consider the predictors:
-
Illiteracy: illiteracy (1970, percent of population) -
Murder: murder and non-negligent manslaughter rate per 100,000 population (1976) -
HS Grad: percent high-school graduates (1970) -
Frost: mean number of days with minimum temperature below freezing (1931–1960) in capital or large city
Scatterplot

SLR in R
Call:
lm(formula = Life.Exp ~ Illiteracy, data = stdata)
Residuals:
Min 1Q Median 3Q Max
-2.7169 -0.8063 -0.0349 0.7674 3.6675
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 72.3949 0.3383 213.973 < 2e-16 ***
Illiteracy -1.2960 0.2570 -5.043 6.97e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.097 on 48 degrees of freedom
Multiple R-squared: 0.3463, Adjusted R-squared: 0.3327
F-statistic: 25.43 on 1 and 48 DF, p-value: 6.969e-06MLR in R
Call:
lm(formula = Life.Exp ~ Illiteracy + Murder + HS.Grad + Frost,
data = stdata)
Residuals:
Min 1Q Median 3Q Max
-1.48906 -0.51040 0.09793 0.55193 1.33480
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 71.519958 1.320487 54.162 < 2e-16 ***
Illiteracy -0.181608 0.327846 -0.554 0.58236
Murder -0.273118 0.041138 -6.639 3.5e-08 ***
HS.Grad 0.044970 0.017759 2.532 0.01490 *
Frost -0.007678 0.002828 -2.715 0.00936 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.7483 on 45 degrees of freedom
Multiple R-squared: 0.7146, Adjusted R-squared: 0.6892
F-statistic: 28.17 on 4 and 45 DF, p-value: 9.547e-12Hypothesis test
- We want to know if our predictors are useful in predicting life expectancy (our response variable
Life.Exp)
- We could first test if any of the predictors under consideration are significant. Namely, we test
- This is conducted using the \(F\)-test…
F test
Call:
lm(formula = Life.Exp ~ Illiteracy + Murder + HS.Grad + Frost,
data = stdata)
Residuals:
Min 1Q Median 3Q Max
-1.48906 -0.51040 0.09793 0.55193 1.33480
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 71.519958 1.320487 54.162 < 2e-16 ***
Illiteracy -0.181608 0.327846 -0.554 0.58236
Murder -0.273118 0.041138 -6.639 3.5e-08 ***
HS.Grad 0.044970 0.017759 2.532 0.01490 *
Frost -0.007678 0.002828 -2.715 0.00936 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.7483 on 45 degrees of freedom
Multiple R-squared: 0.7146, Adjusted R-squared: 0.6892
F-statistic: 28.17 on 4 and 45 DF, p-value: 9.547e-121. Is at least one predictor useful?
For that question, we use the F-statistic and F-test
Since the value is large (28.17) and the p-value is small (9.547e-12) we would reject the null \[H_0: \beta_0 = \beta_1 = \beta_2 = \beta_3\] in favour of the alternative
\[ H_a:\text{ at least one }\beta_j \neq 0. \]
2. Do all the predictors help to explain \(Y\), or is only a subset of the predictors useful?
Each \(\beta_j\) has an associated \(t\)-statistic and \(p\)-value in the R output
These check whether each predictor is linearly related to the response, after adjusting for all the other predictors considered
These are useful, but we have to be careful…especially for large numbers of predictors (multiple testing problem)
Attempt no. 1
A natural temptation when considering all these individualized hypothesis tests is to “toss out” any variable(s) that does not appear significant (ie \(p\)-value > 0.05)
This brings us into the topic of variable selection, which we will go into much more detail later in the course.
As our first foray, we’ll look at the most straightforward (and also oldest) techniques for doing so.
Attempt no. 2
Assuming we now have an appropriate measuring stick (e.g. RSE or \(R^2\)) how do we go about choosing which models to fit?
Ideally we would try every combination of \(X_j\), but that becomes computationally impractical very quickly1
- Instead, we may decided on a systematic approach to perform model selection: …
Variable Selction
Forward Selection: Start with only the intercept (no predictors, ie null model). Create \(p\) simple linear regressions, whichever predictor has the lowest RSS, add it into the model. Continue until, for instance, we see a decrease in our ‘best model’ measurement.
Backward Selection: Start with all predictors. Remove the predictor with the largest p-value. Continue until, for instance, all variables are considered significant.
Mixed Selection: Start with no predictors. Perform forward selection, but if any \(p\)-values for variables currently in the model reach above a threshold, remove that variable. Continue until, for instance, all variables in your model are significant and any additional variable would not be.
Types of Error
We are always going to encounter error by using models.
Because we are estimating the population parameters \(\beta_j\) based on a sample there will always be some variability in our model and inaccuracy related to the reducible error.
Our model will most likely be a simpler approximation to reality hence, we introduce model bias and add to our reducible error
Even if the multiple linear model was exactly \(f\), there would still be irreducible error. That is, our predictions \(\hat y_i \neq y_i\) for most (probabilistically all) \(i\).
3. How well does the model fit the data?
While the
summary()function does not spit out the MSE by default, we can still calculate this value and compre the resulting MSE with the MSE of other fitted models using the same data.That is to say the MSE isn’t so useful on it’s own but more-so as a comparative value across multiple models.
4. Given a set of predictor values, what response value should we predict, and how accurate is our prediction?
We can use the fitted model to make predictions for \(Y\) on the basis of a set of predictors \(X_1, X_2, \dots, X_p\) using functions in R and the fitted \(\hat \beta\)’s
-
To account for the three sorts of uncertainty associated with this prediction we have two methods:
- confidence intervals: reflects the uncertainty around the mean prediction values.
- prediction intervals: reflects the uncertainty around a single value
Prediction a single value
Using the SLR model for the
carsdata, we can predict the stopping distance for a new speed value \(x_0\).Its stopping distance will be determined by \[Y_0 = \beta_0 + \beta_1 x_0 + \epsilon\]
Our prediction for this value would be \(\hat\beta_0 + \hat\beta_1 x_0\)
To assess the variance of this prediction, we must take into account the variance of the \(\hat\beta\)s and \(\epsilon\).
Prediction a mean response
Suppose we are interested in the average stopping distance this 1920s car would incur at a speed of \(x_0\).
Our prediction for this value would be \[\hat y_0 = \hat\beta_0 + \hat\beta_1 x_0\]
To assess the variance of this prediction, we only need to take into account the variance of the \(\hat\beta\)s.
Making Predictions
Prediction intervals are concerned with the value of a new observation \(Y_{0}\) for a given value \(x_0\) of the predictor
Confidence intervals are concerned with the value of the mean response \(E(Y_0) = \mu_{Y_0}\) for a given value \(x_0\) of the predictor
- Prediction intervals are more commonly required as we are often interested in predicting an individual value

Comments on the F-test
Q: Why do we use F-tests instead of looking at the individual p-values associated with each predictor?
Even if all \(\beta_j\)’s = 0, (that is, no variable is truly associated with the response), we would still expect 5% of hypothesis tests for \(\beta_j\) to be rejected by chance alone
The \(F\)-test therefore combats the multiple testing problem.